<目次>
(1) Slack APIで返信を一覧で取得する方法をご紹介(Python)
(1-0) やりたいこと
(1-1) STEP1:Slackアプリの準備
(1-1) STEP2:サンプルプログラム(特定スレッドに対する返信だけを取得)
(1-2) STEP3:サンプルプログラム(チャンネル内の全ての投稿&返信を取得)
(1) Slack APIで返信を一覧で取得する方法をご紹介(Python)
(1-0) やりたいこと
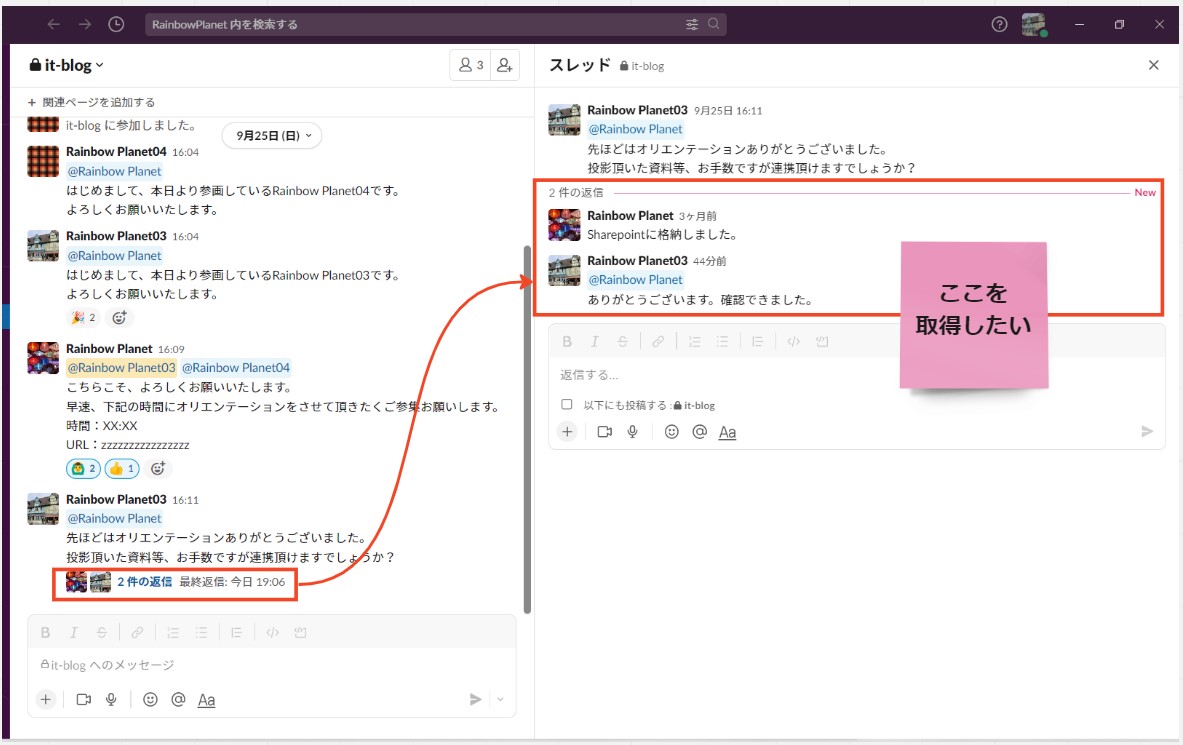
●アウトプットイメージ
Slack APIで、指定したチャンネルの投稿一覧(返信含む)を照会した結果(JSON)を、表形式に整形したのち、csvに出力する。
(図111)
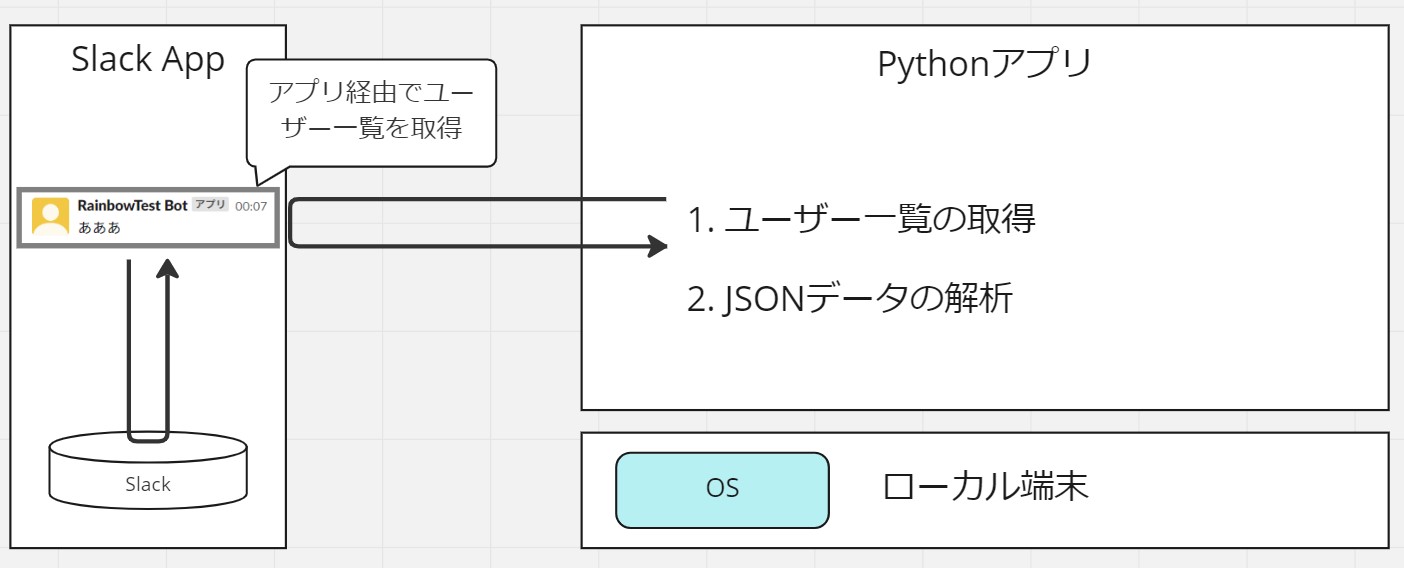
●処理の流れ
Slack Appを作成し、そのApp経由で投稿一覧(返信含む)のAPIを照会します。
(図112)
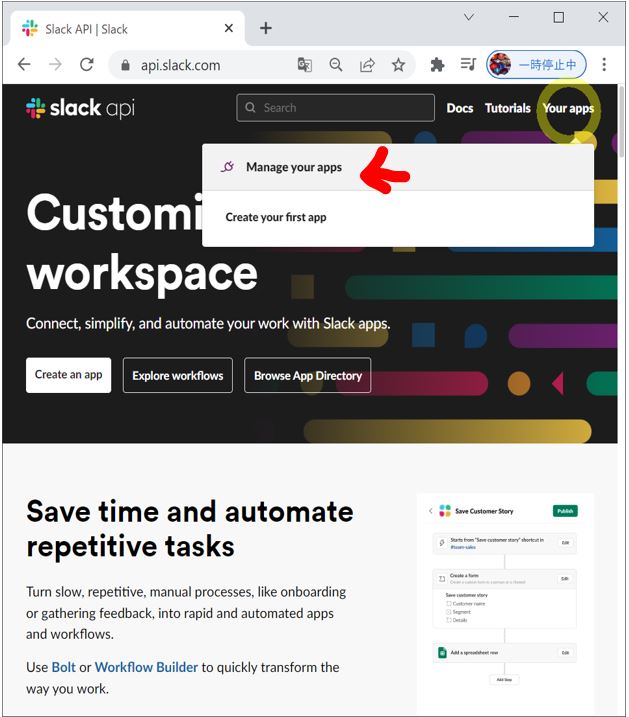
(1-1) STEP1:Slackアプリの準備
APIの処理はSlackボットを経由して行うため、事前にSlackボットを準備しておきます。
(作成手順)
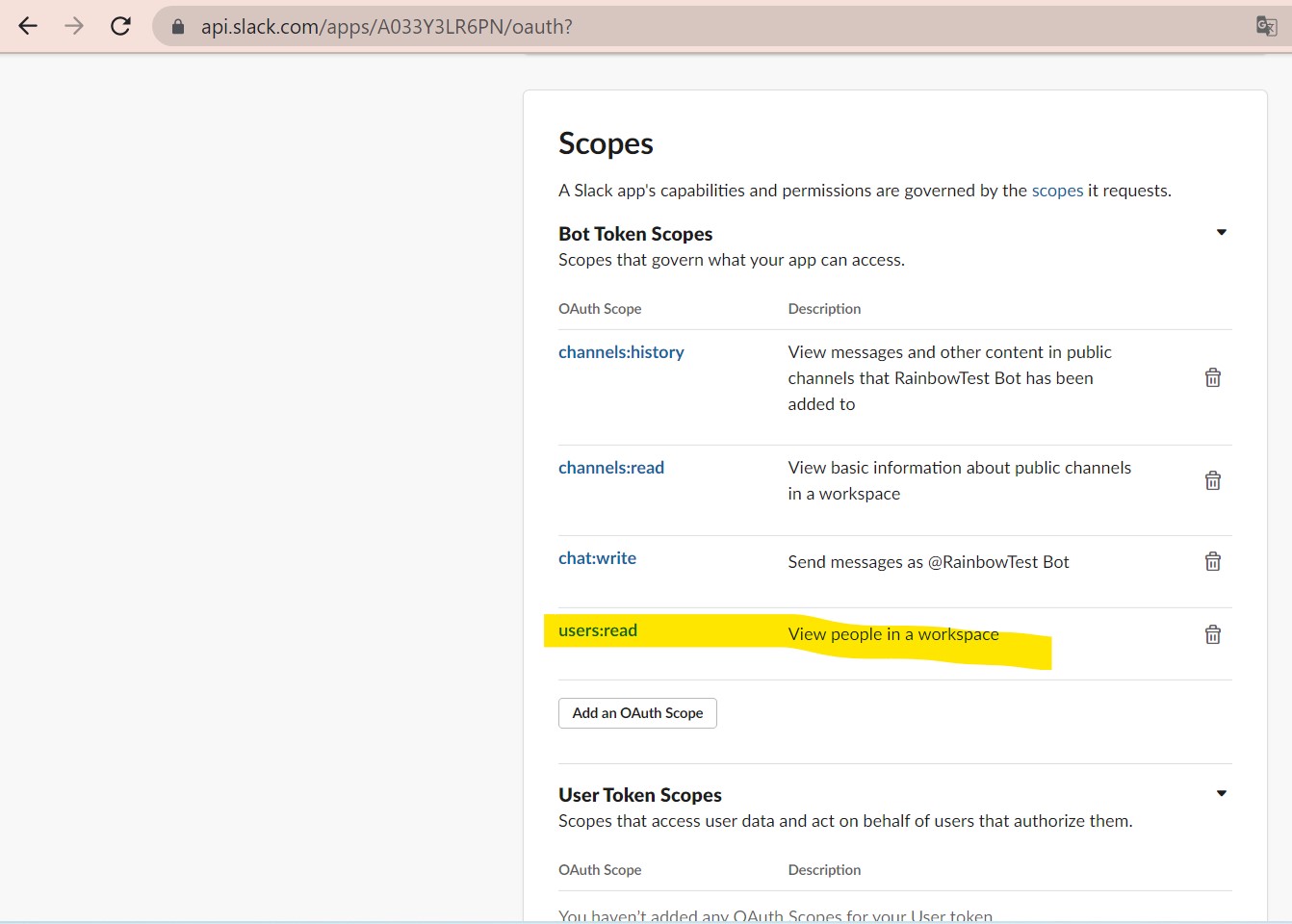
その際、ボットには必要な権限を割り当てておきます。
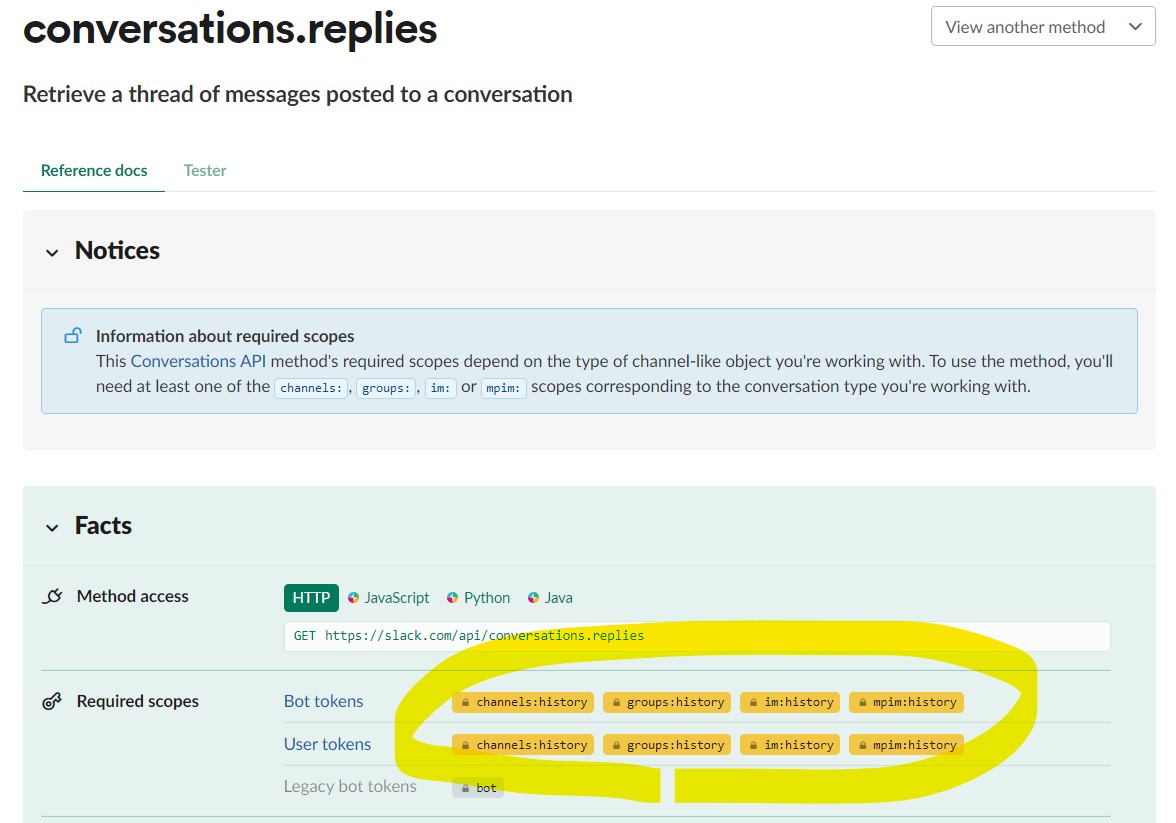
・①必要な権限
channels:history groups:history im:history mpim:history
(図122)
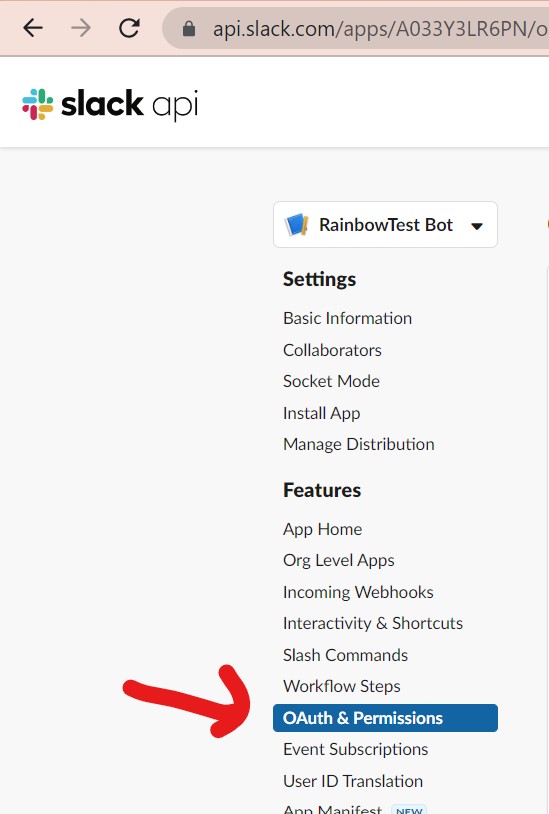
・②OAuth & Permissionsを選択
(図123)
↓
・③割り当て
(図124)
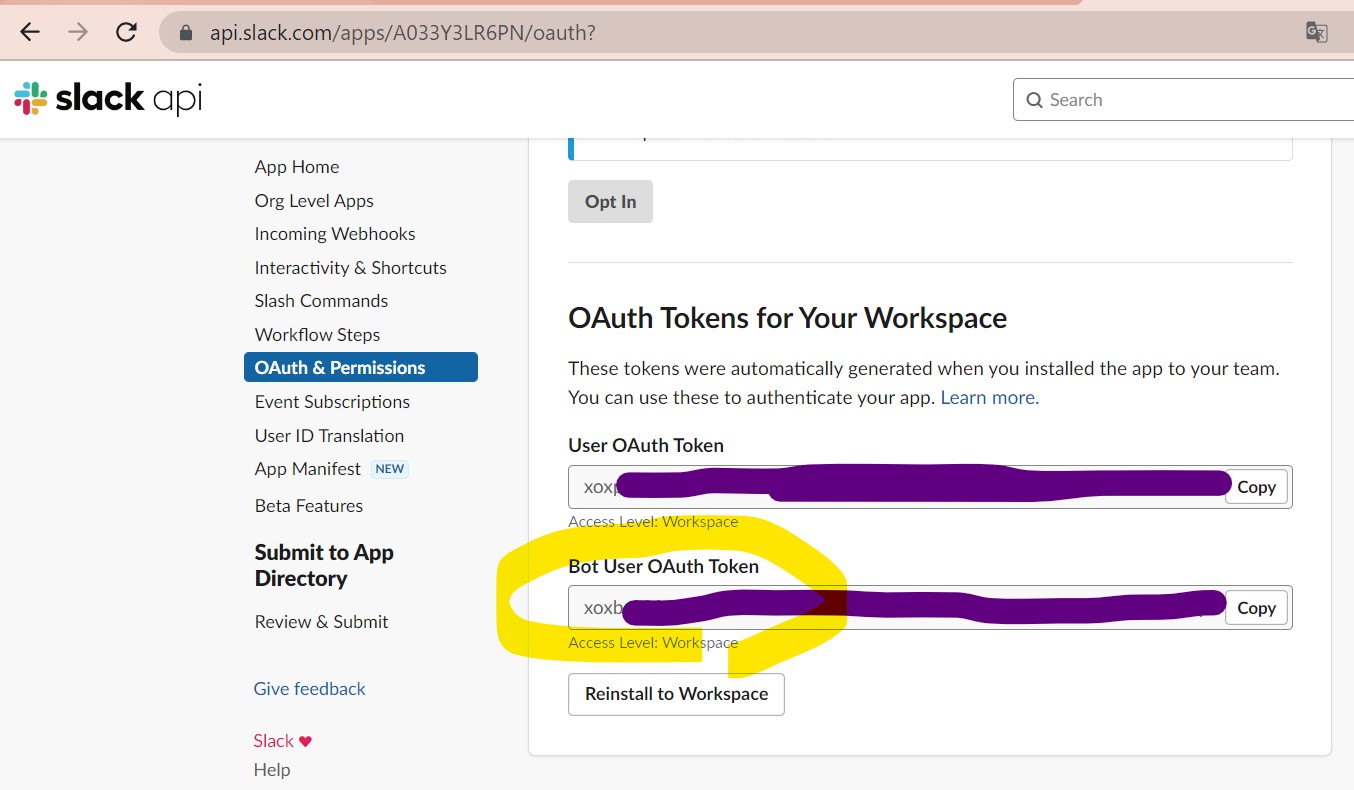
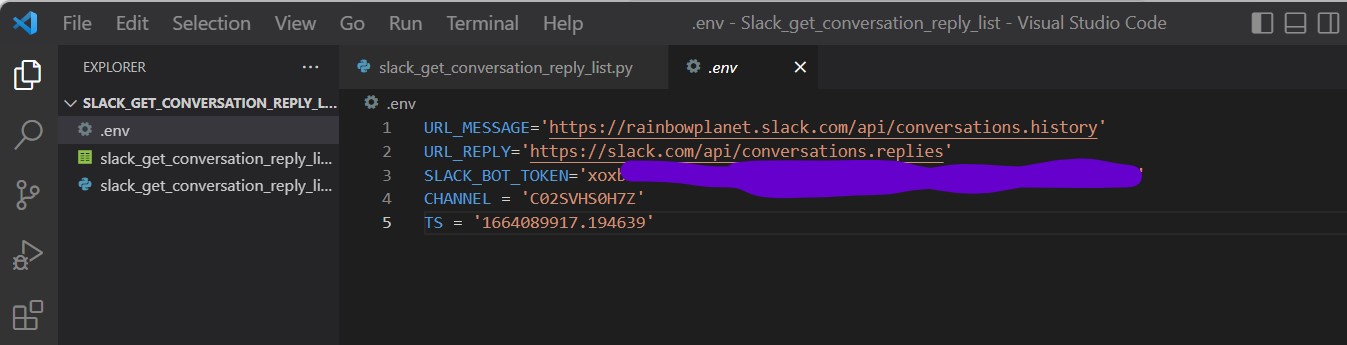
また、Bot User OAuth Tokenはプログラムの中で指定が必要なため、控えておきます。
(図121)
(1-2) STEP2:サンプルプログラム(特定スレッドに対する返信だけを取得)
最初のステップとして、特定スレッドに対する返信だけを取得します。
イメージ図
(図131)
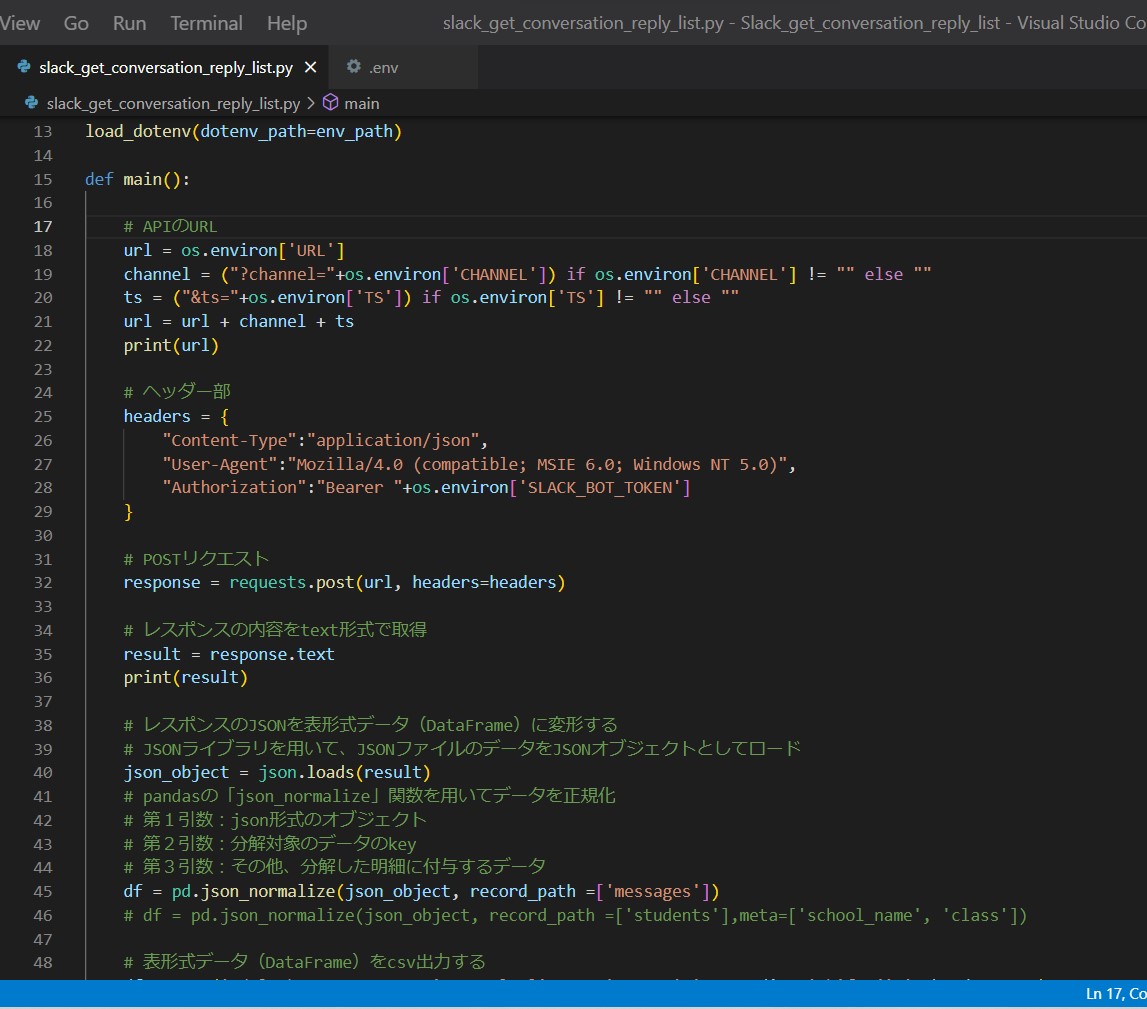
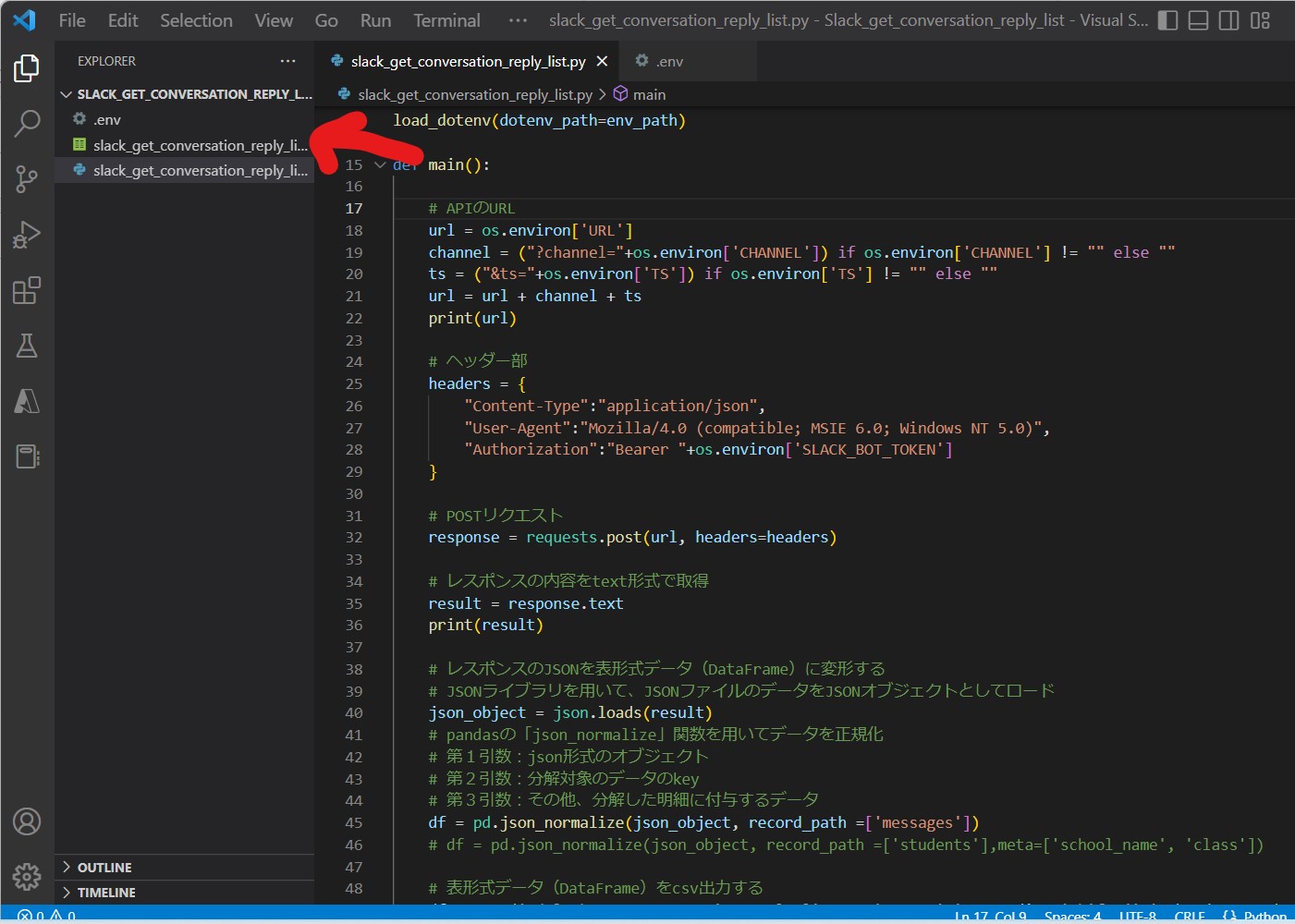
(サンプルプログラム)
slack_get_conversation_reply_list.py
import json
import pandas as pd
import requests
import os
from pathlib import Path
from dotenv import load_dotenv
# 親フォルダパスを取得
file_path = Path(__file__).parent
# 「.env」ファイルのパスを設定
env_path = file_path/'.env'
# 「.env」ファイルのロード
load_dotenv(dotenv_path=env_path)
def main():
# APIのURL
url = os.environ['URL']
# 必須パラメータ:channel、ts
channel = ("?channel="+os.environ['CHANNEL']) if os.environ['CHANNEL'] != "" else ""
ts = ("&ts="+os.environ['TS']) if os.environ['TS'] != "" else ""
url = url + channel + ts
# ヘッダー部
headers = {
"Content-Type":"application/json",
"User-Agent":"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)",
"Authorization":"Bearer "+os.environ['SLACK_BOT_TOKEN']
}
# POSTリクエスト
response = requests.post(url, headers=headers)
# レスポンスの内容をtext形式で取得
result = response.text
# レスポンスのJSONを表形式データ(DataFrame)に変形する
# JSONライブラリを用いて、JSONファイルのデータをJSONオブジェクトとしてロード
json_object = json.loads(result)
# pandasの「json_normalize」関数を用いてデータを正規化
# 第1引数:json形式のオブジェクト
# 第2引数:分解対象のデータのkey
# 第3引数:その他、分解した明細に付与するデータ
df = pd.json_normalize(json_object, record_path =['messages'])
# df = pd.json_normalize(json_object, record_path =['students'],meta=['school_name', 'class'])
# 表形式データ(DataFrame)をcsv出力する
df.to_csv('./slack_get_conversation_reply_list.csv', sep=',', encoding='shift-jis', header=True)
if __name__ == "__main__":
main()
(図132)
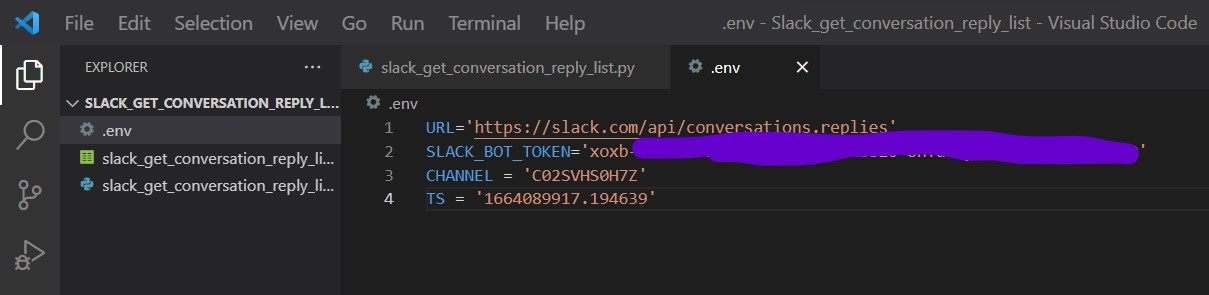
.env(例)
URL='https://slack.com/api/conversations.replies' SLACK_BOT_TOKEN='xoxb-xxxxx' CHANNEL = 'C02SVHS0H7Z' TS = '1664089917.194639'
(図133)
↓
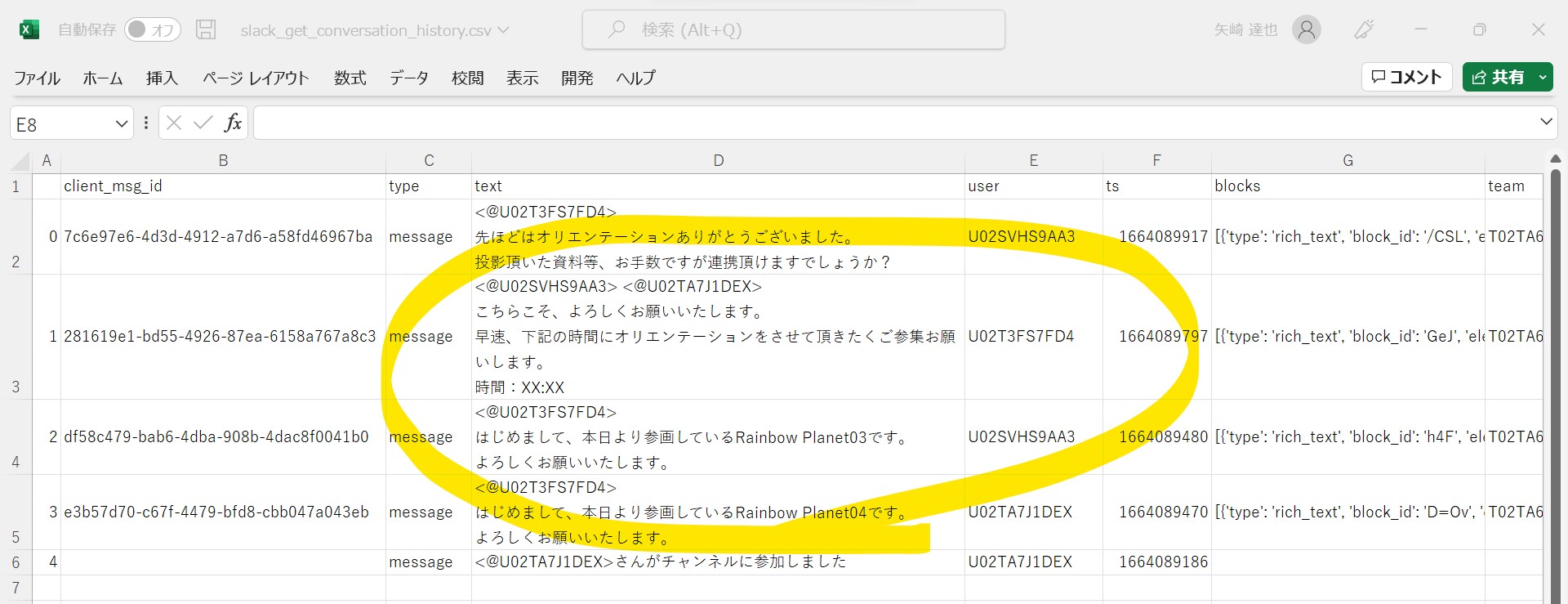
実行するとプログラムと同じ階層に、csvが生成されます。
(図134)
↓
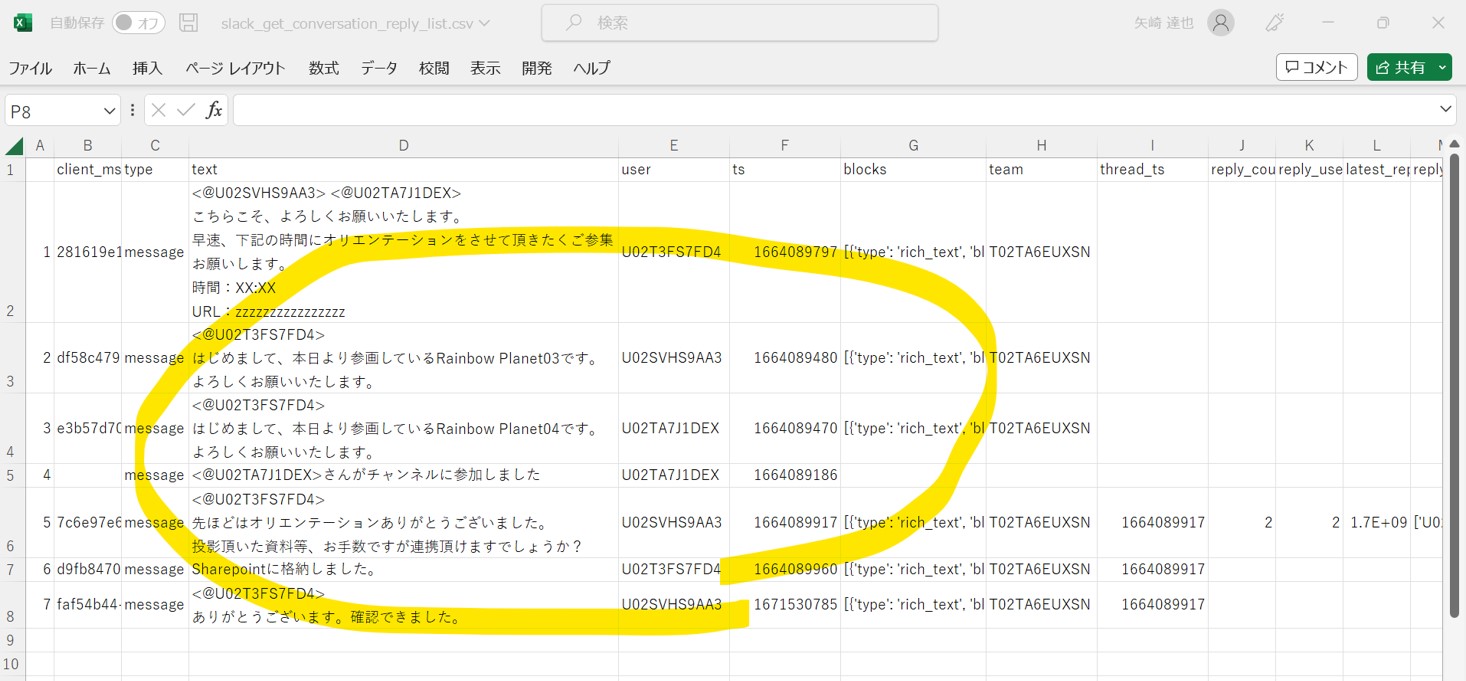
Csvはユーザー単位でデータが出力されています。
(json形式のデータを表形式に整形している)
(図135①)
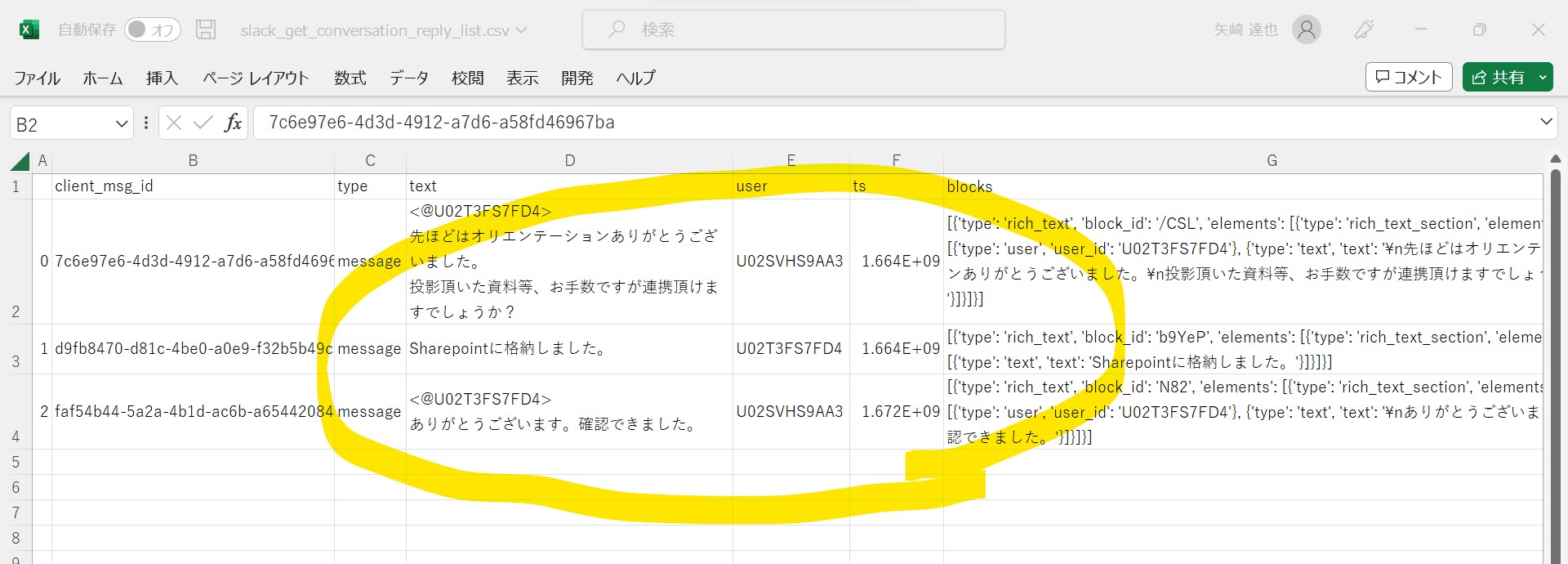
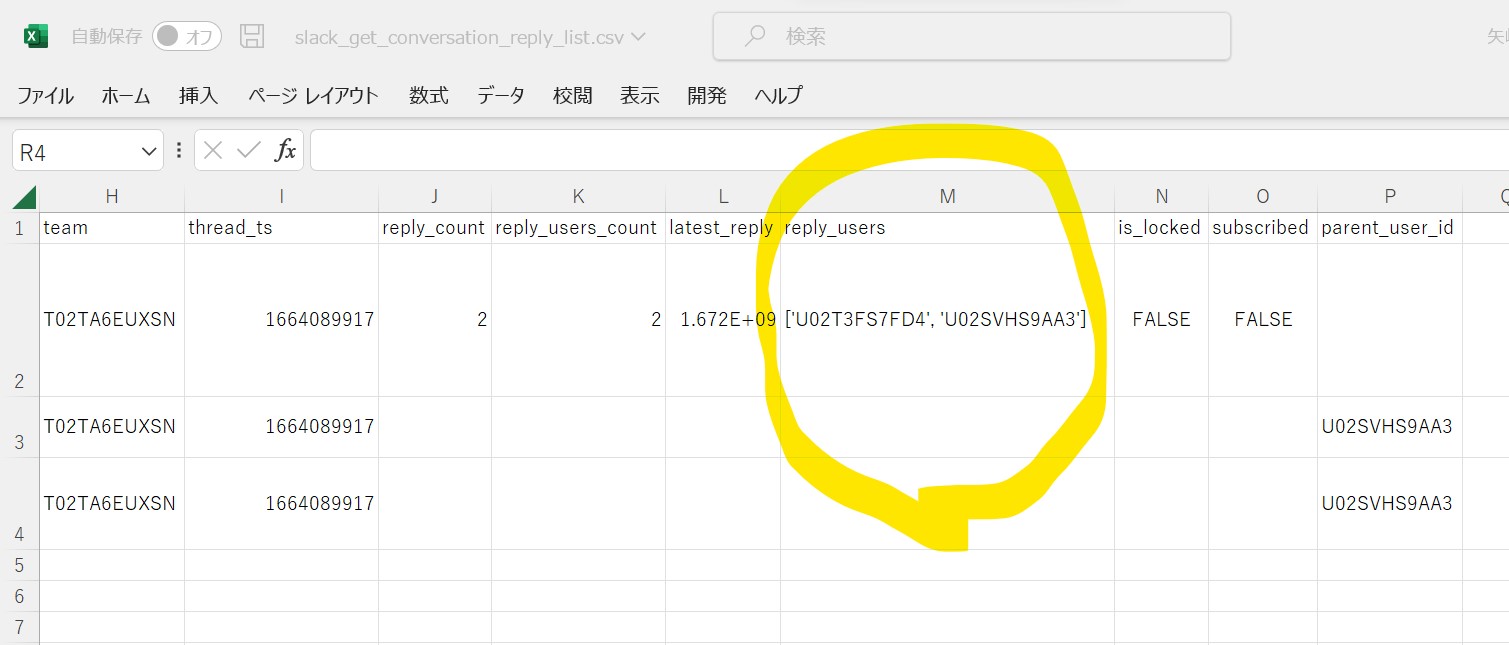
(図135②)
ちなみに、元々のJSON形式のレスポンスはこんな感じです。
ネストになっている「”blocks”: { ・・・ }」や「”reply_users”: { ・・・ }」の部分も、csvの右側に列がちゃんと存在している事が確認できています。
(参考)
{
"ok": true,
"messages": [
{
"client_msg_id": "7c6e97e6-4d3d-4912-a7d6-a58fd46967ba",
"type": "message",
"text": "<@U02T3FS7FD4>\n先ほどはオリエンテーションありがとうございました。\n投影頂いた資料等、お手数ですが連携頂けますでしょうか?",
"user": "U02SVHS9AA3",
"ts": "1664089917.194639",
"blocks": [
{
"type": "rich_text",
"block_id": "/CSL",
"elements": [
{
"type": "rich_text_section",
"elements": [
{
"type": "user",
"user_id": "U02T3FS7FD4"
},
{
"type": "text",
"text": "\n先ほどはオリエンテーションありがとうございました。\n投影頂いた資料等、お手数ですが連携頂けますでしょうか?"
}
]
}
]
}
],
"team": "T02TA6EUXSN",
"thread_ts": "1664089917.194639",
"reply_count": 2,
"reply_users_count": 2,
"latest_reply": "1671530784.605409",
"reply_users": [
"U02T3FS7FD4",
"U02SVHS9AA3"
],
"is_locked": false,
"subscribed": false
},
{
"client_msg_id": "d9fb8470-d81c-4be0-a0e9-f32b5b49c15f",
"type": "message",
"text": "Sharepointに格納しました。",
"user": "U02T3FS7FD4",
"ts": "1664089960.413939",
"blocks": [
{
"type": "rich_text",
"block_id": "b9YeP",
"elements": [
{
"type": "rich_text_section",
"elements": [
{
"type": "text",
"text": "Sharepointに格納しました。"
}
]
}
]
}
],
"team": "T02TA6EUXSN",
"thread_ts": "1664089917.194639",
"parent_user_id": "U02SVHS9AA3"
},
{
"client_msg_id": "faf54b44-5a2a-4b1d-ac6b-a65442084a8f",
"type": "message",
"text": "<@U02T3FS7FD4>\nありがとうございます。確認できました。",
"user": "U02SVHS9AA3",
"ts": "1671530784.605409",
"blocks": [
{
"type": "rich_text",
"block_id": "N82",
"elements": [
{
"type": "rich_text_section",
"elements": [
{
"type": "user",
"user_id": "U02T3FS7FD4"
},
{
"type": "text",
"text": "\nありがとうございます。確認できました。"
}
]
}
]
}
],
"team": "T02TA6EUXSN",
"thread_ts": "1664089917.194639",
"parent_user_id": "U02SVHS9AA3"
}
],
"has_more": false
}
(参考)
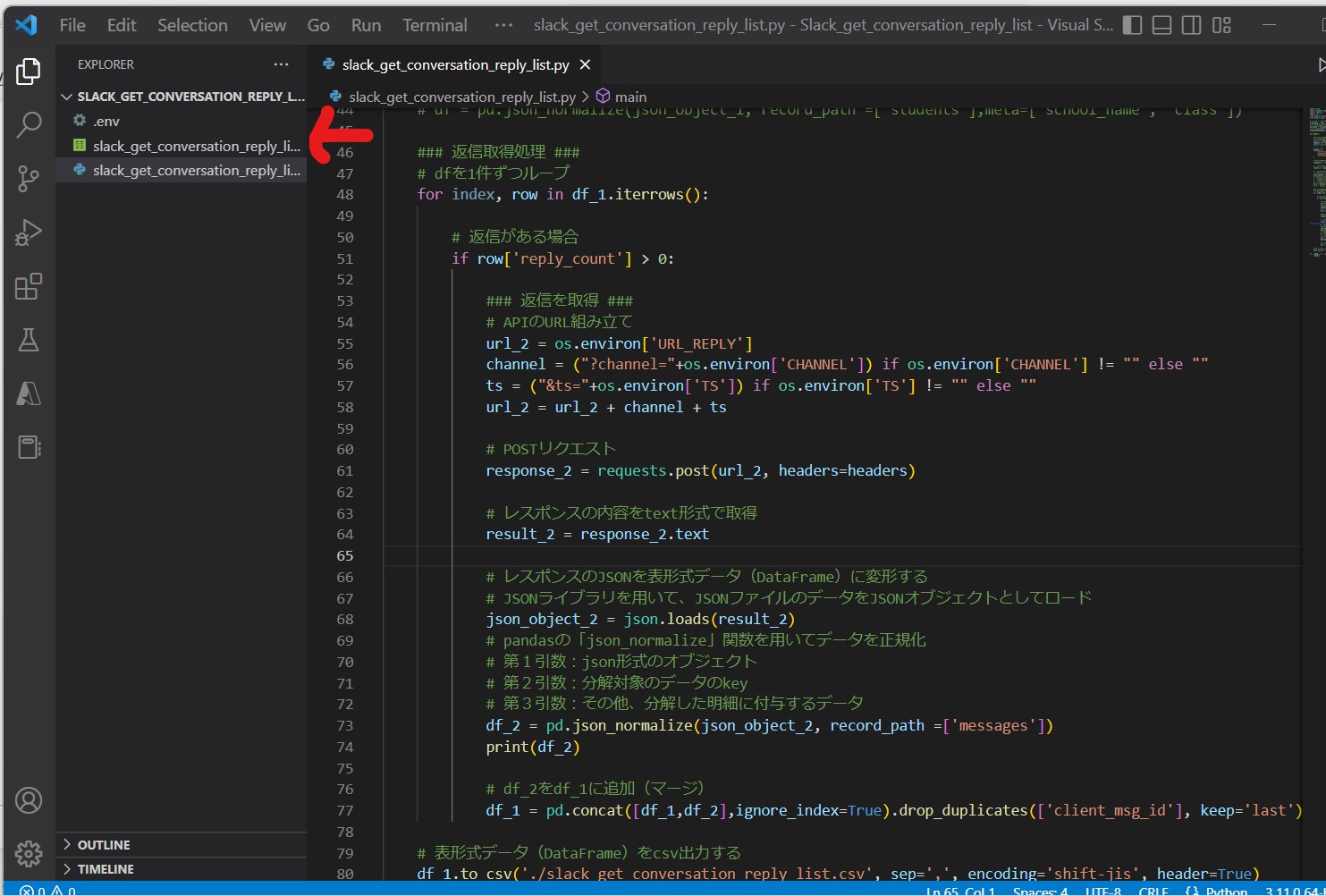
(1-3) STEP3:サンプルプログラム(チャンネル内の全ての投稿&返信を取得)
次に「チャンネル内の全ての投稿&返信」を取得します。
※投稿のみの取得については、コチラの記事にも記載済みで、今回はその発展形です。
イメージ図
(図141)
(サンプルプログラム)
import json
import pandas as pd
import requests
import os
from pathlib import Path
from dotenv import load_dotenv
# 親フォルダパスを取得
file_path = Path(__file__).parent
# 「.env」ファイルのパスを設定
env_path = file_path/'.env'
# 「.env」ファイルのロード
load_dotenv(dotenv_path=env_path)
def main():
### 全投稿を取得 ###
# APIのURL組み立て
url_1 = os.environ['URL_MESSAGE']
channel = ("?channel="+os.environ['CHANNEL']) if os.environ['CHANNEL'] != "" else ""
url_1 = url_1 + channel
# ヘッダー部
headers = {
"Content-Type":"application/json",
"User-Agent":"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)",
"Authorization":"Bearer "+os.environ['SLACK_BOT_TOKEN']
}
# POSTリクエスト
response_1 = requests.post(url_1, headers=headers)
# レスポンスの内容をtext形式で取得
result_1 = response_1.text
# レスポンスのJSONを表形式データ(DataFrame)に変形する
# JSONライブラリを用いて、JSONファイルのデータをJSONオブジェクトとしてロード
json_object_1 = json.loads(result_1)
# pandasの「json_normalize」関数を用いてデータを正規化
# 第1引数:json形式のオブジェクト
# 第2引数:分解対象のデータのkey
# 第3引数:その他、分解した明細に付与するデータ
df_1 = pd.json_normalize(json_object_1, record_path =['messages'])
# df = pd.json_normalize(json_object_1, record_path =['students'],meta=['school_name', 'class'])
### 返信取得処理 ###
# dfを1件ずつループ
for index, row in df_1.iterrows():
# 返信がある場合
if row['reply_count'] > 0:
### 返信を取得 ###
# APIのURL組み立て
url_2 = os.environ['URL_REPLY']
channel = ("?channel="+os.environ['CHANNEL']) if os.environ['CHANNEL'] != "" else ""
ts = ("&ts="+os.environ['TS']) if os.environ['TS'] != "" else ""
url_2 = url_2 + channel + ts
# POSTリクエスト
response_2 = requests.post(url_2, headers=headers)
# レスポンスの内容をtext形式で取得
result_2 = response_2.text
# レスポンスのJSONを表形式データ(DataFrame)に変形する
# JSONライブラリを用いて、JSONファイルのデータをJSONオブジェクトとしてロード
json_object_2 = json.loads(result_2)
# pandasの「json_normalize」関数を用いてデータを正規化
# 第1引数:json形式のオブジェクト
# 第2引数:分解対象のデータのkey
# 第3引数:その他、分解した明細に付与するデータ
df_2 = pd.json_normalize(json_object_2, record_path =['messages'])
print(df_2)
# df_2をdf_1に追加(マージ)
df_1 = pd.concat([df_1,df_2],ignore_index=True).drop_duplicates(['client_msg_id'], keep='last')
# 表形式データ(DataFrame)をcsv出力する
df_1.to_csv('./slack_get_conversation_reply_list.csv', sep=',', encoding='shift-jis', header=True)
if __name__ == "__main__":
main()
(図142)
.env(例)
URL_MESSAGE='https://rainbowplanet.slack.com/api/conversations.history' URL_REPLY='https://slack.com/api/conversations.replies' SLACK_BOT_TOKEN='xoxb-xxxxx' CHANNEL = 'C02SVHS0H7Z' TS = '1664089917.194639'
(図143)
↓
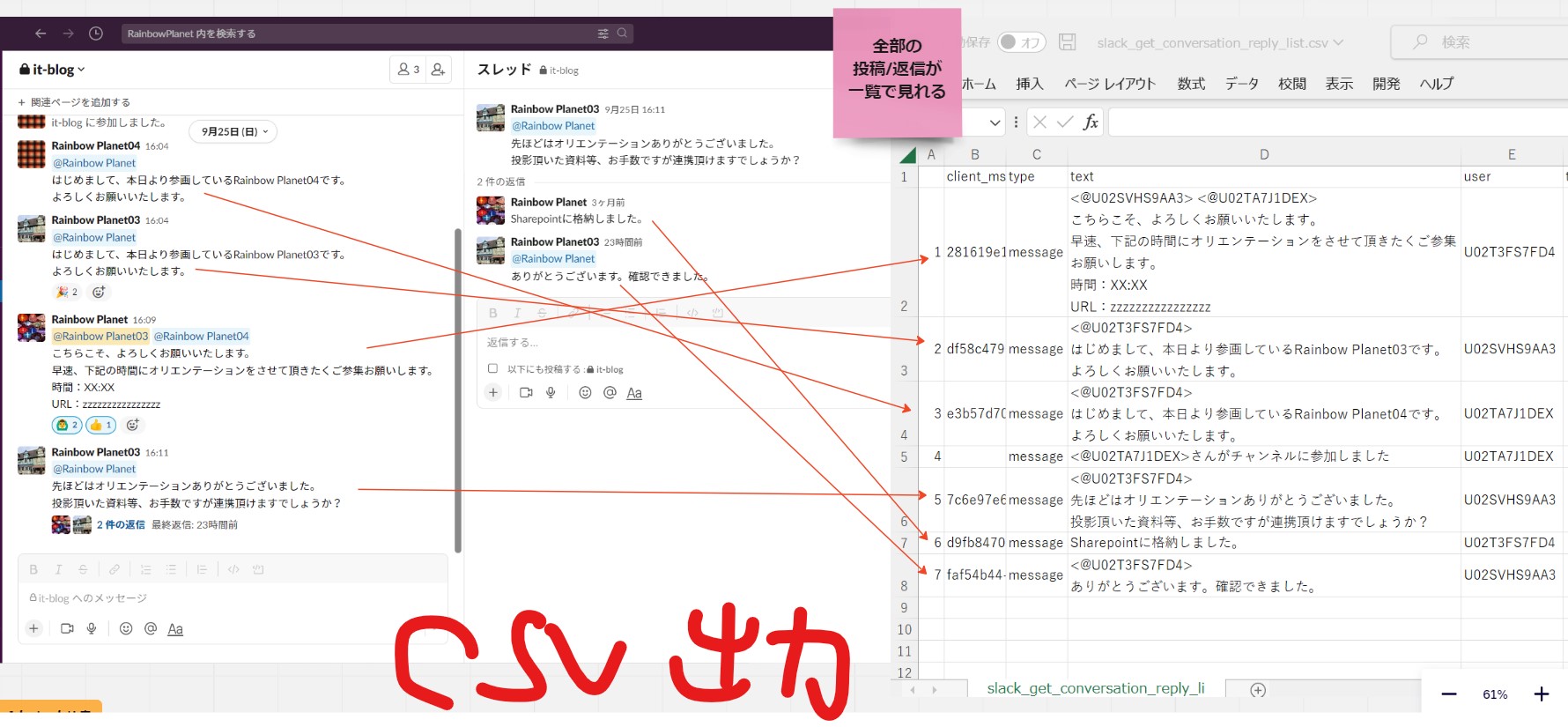
実行するとプログラムと同じ階層に、csvが生成されます。
(図144)
↓
Csvはユーザー単位でデータが出力されています。
(json形式のデータを表形式に整形している)
(図145①)