<目次>
Azure Synapse AnalyticsのパイプラインからREST APIを呼び出す方法
やりたいこと/概要
STEP0:前提
STEP1:事前準備
STEP2:パイプラインの作成
STEP3:データフローキャンバスでの変換ロジック作成
STEP4:データフローの実行とモニタリング
【注意】Azure Synapse Analyticsの料金について
Azure Synapse AnalyticsのパイプラインからREST APIを呼び出す方法
やりたいこと/概要
●やりたいこと
・Azure Synapse AnalyticsのパイプラインからREST APIを呼び出す
・REST APIから取得したデータを加工処理する
●概要
パイプライン
STEP1:事前準備
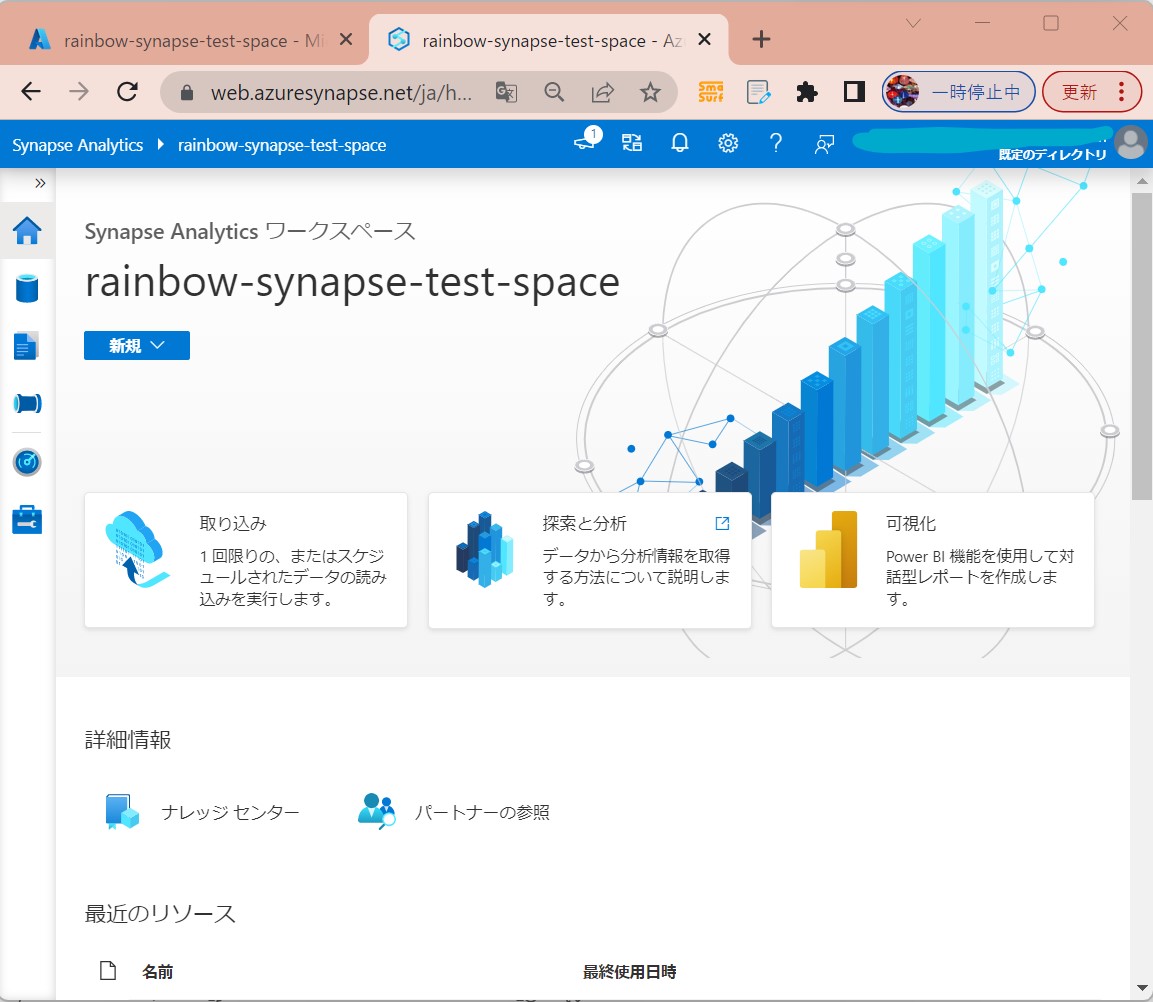
・①Synapse Studioを開く
(図111)
<備考>
Azure Synapse Analyticsのリソース未作成の方は下記を参照。
・②テストデータのダウンロード
下記をテキストに貼り付けてcsv形式でローカルに保存。
https://raw.githubusercontent.com/djpmsft/adf-ready-demo/master/moviesDB.csv
(図112)
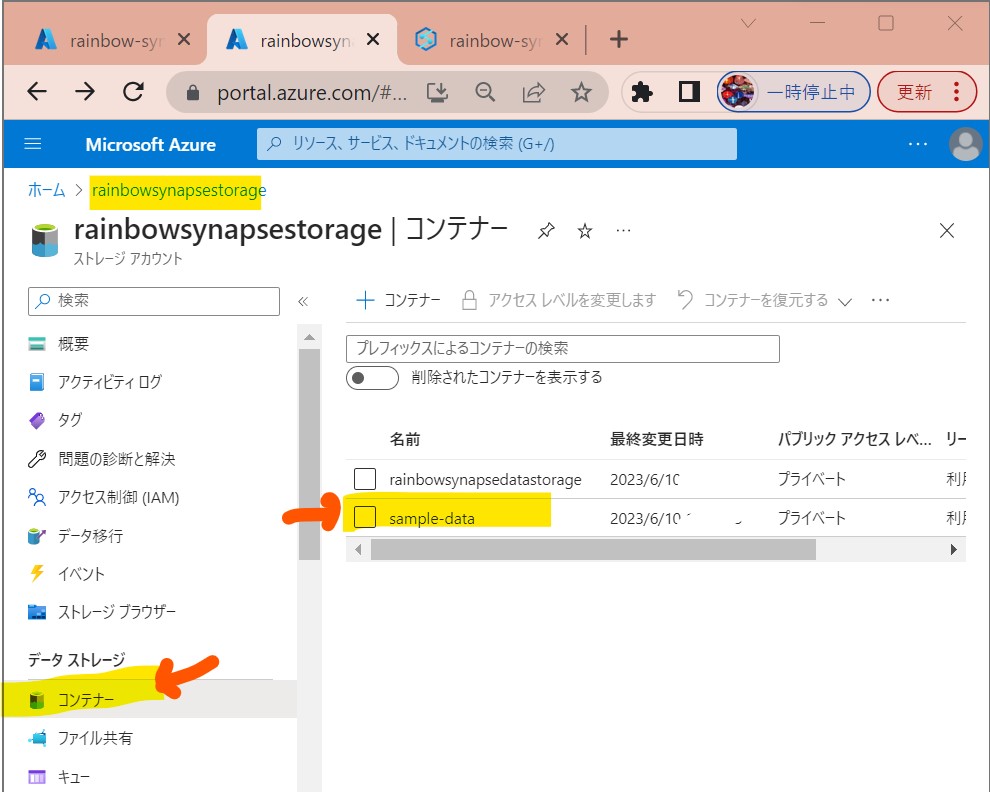
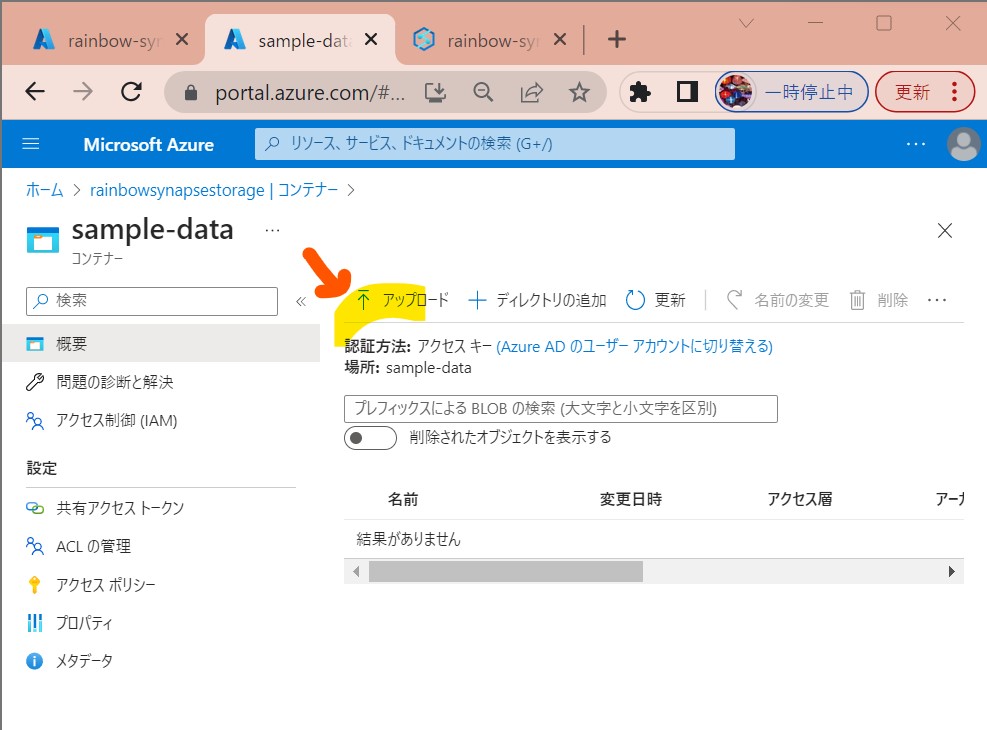
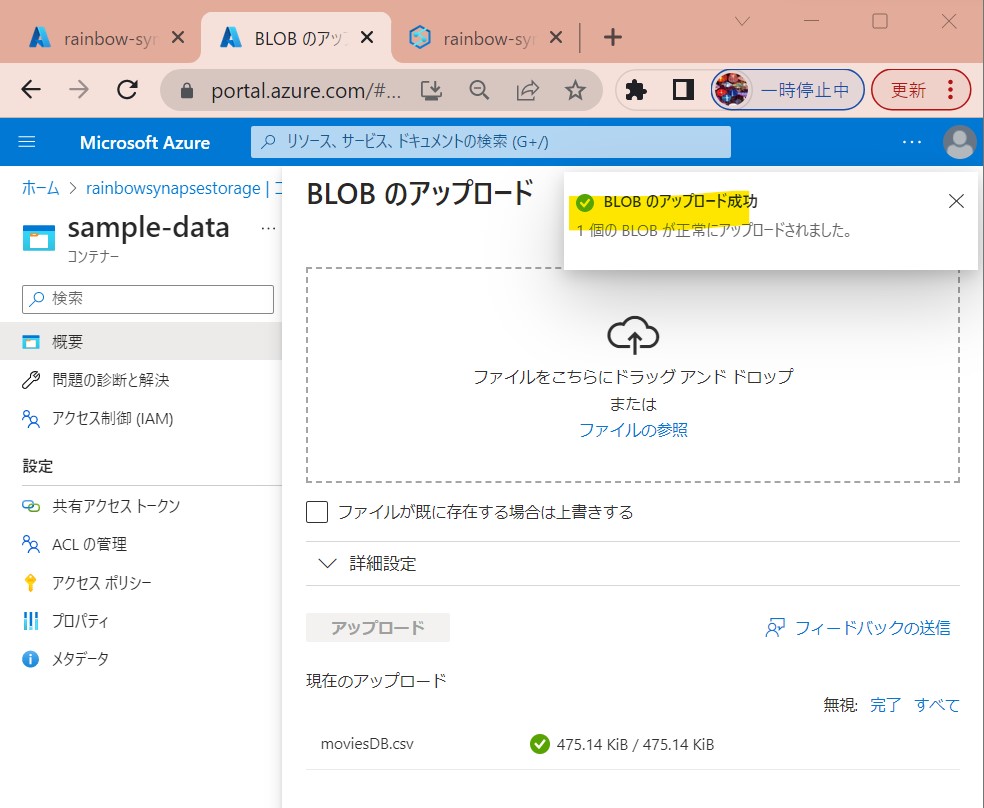
・③ダウンロードしたファイルをAzure Storageのコンテナ(sample-data)にアップロード
(図113①②③)
↓
↓
STEP2:パイプラインの作成
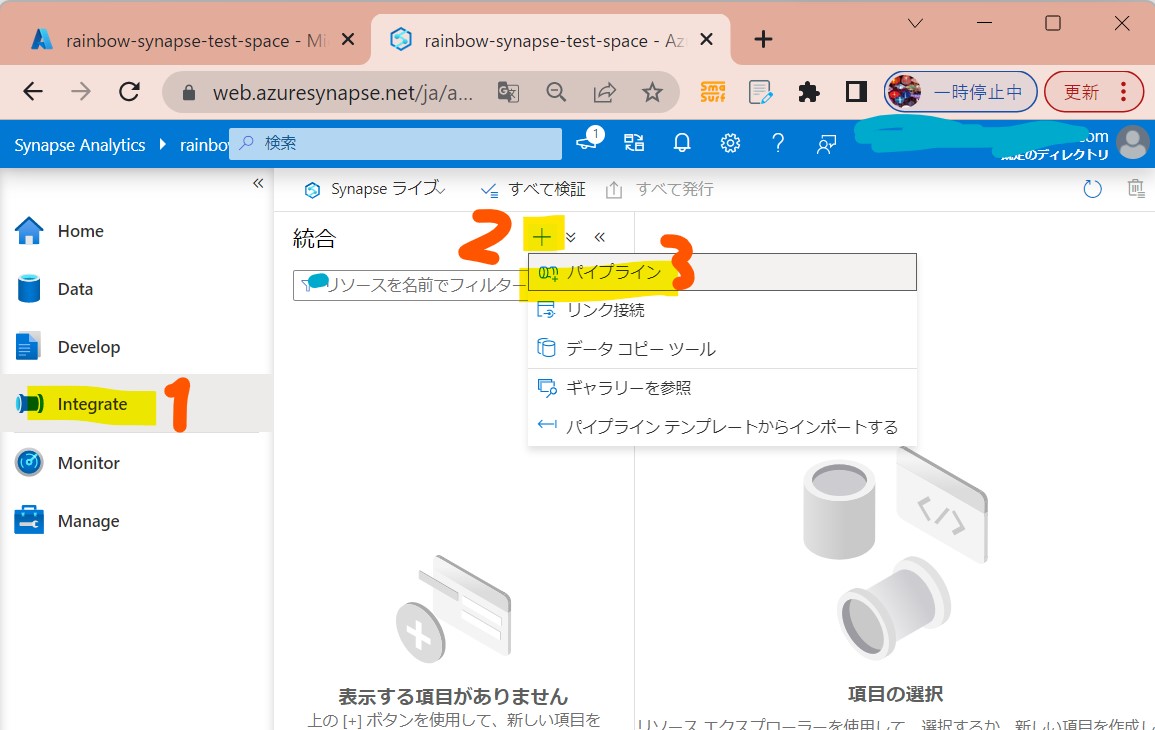
・①左メニューで「結合」→「+」→「パイプライン」
(図121)
↓
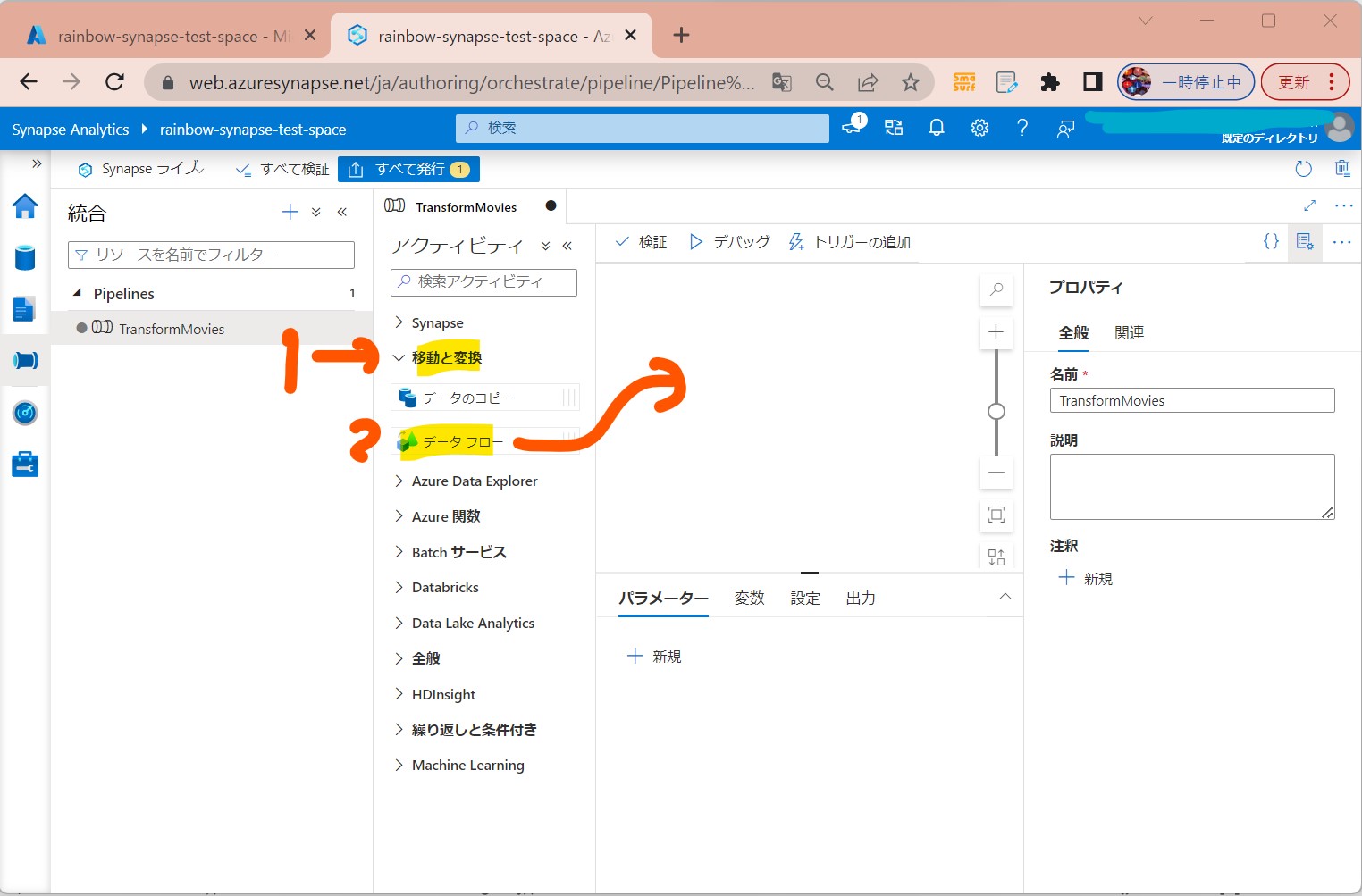
・②「アクティビティ」ペインの「移動と変換」で「データフロー」を中央キャンバスにドラッグ&ドロップ
(図122)
↓
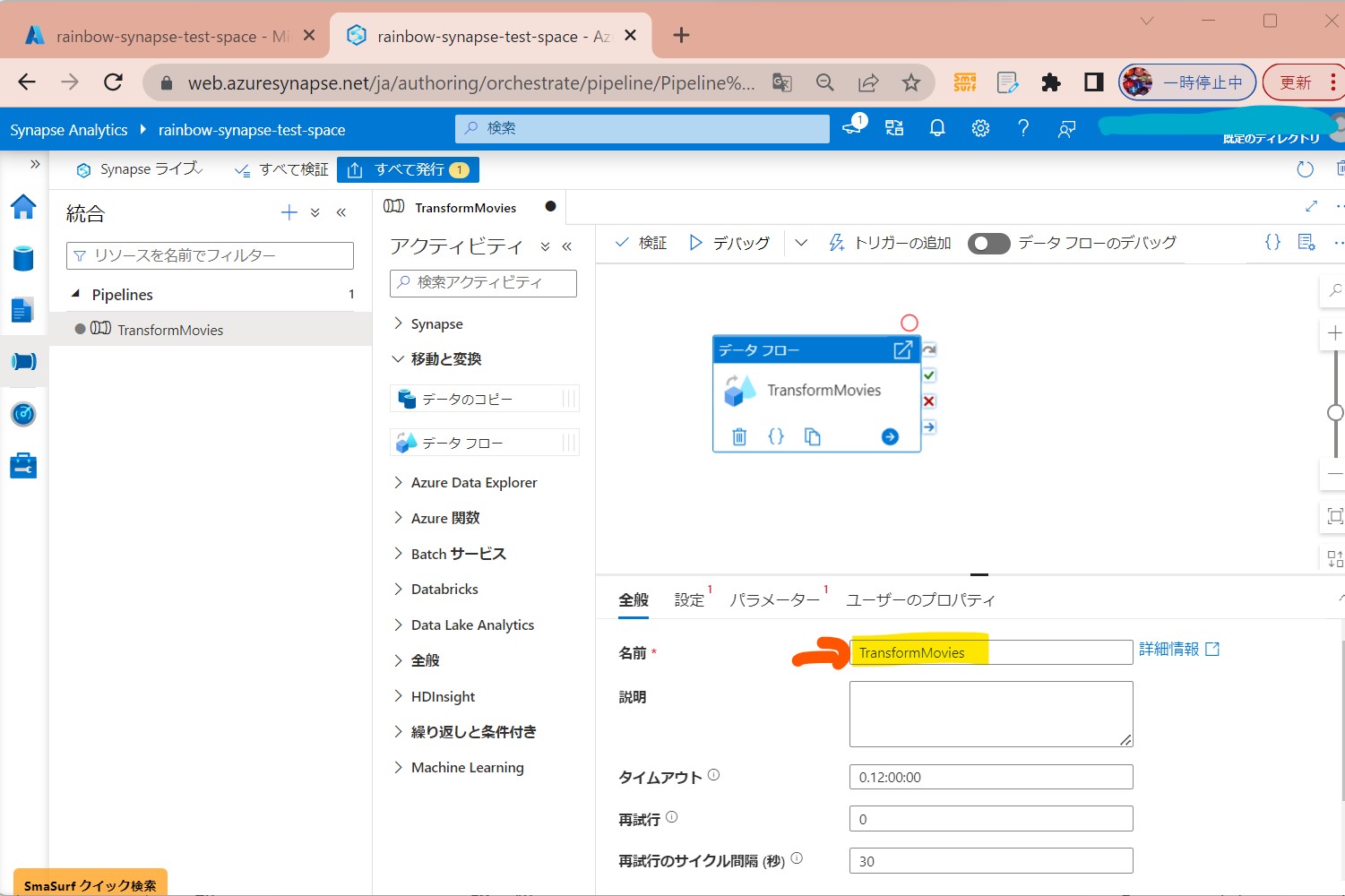
・③「データフローアクティビティ」名前を付ける(例:TransformMovies)
(図123)
↓
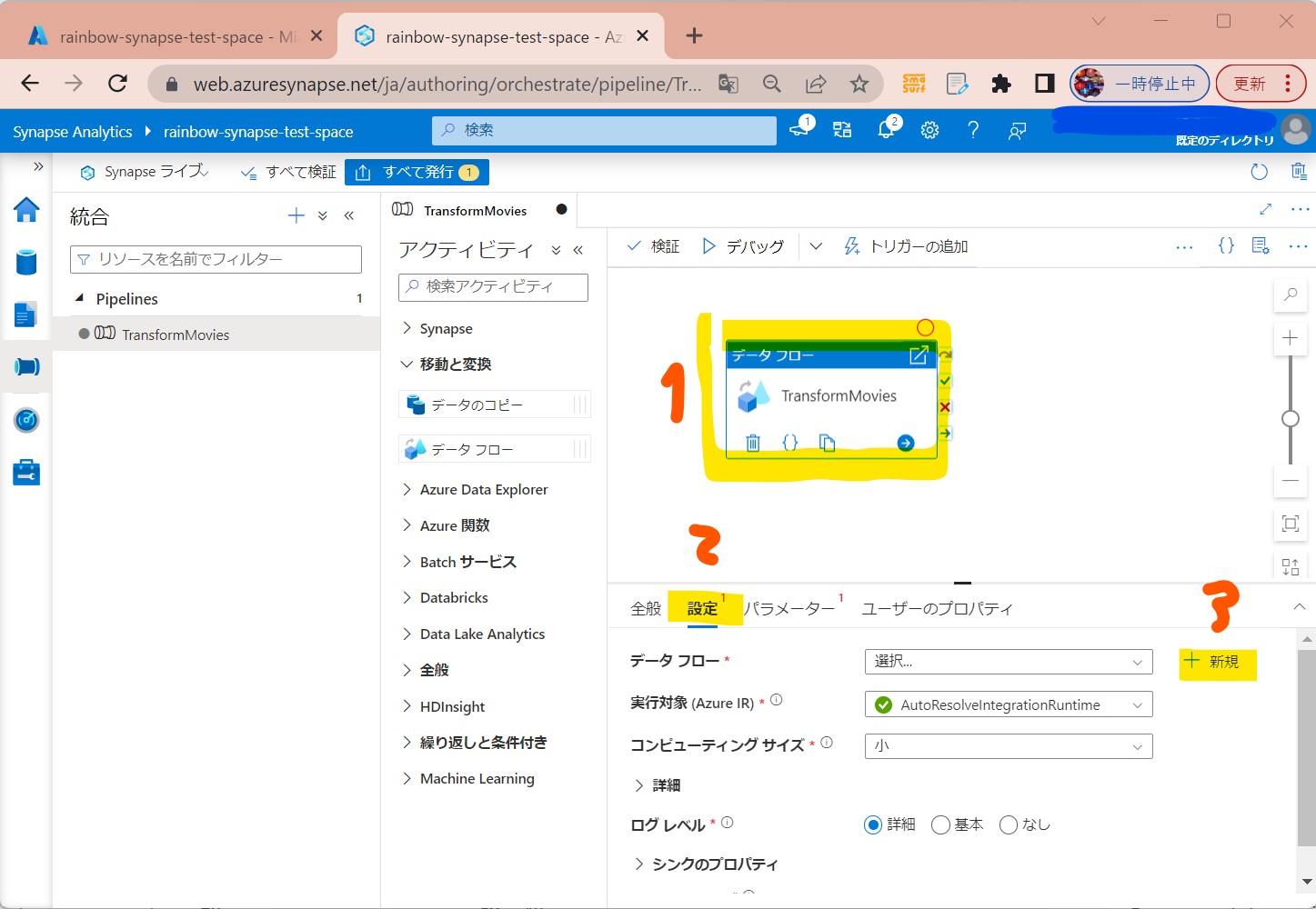
・④「設定」→「+新規」を選択
(図124)
↓
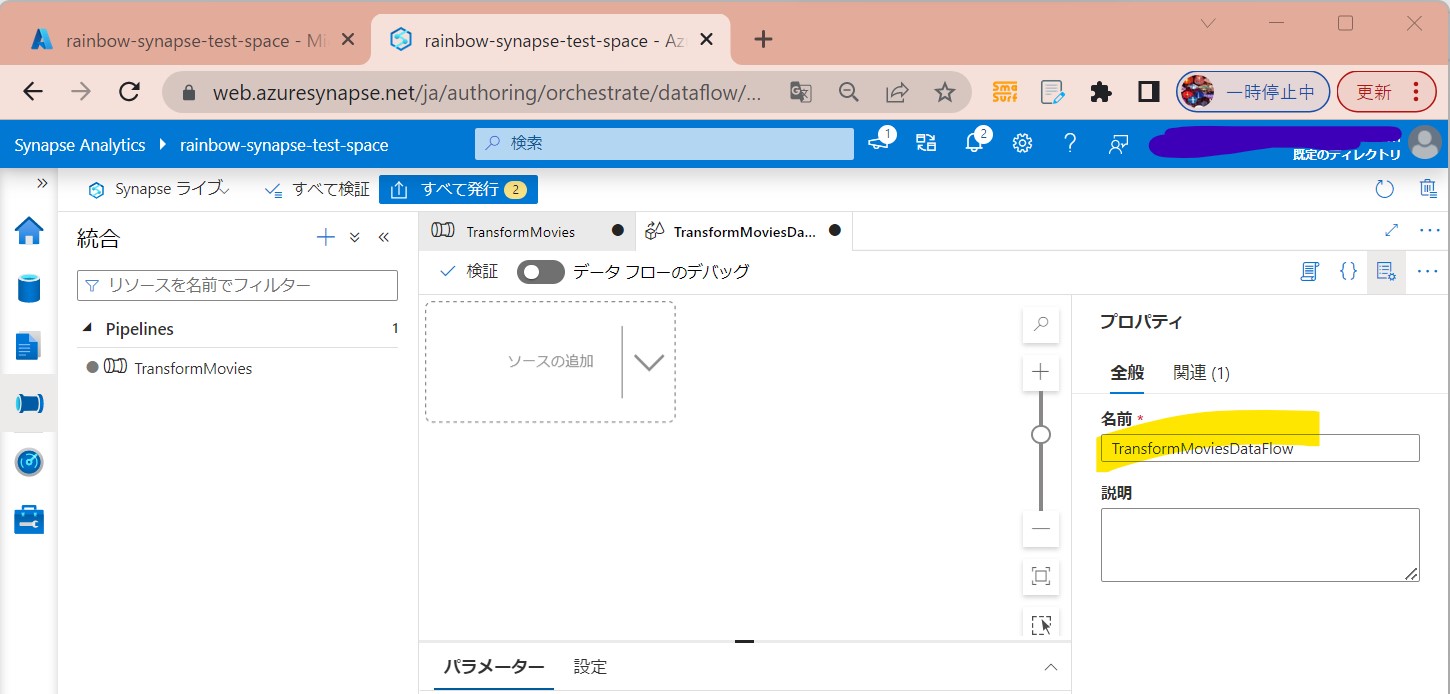
・⑤「データフロー」の名前を付ける(例:TransformMoviesDataFlow)
(図125)
STEP3:データフローキャンバスでの変換ロジック作成
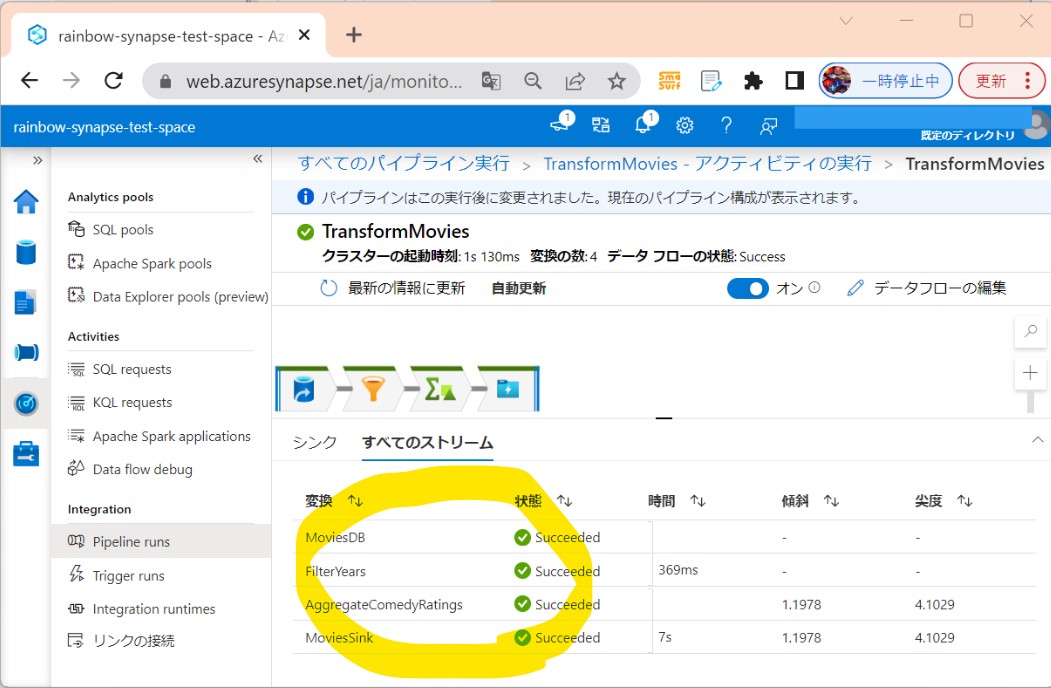
Data Flow を作成すると、データ フロー キャンバスが自動的に表示されます。 この手順では、ADLS ストレージ内の MoviesDB.csv を取得し、1910 年から 2000 年までのコメディの平均評価を集計するデータ フローを作成します。 次に、このファイルを ADLS ストレージに書き戻します。
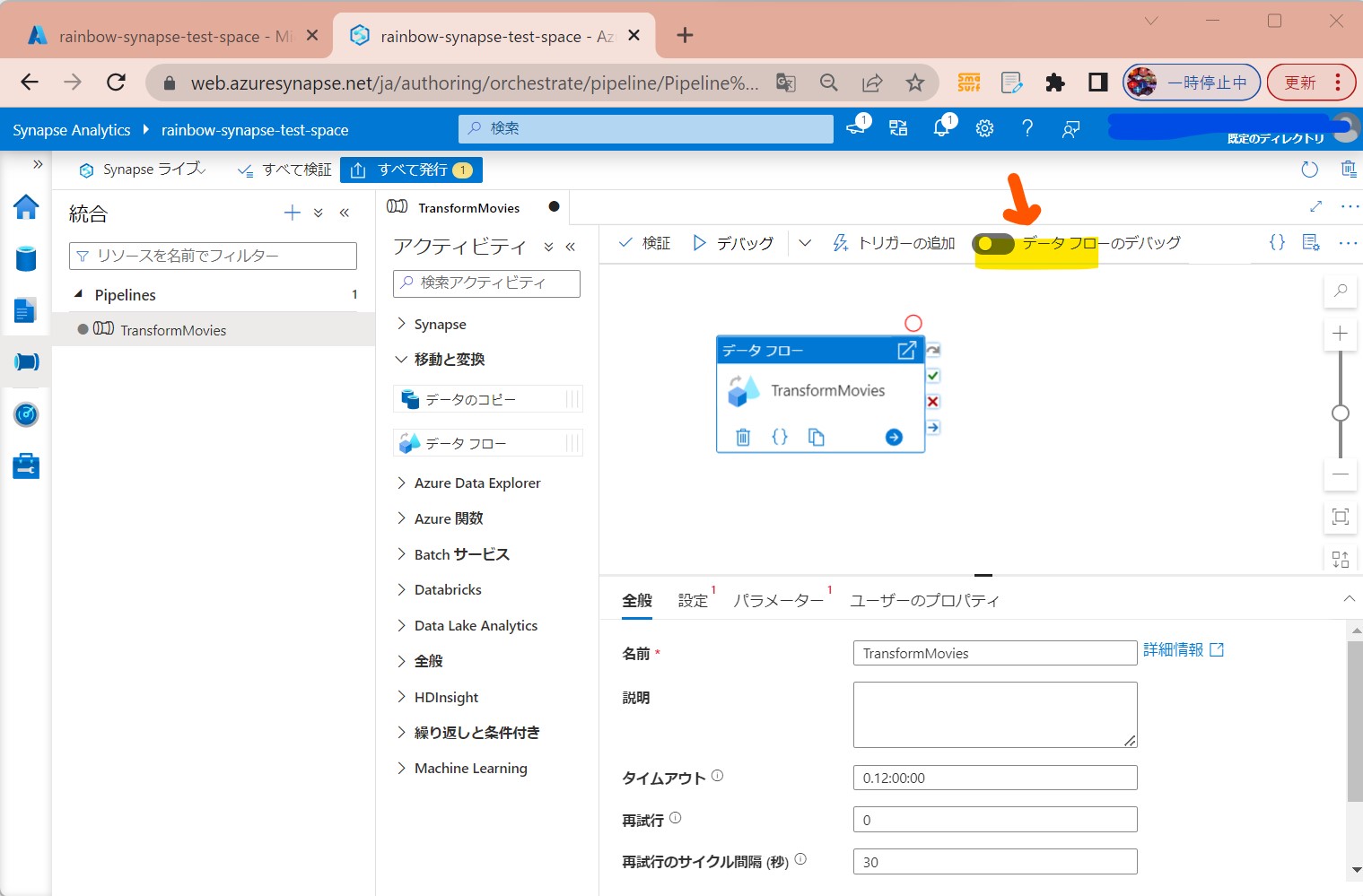
STEP3-1:「データフローのデバッグ」をONにする
・変換ロジックの対話的なテストが行える
(図211)
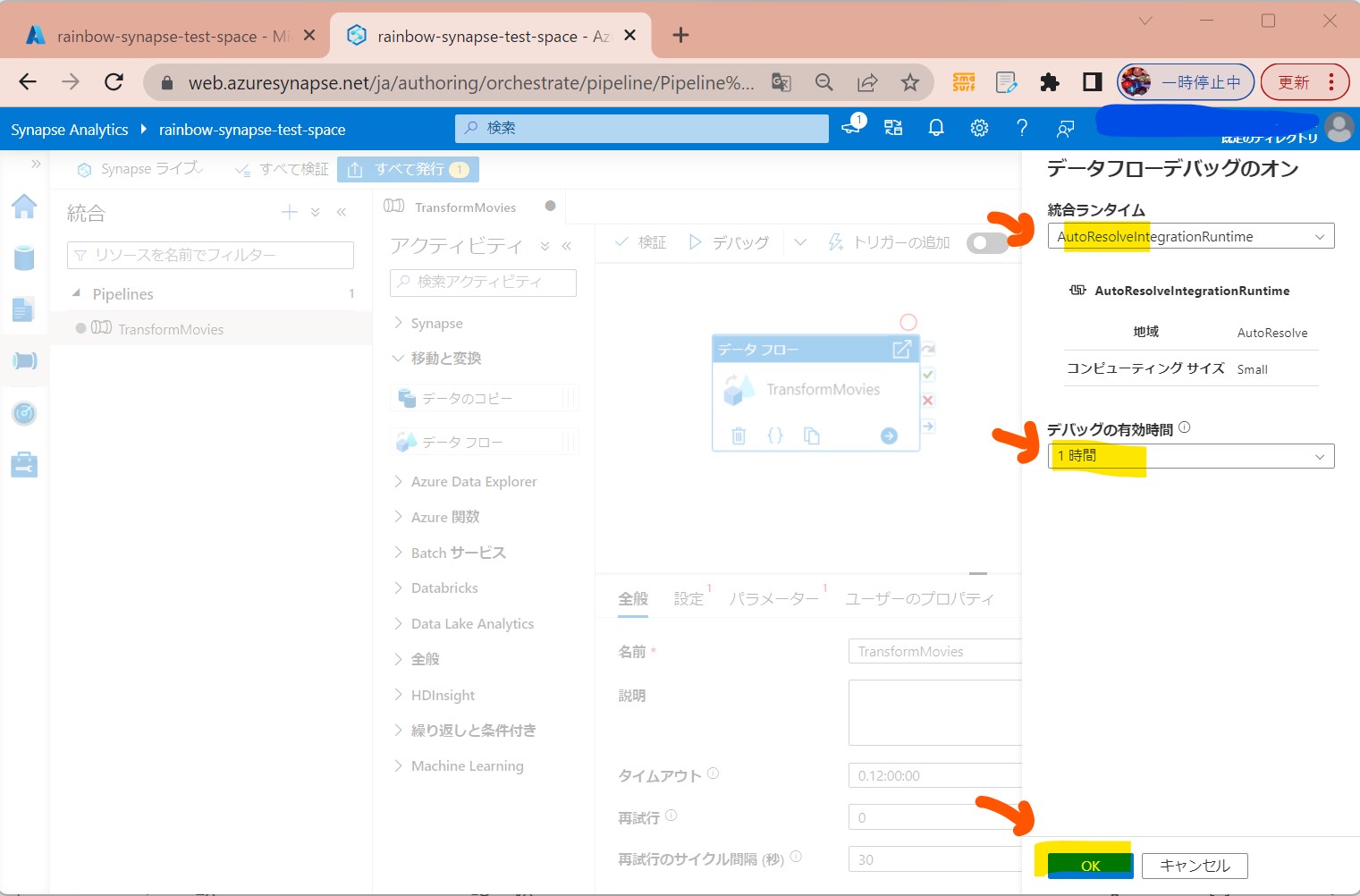
(図212)
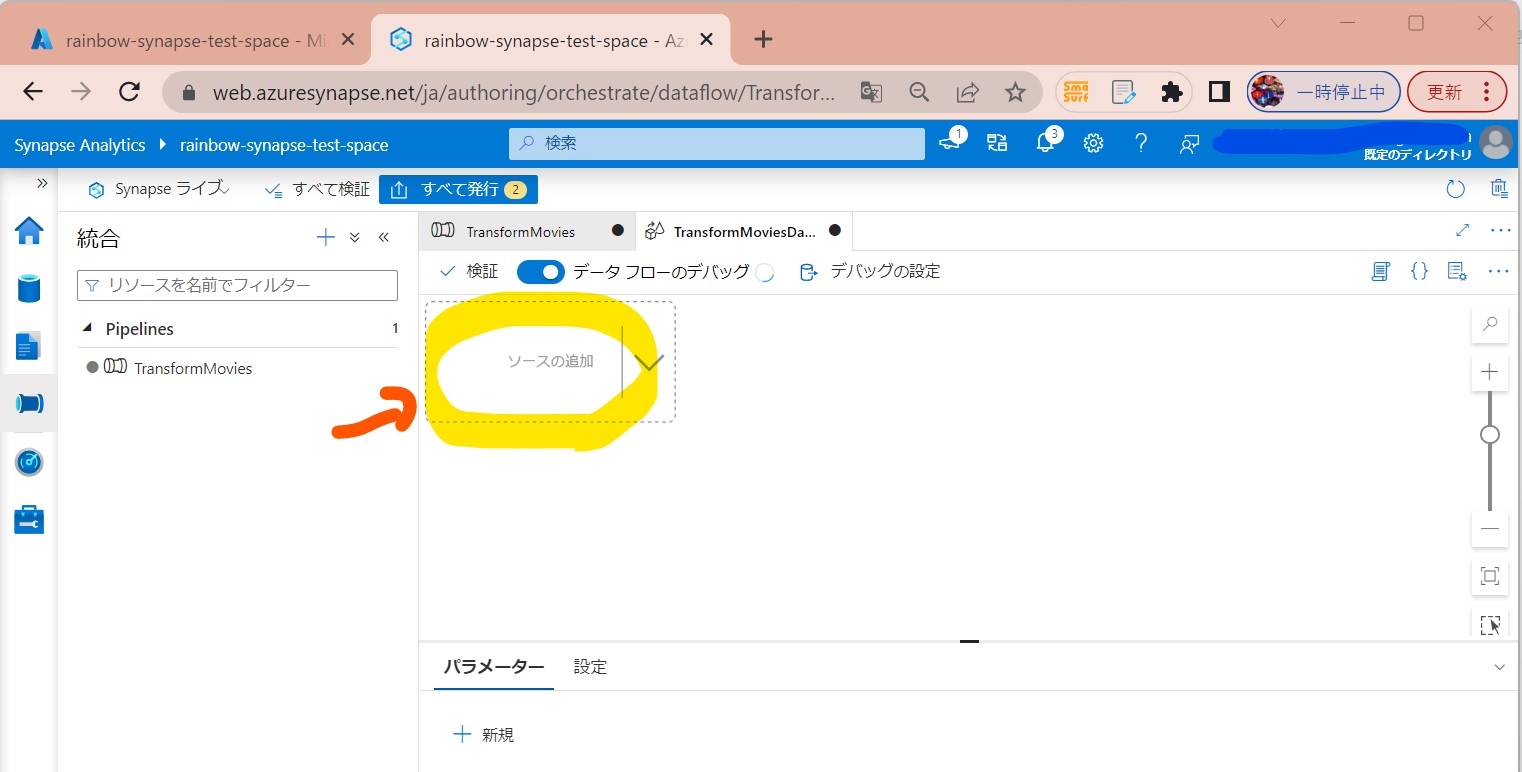
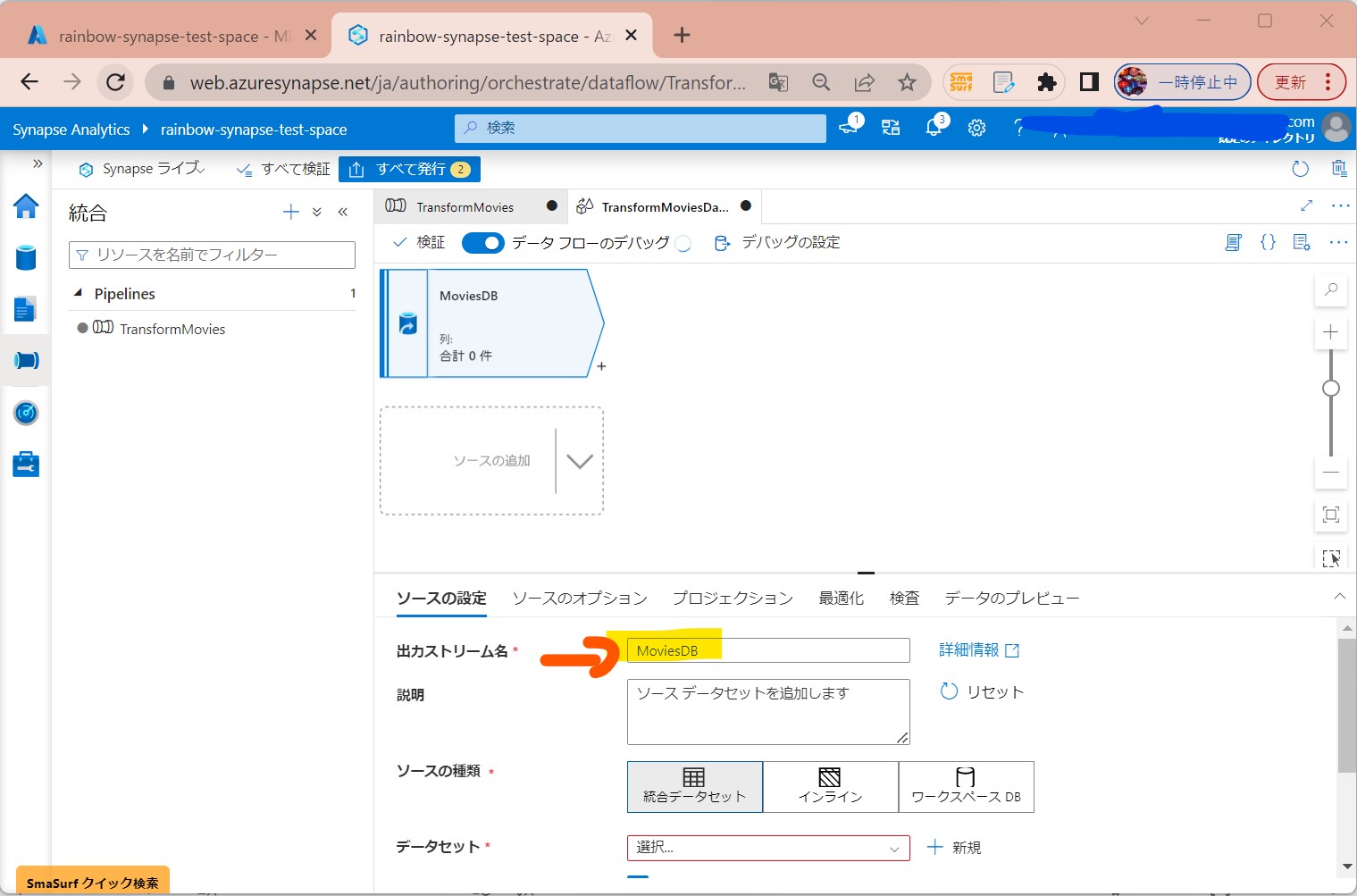
STEP3-2:データソースの追加
・①「ソースの追加」
(図213①②)
↓
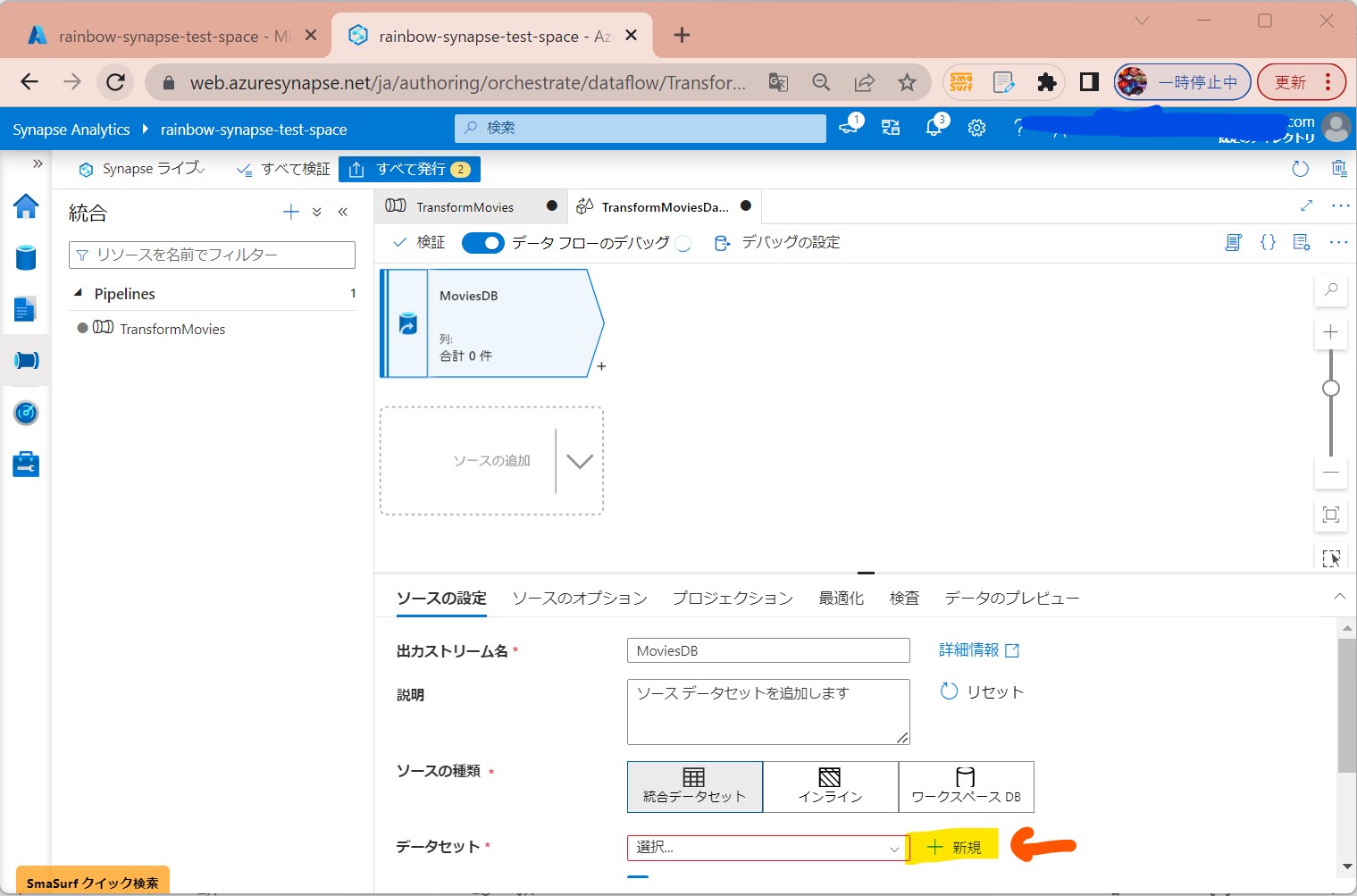
・②「+New」で「データソース」を新規作成
(図214)
↓
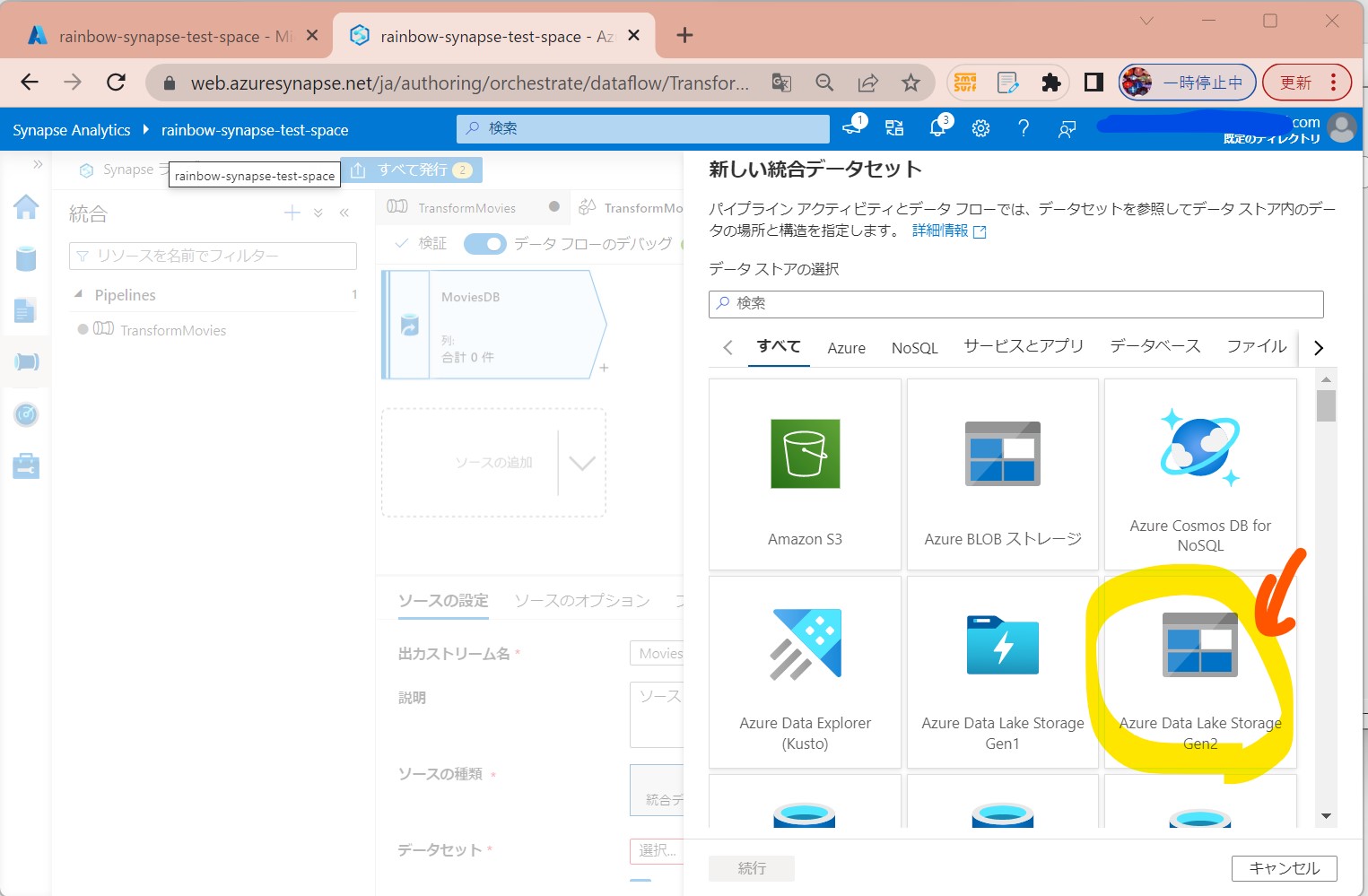
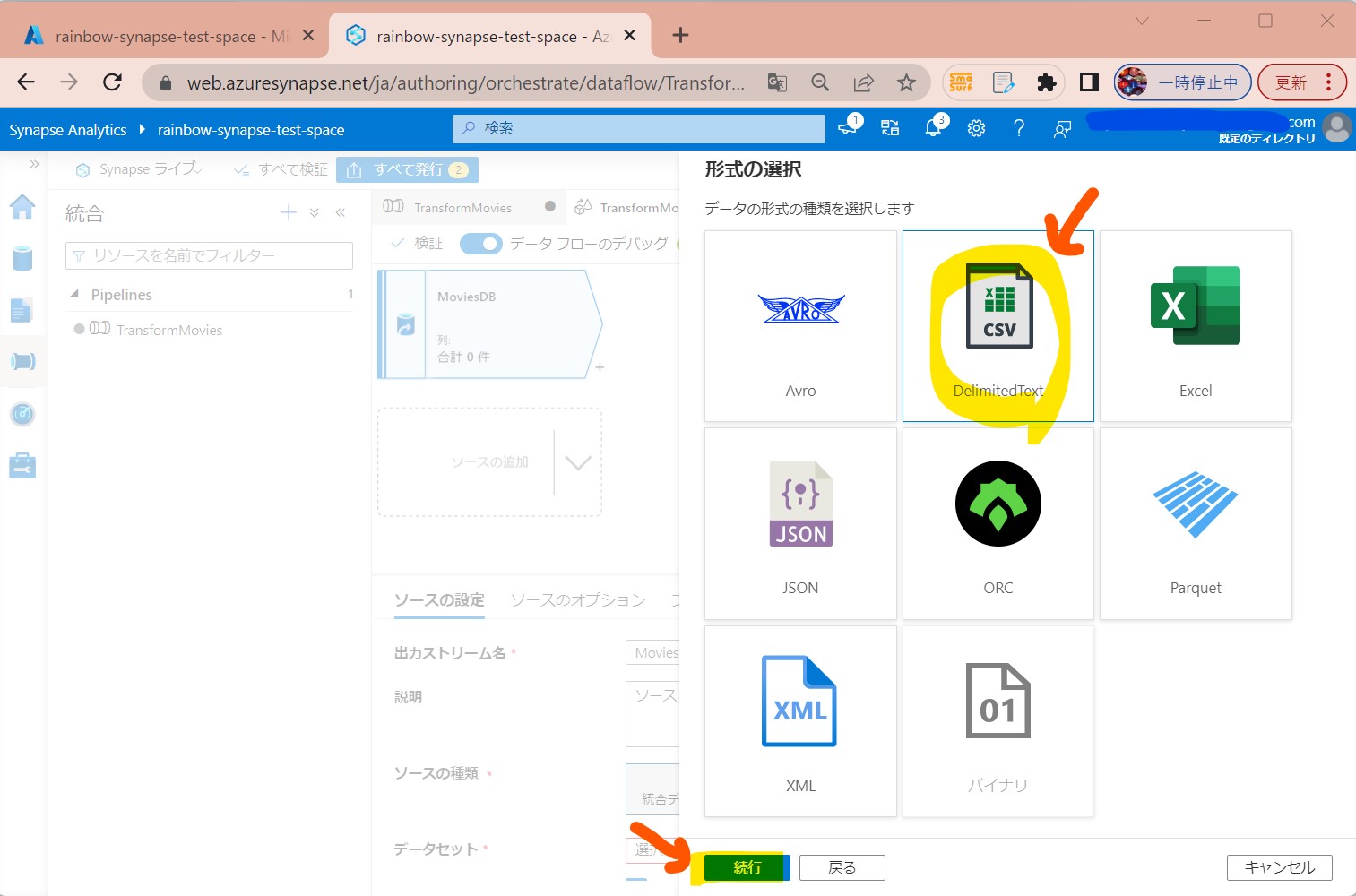
・③「Azure Data Lake Storage Gen2」→「DelimitedText」を選択
(図215①②)
↓
↓
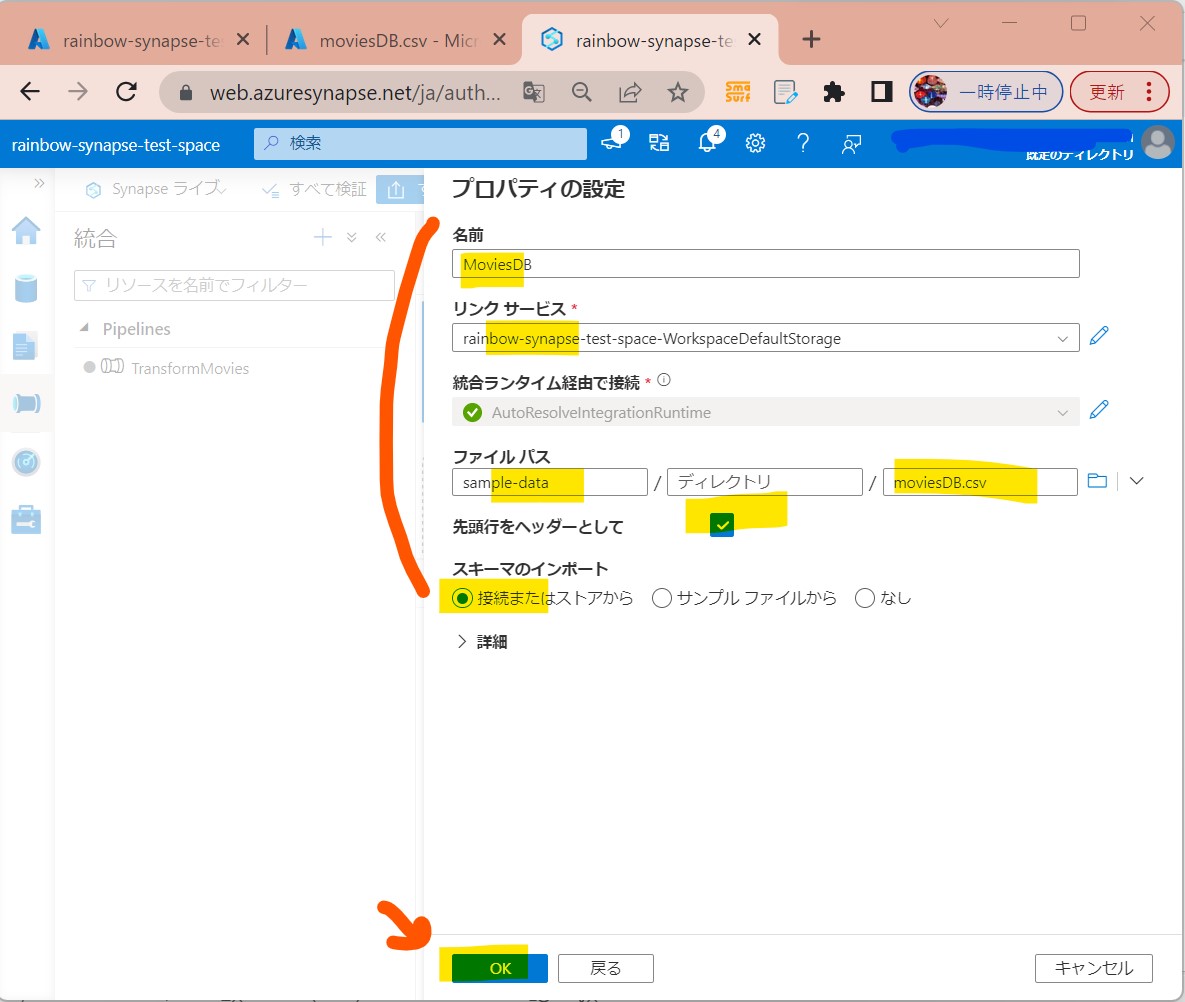
・④データ(例:moviesDB.csv)が格納されているストレージの情報を設定してOK
(図216)
↓
・④データ(例:moviesDB.csv)が格納されているストレージの情報を設定してOK
(図216)
↓
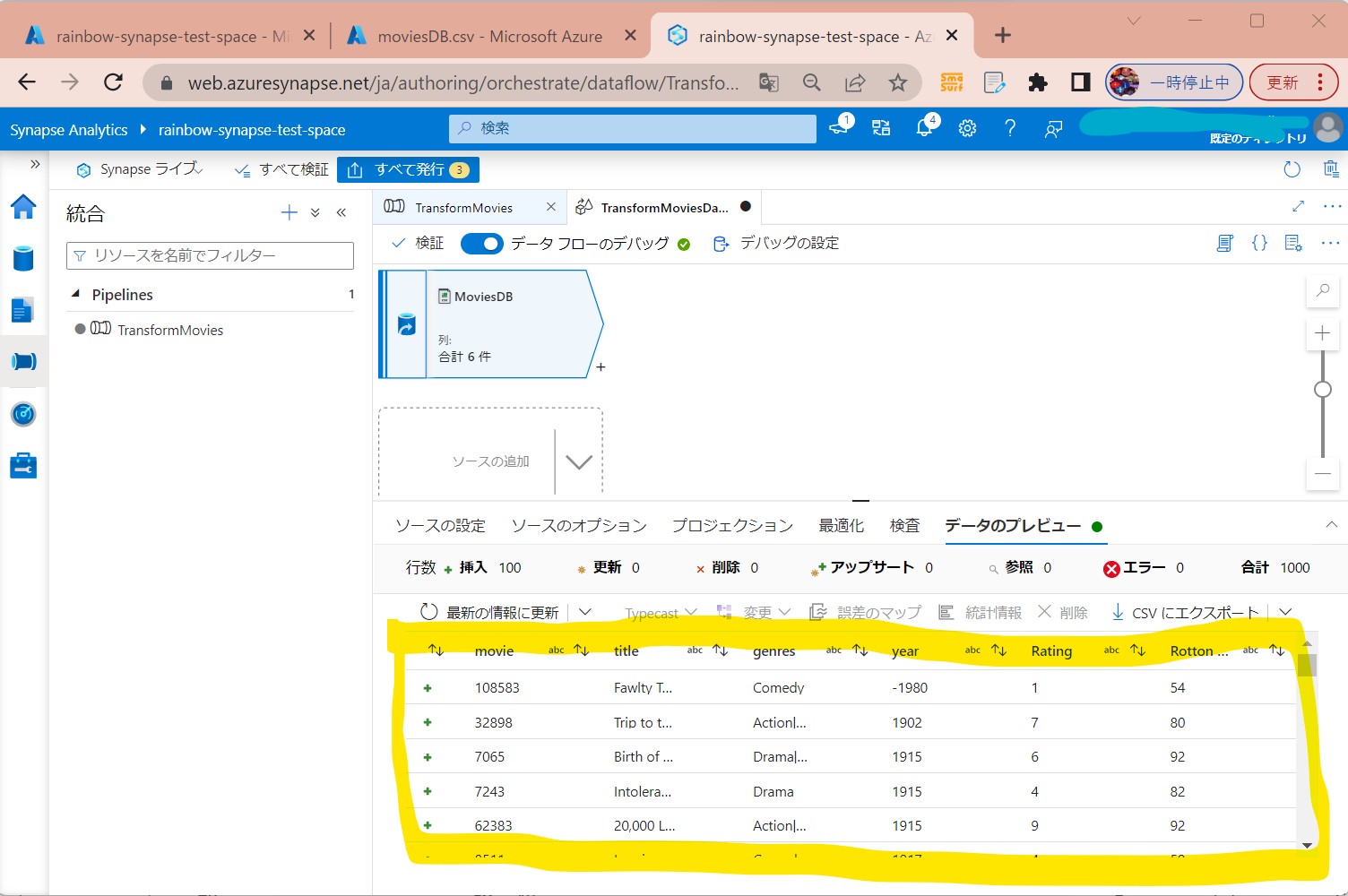
・⑤データのプレビューが表示された
(図217)
STEP3-3:フィルター
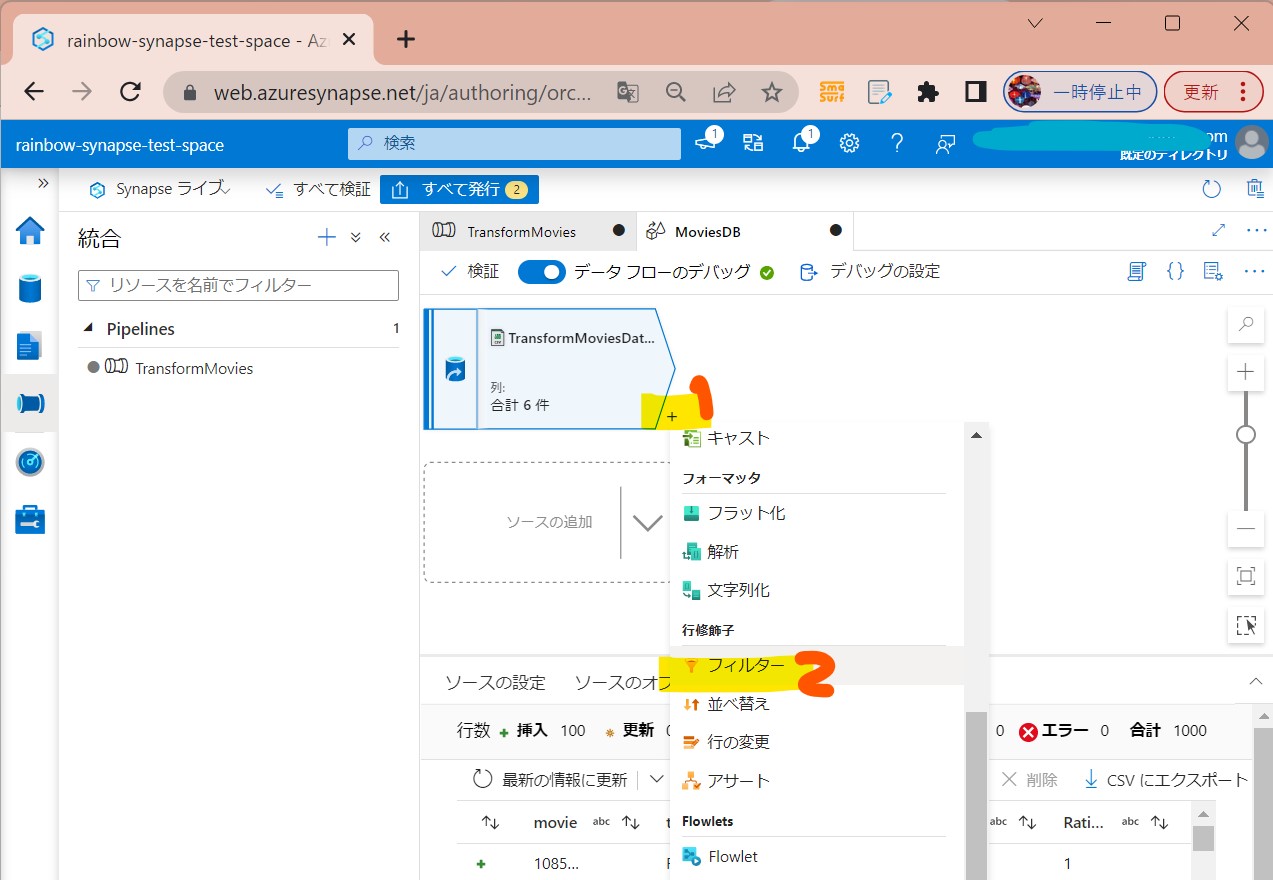
・①「+」→「フィルター」を押下
(図221)
↓
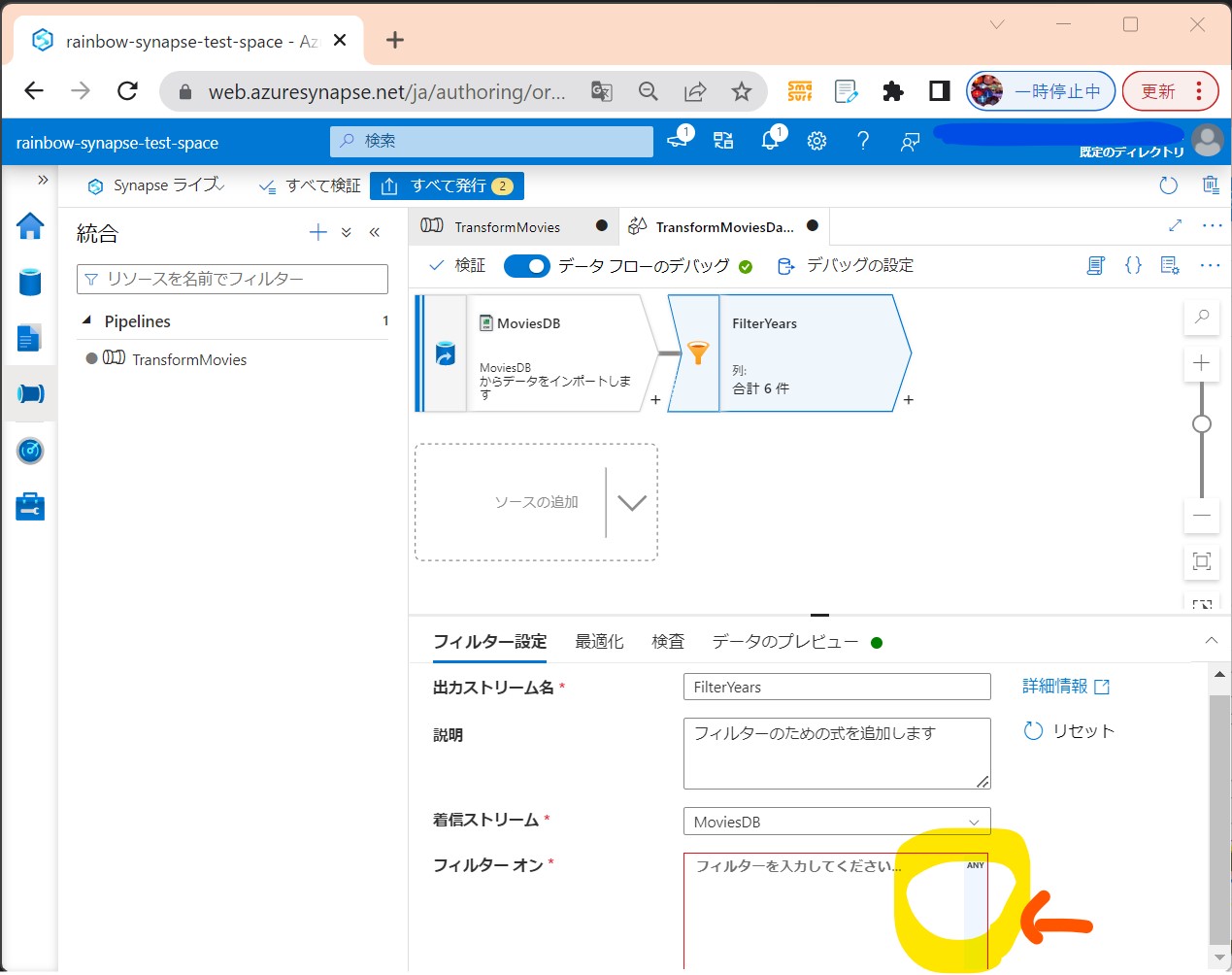
・②「フィルターオン」項目右側の「ANY」押下
(図222)
↓
・③式を入力
抽出条件:1910年と2000年の間のコメディ映画を抽出
式:toInteger(year) >= 1910 && toInteger(year) <= 2000
(図223)
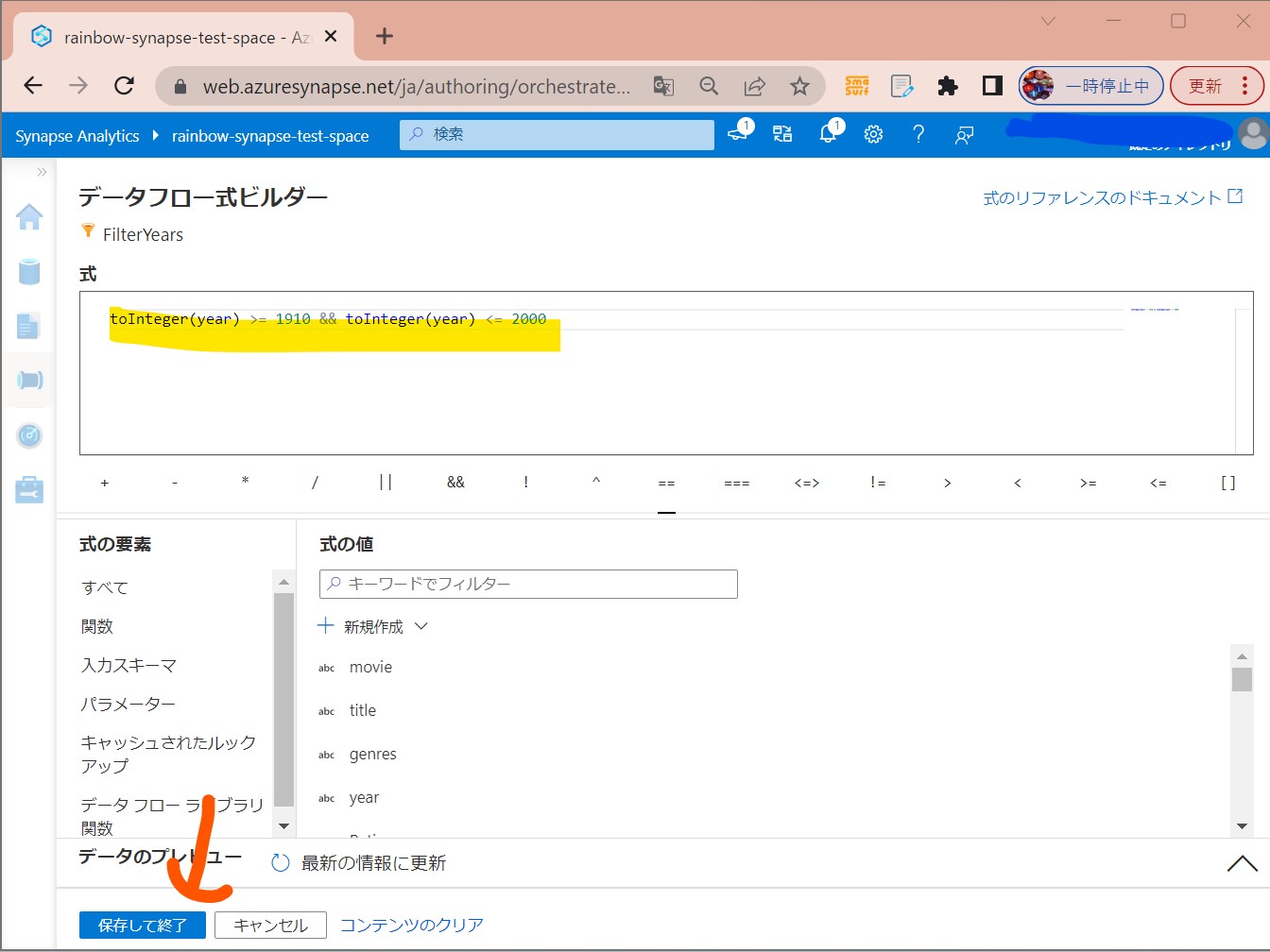
↓
・④式が入力された
(図224)
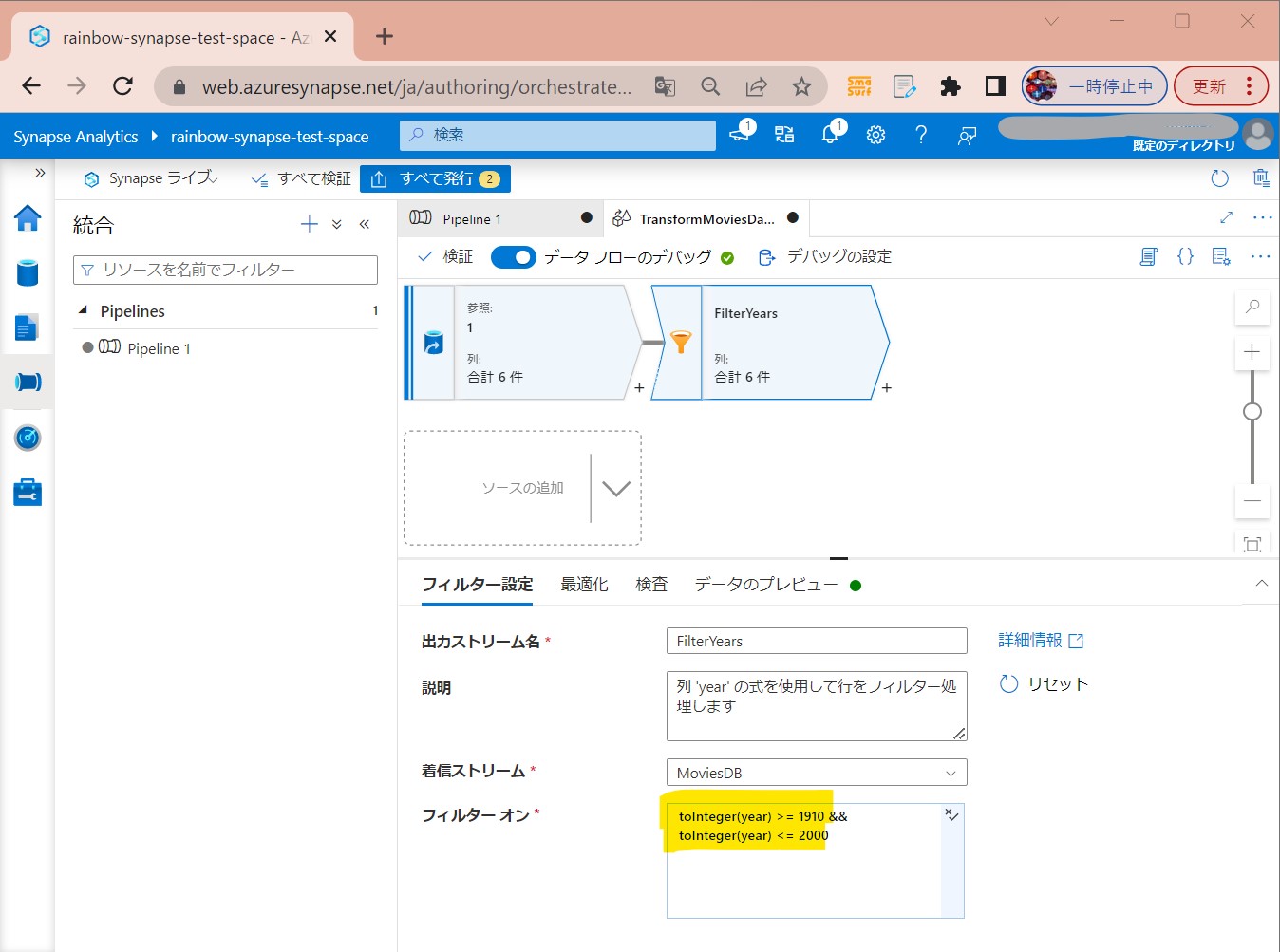
↓
・⑤デバッグがONなら「最新の情報に更新」で指定の期間にフィルターされる
(図225)
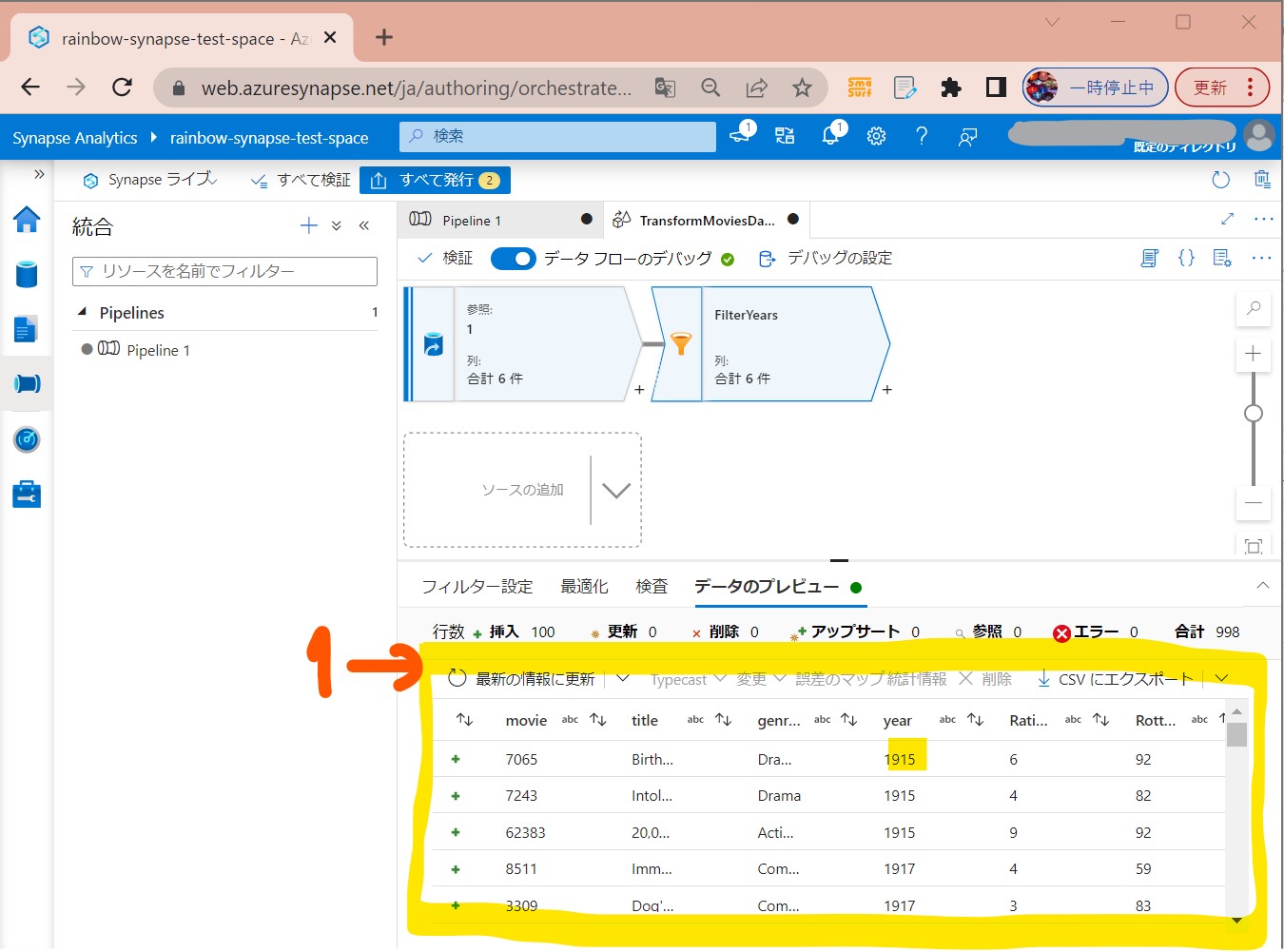
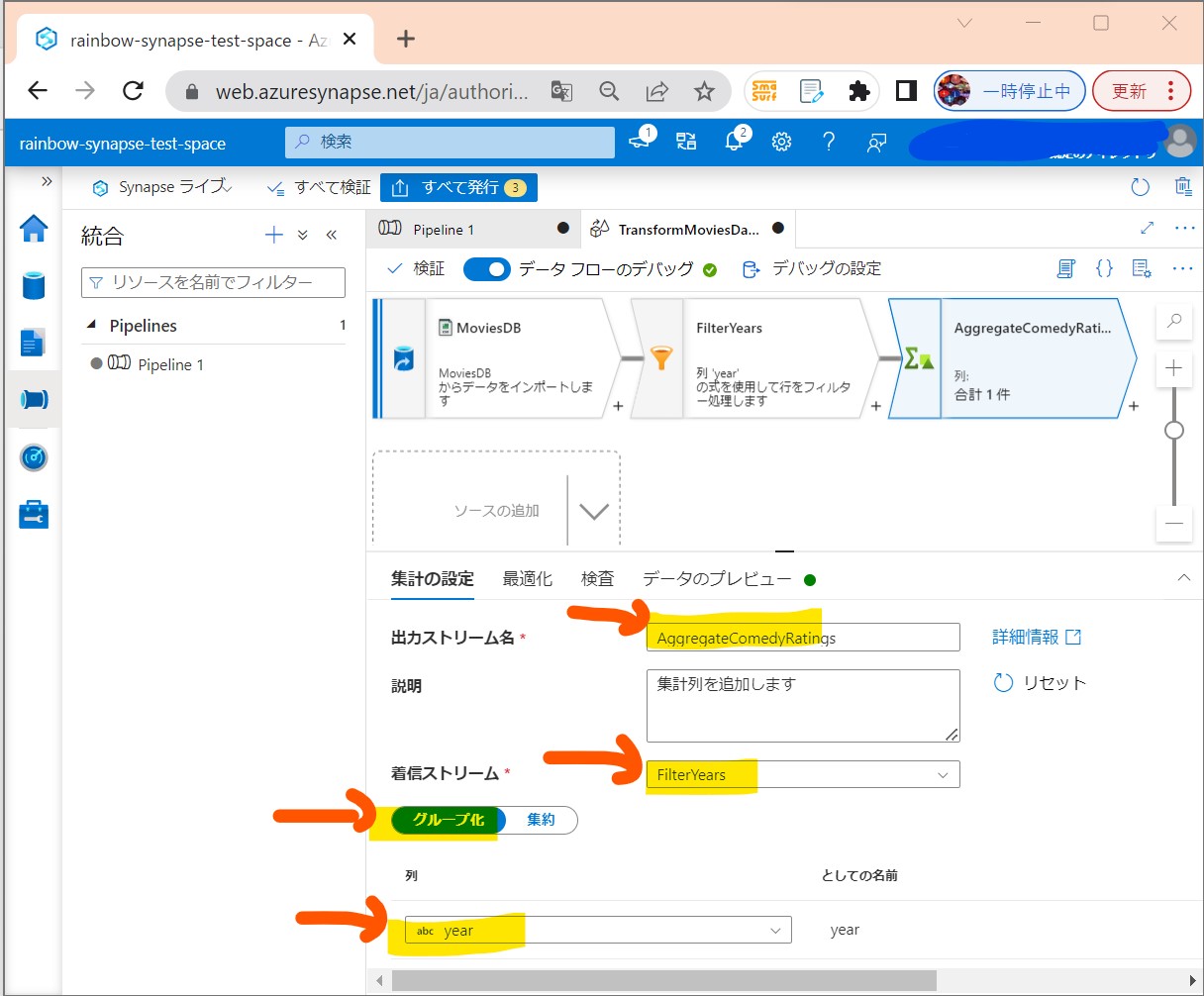
STEP3-4:「集約」の設定
・①「+」→「集約」を押下
(図231)
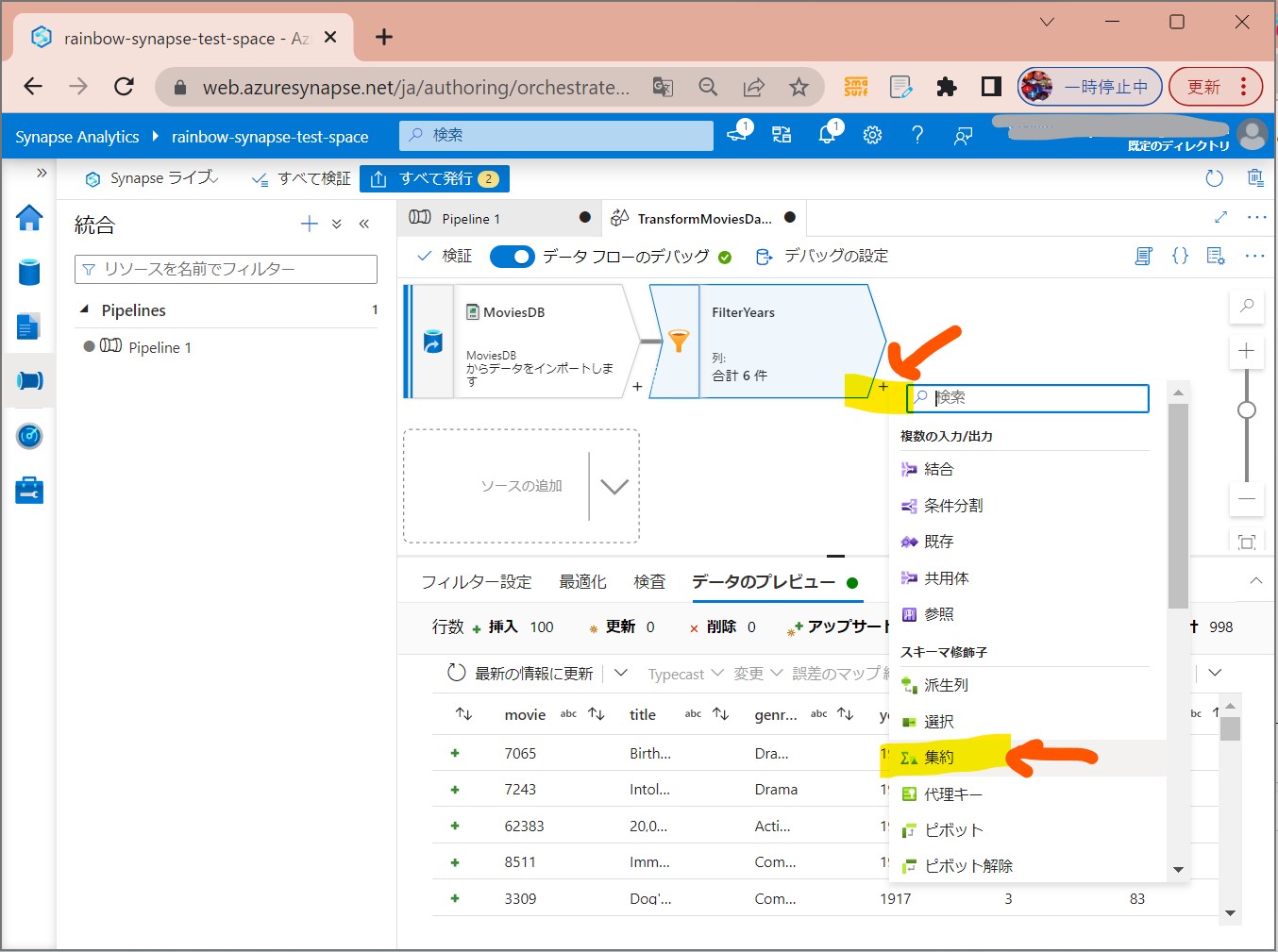
↓
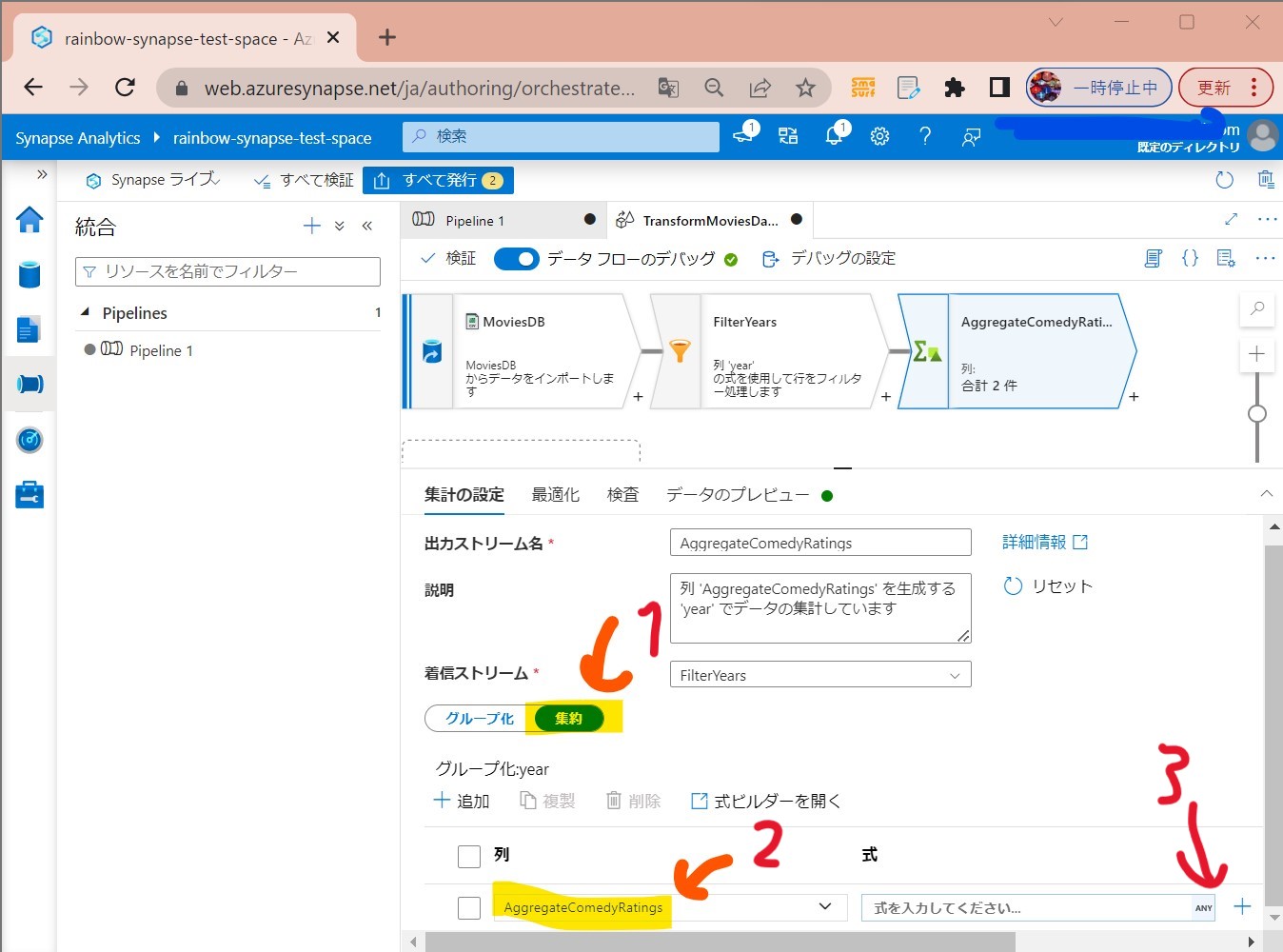
・②集計の設定
(図232①②)
↓
↓
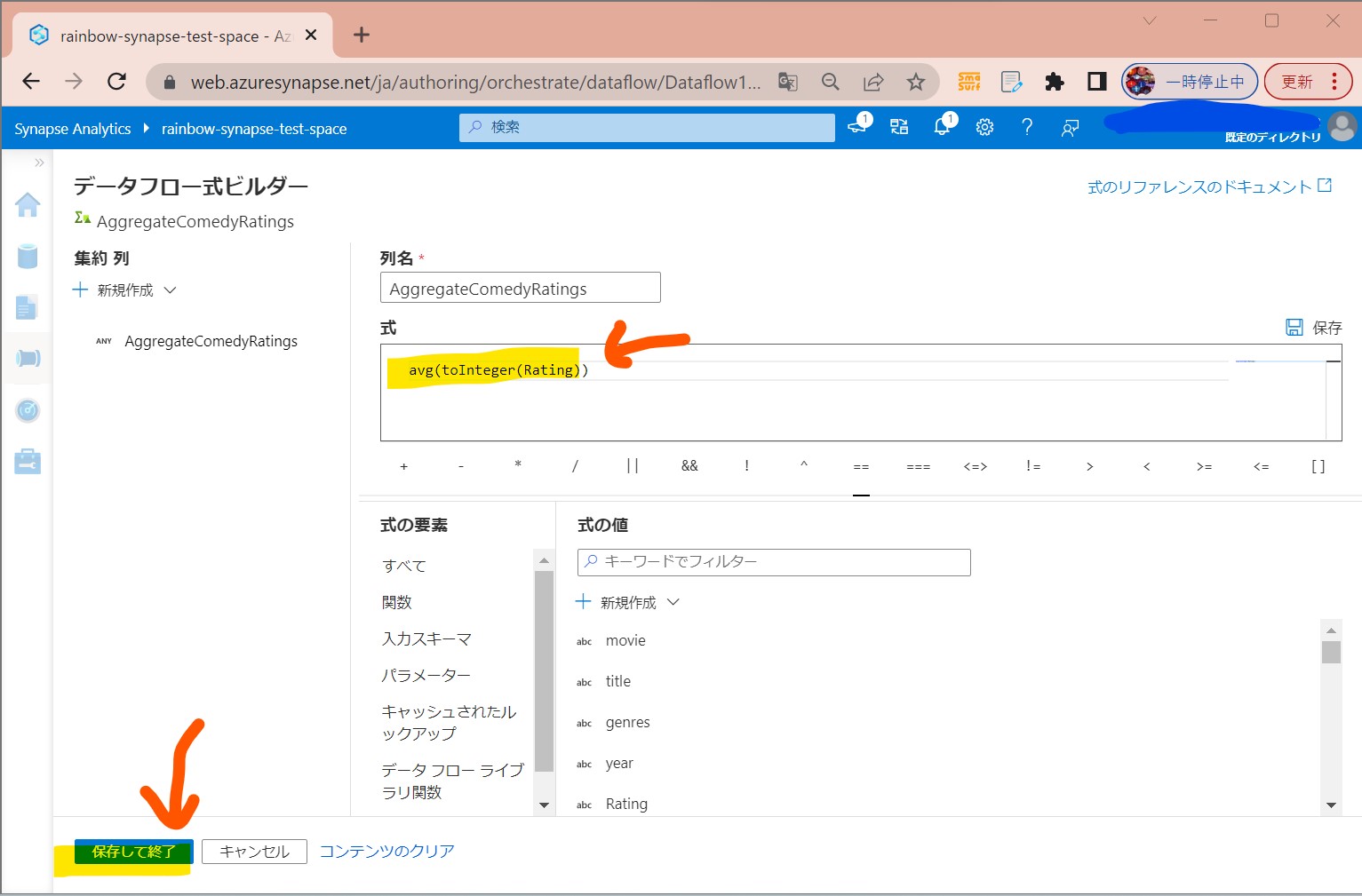
・③式を入力→「保存して終了」
avg(toInteger(Rating))
(図233)
↓
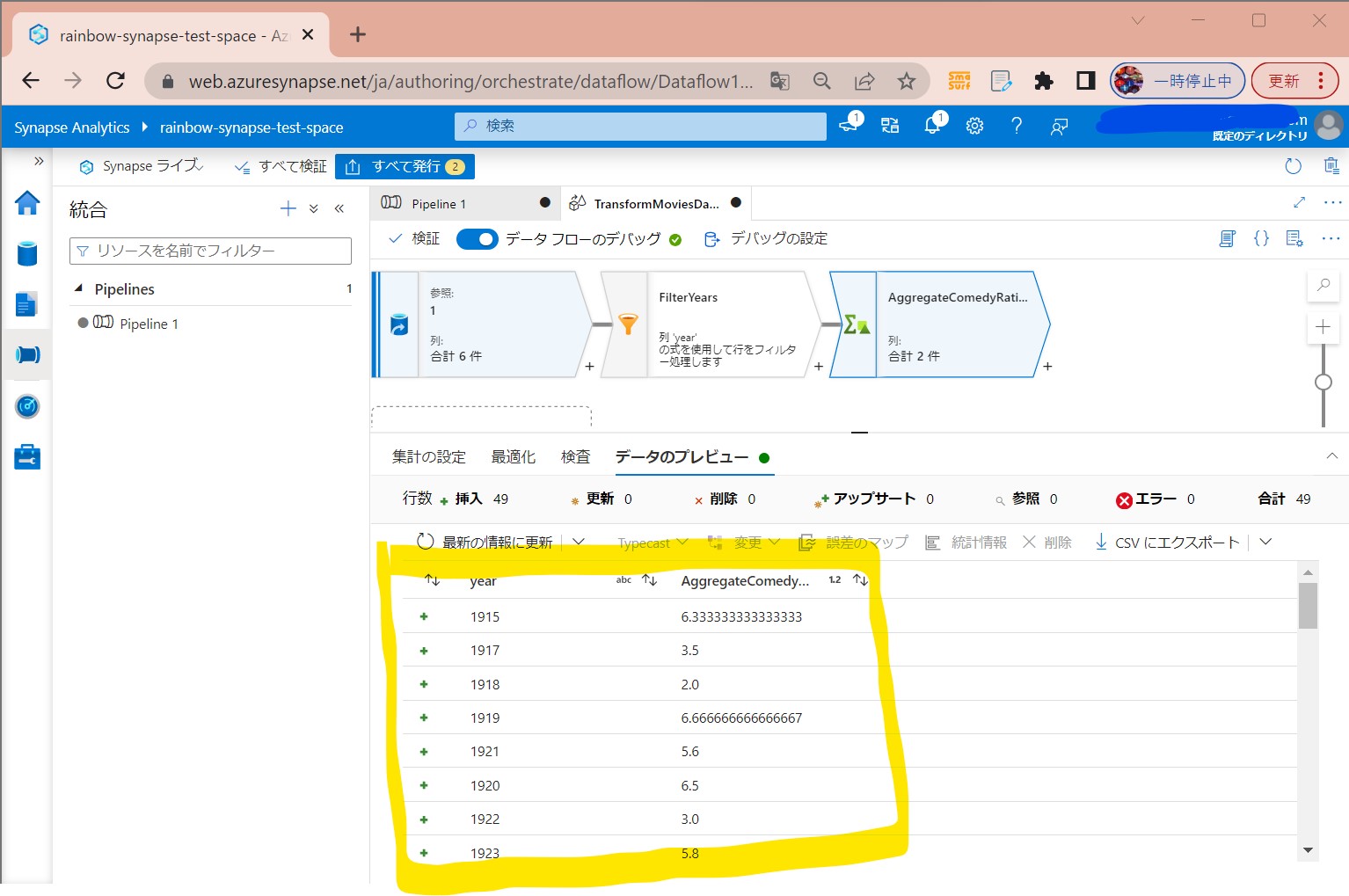
・④年度毎の評価の平均点が算出できた
(図234)
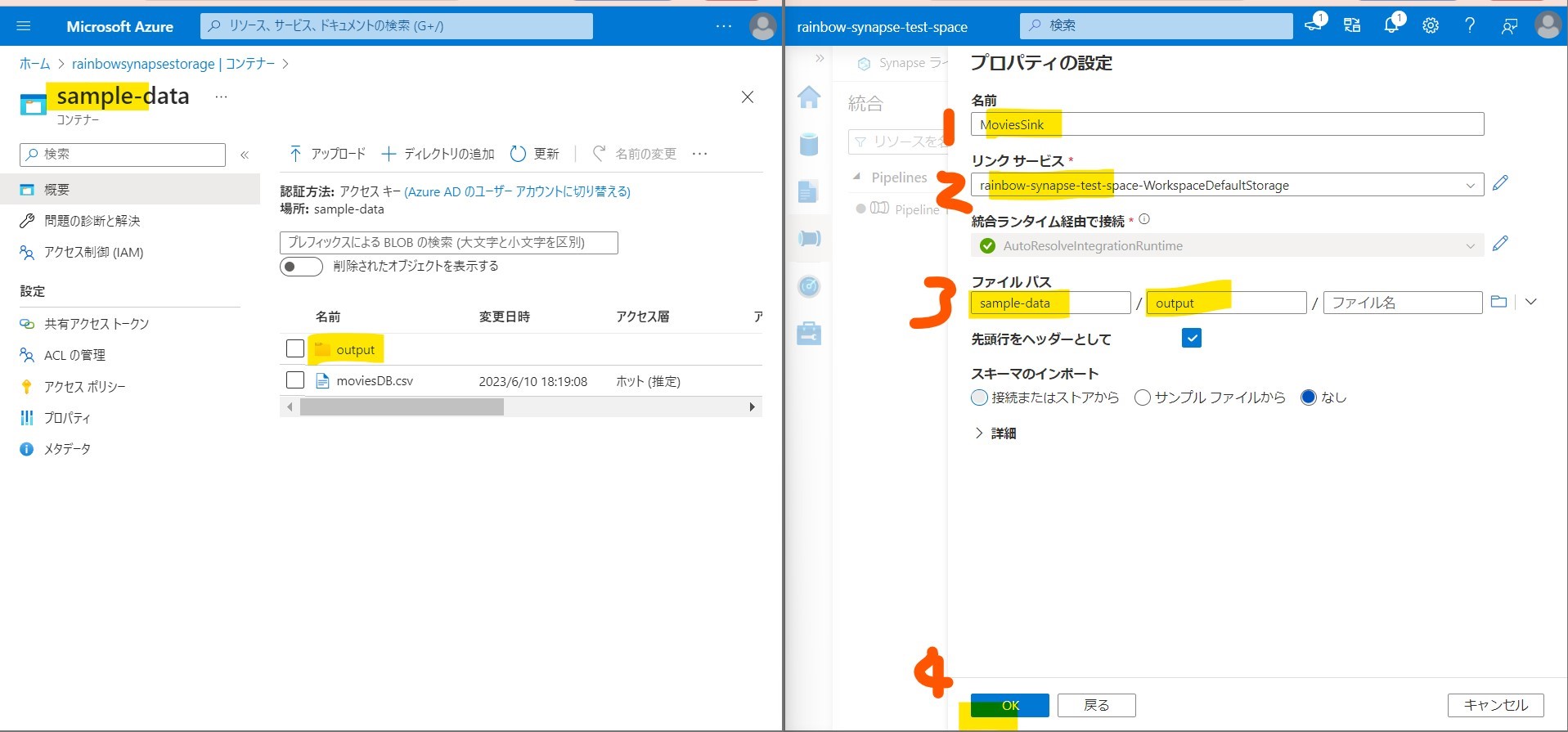
STEP3-5:「シンク」の設定
目的地(ターゲットデータソース)に同期する。
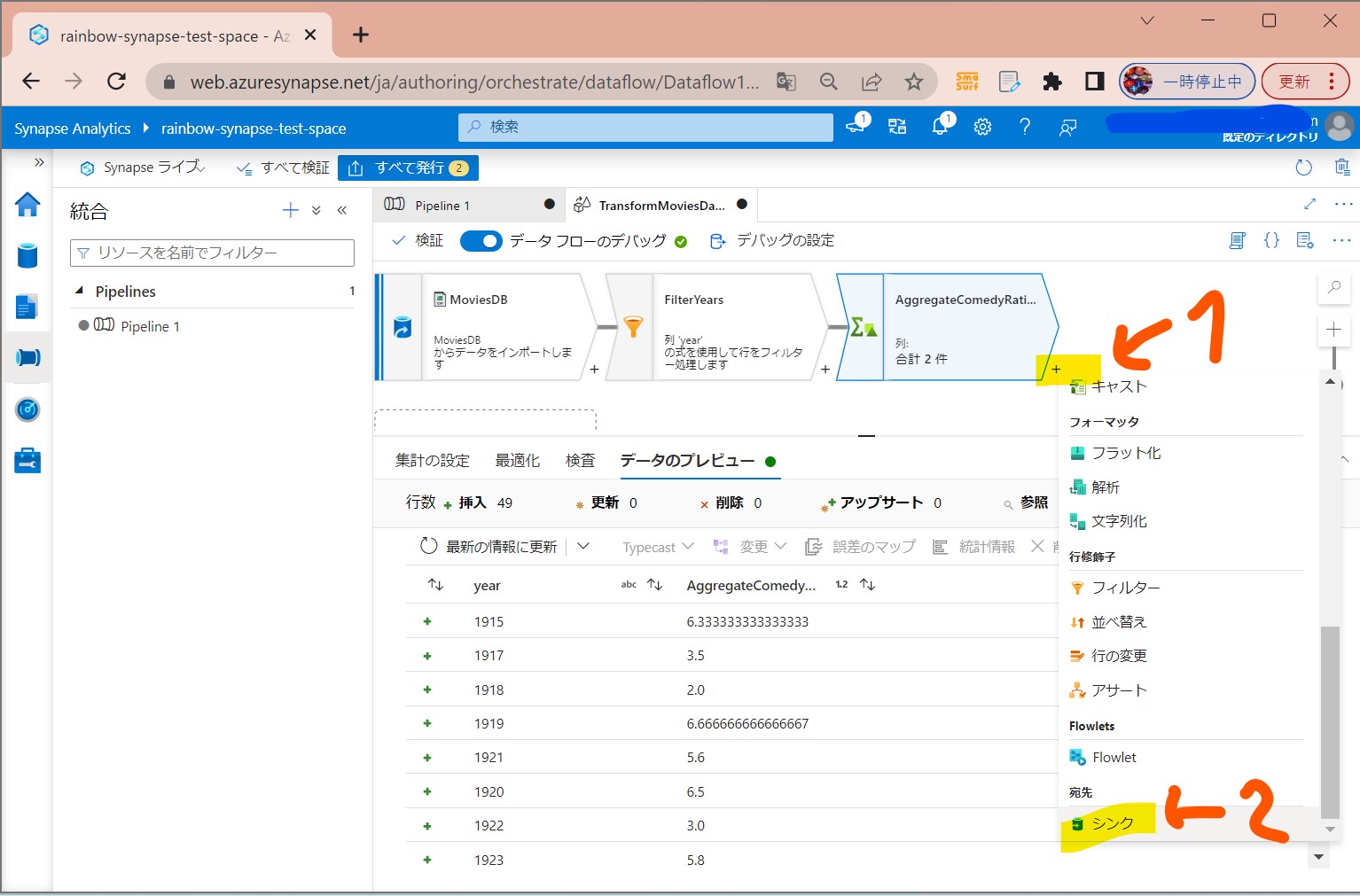
・①「+」→「シンク」
(図241)
↓
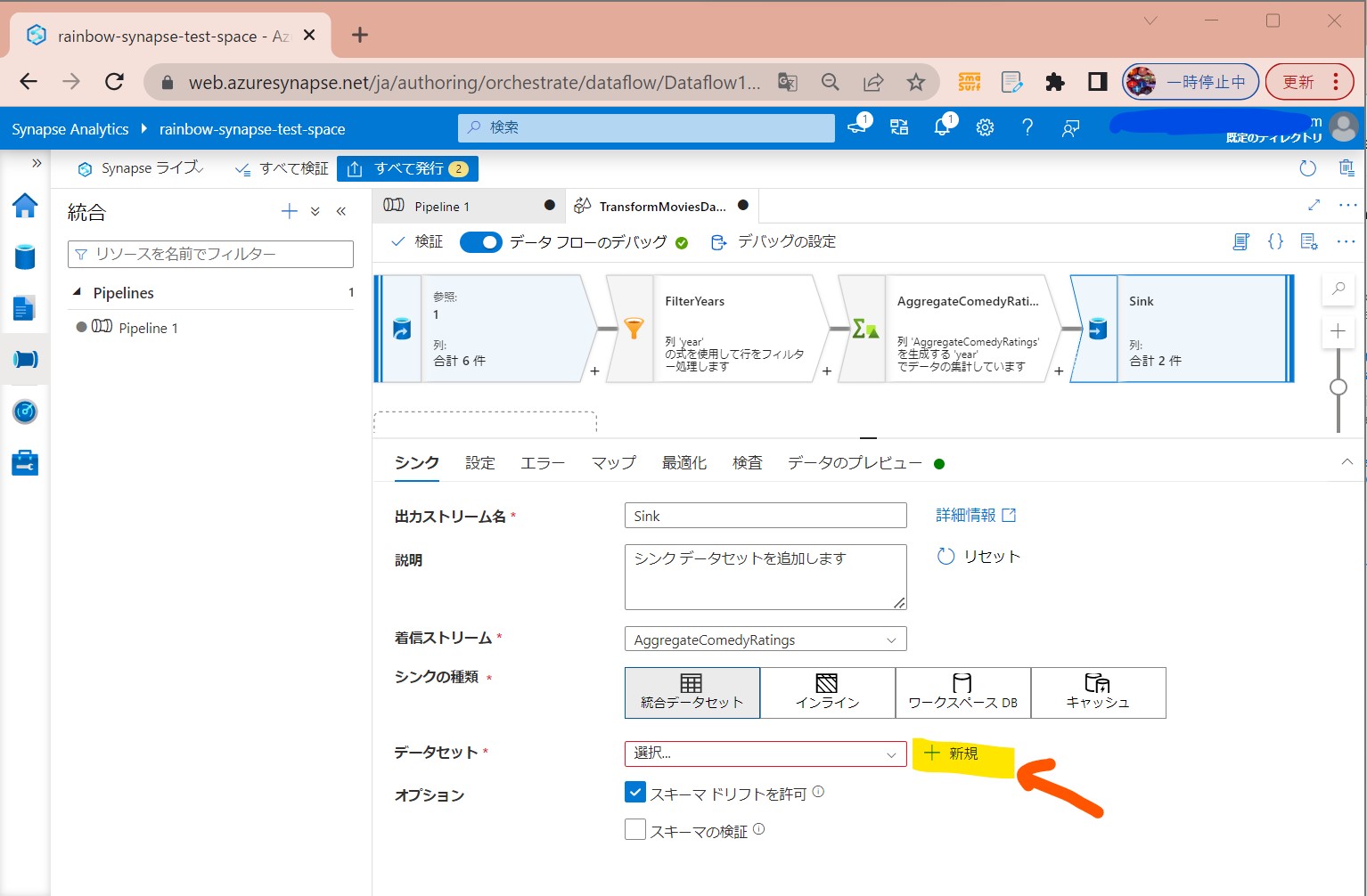
・②「データセット」→「+新規」
(図242)
↓
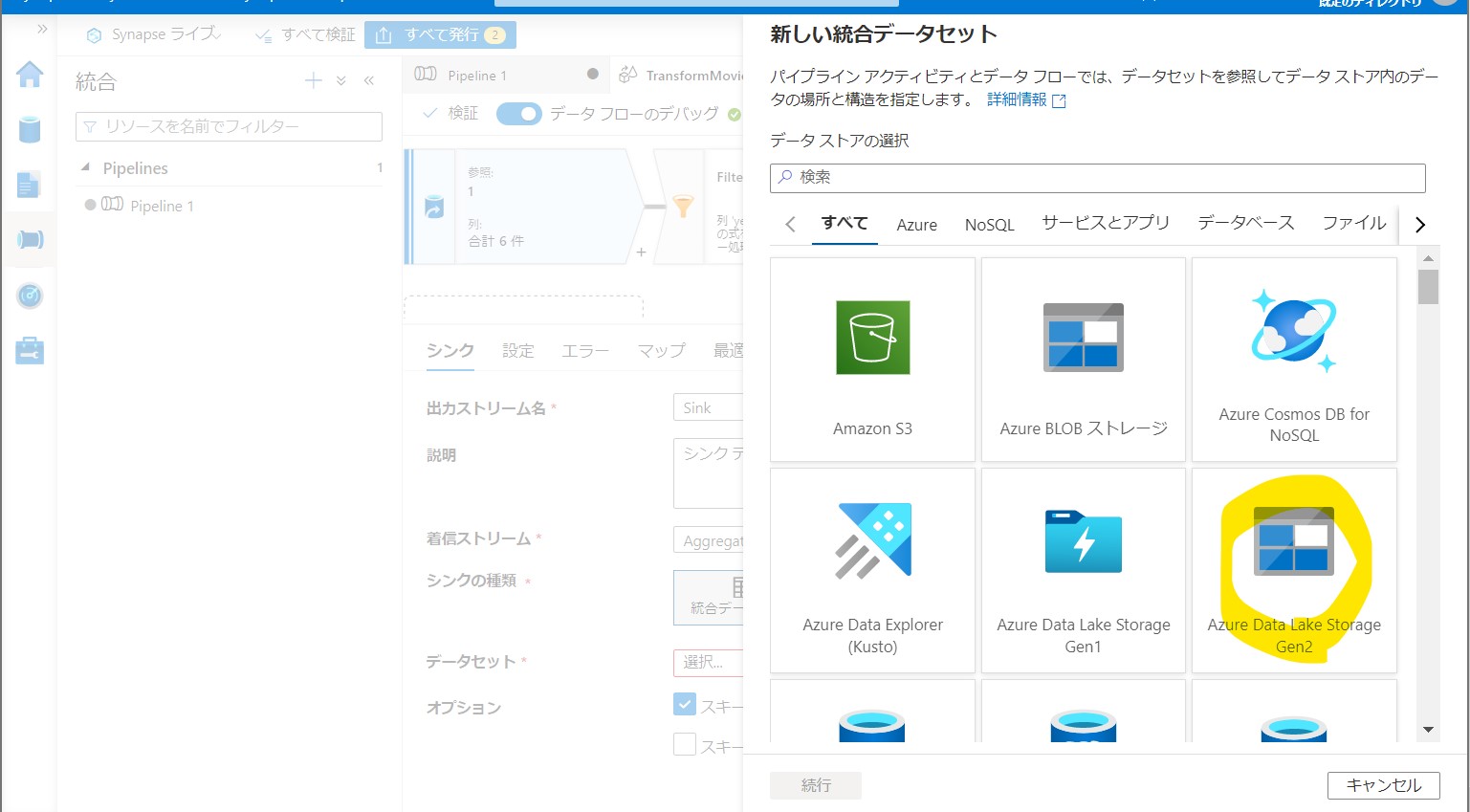
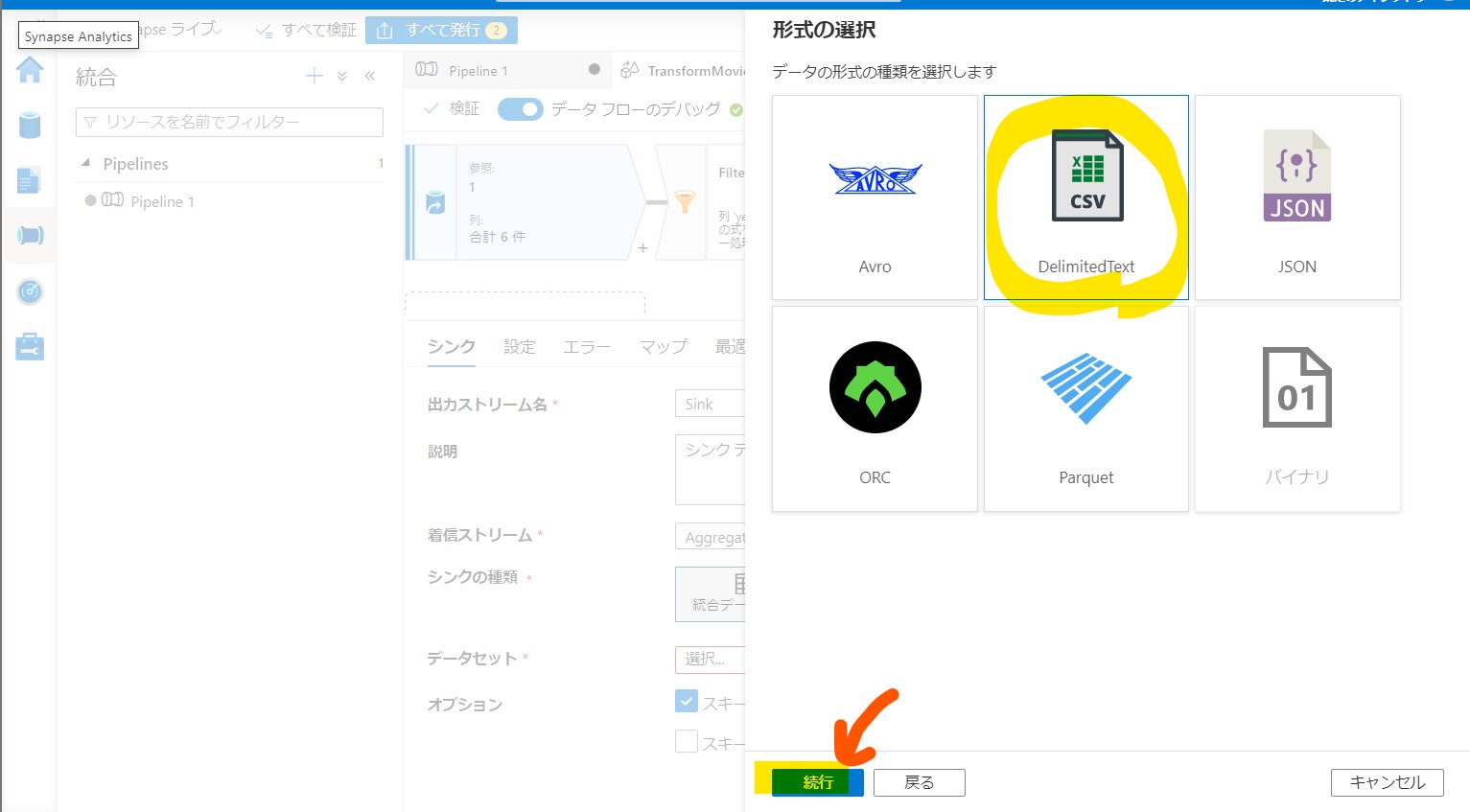
・③「Azure Data Lake Storage Gen2」→「Delimited Text」
(図243①②)
↓
・④出力条件の設定
(図244)
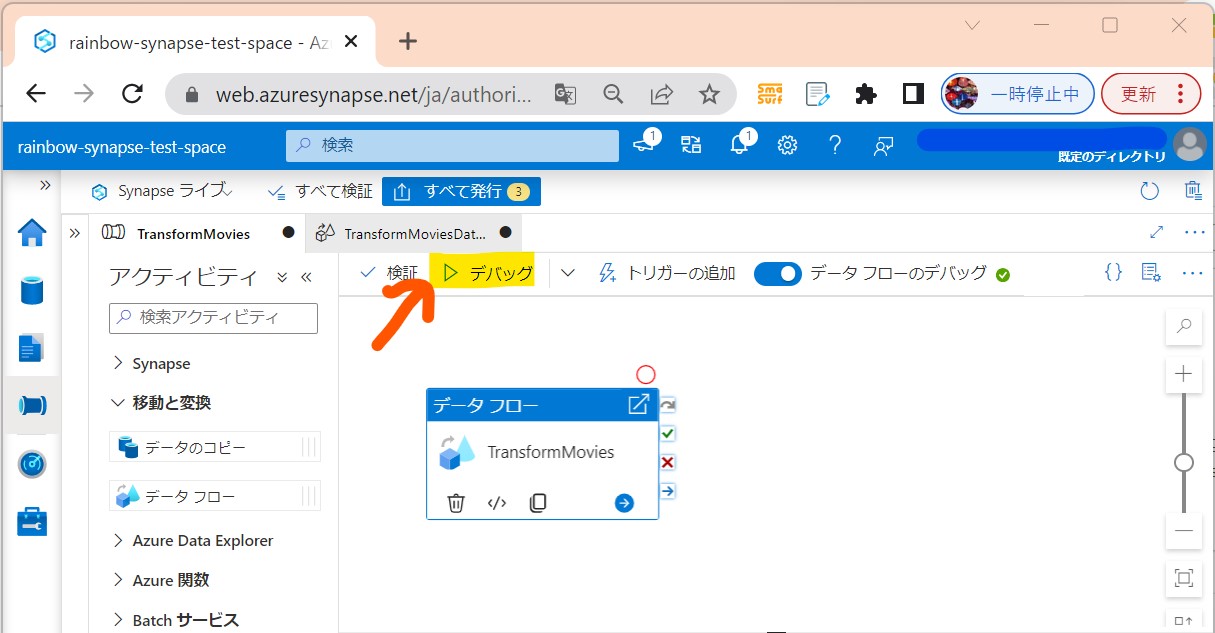
STEP4:データフローの実行とモニタリング
・①「デバッグ」
(図311)
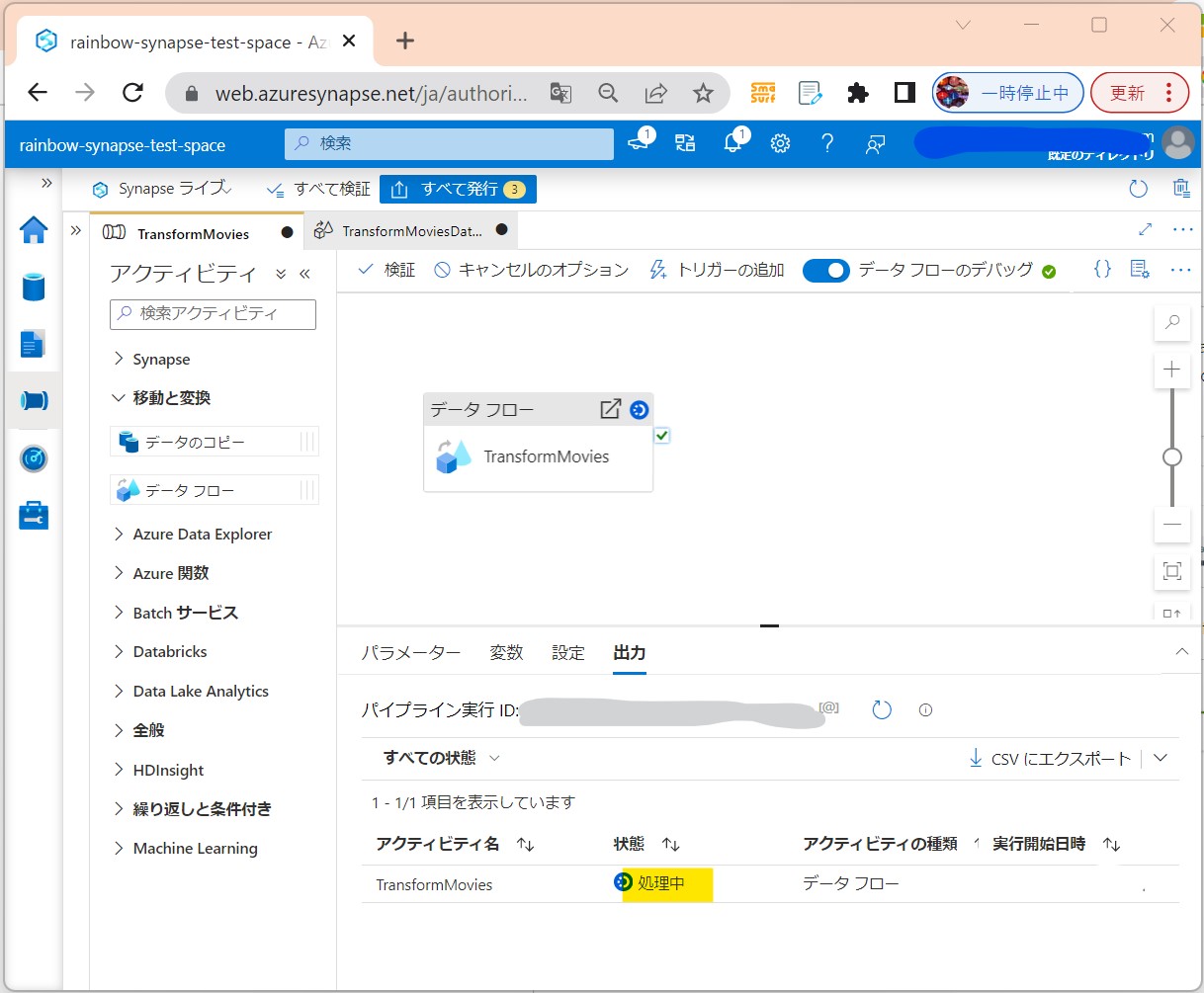
↓
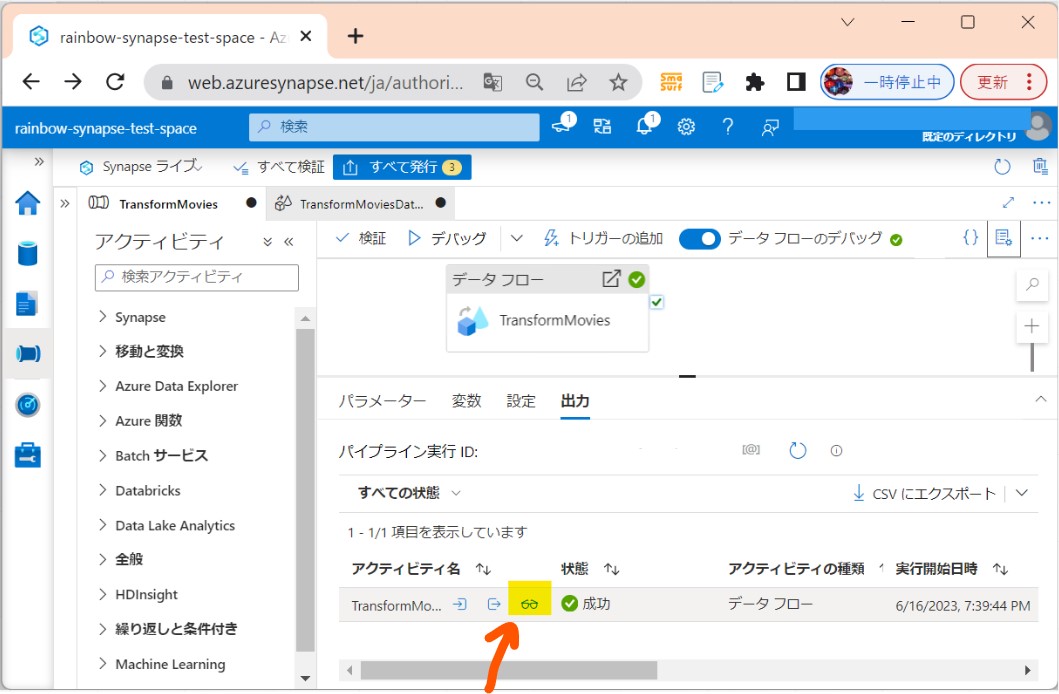
・②出力タブで状況チェック(処理中→成功)
(図312①②)
↓
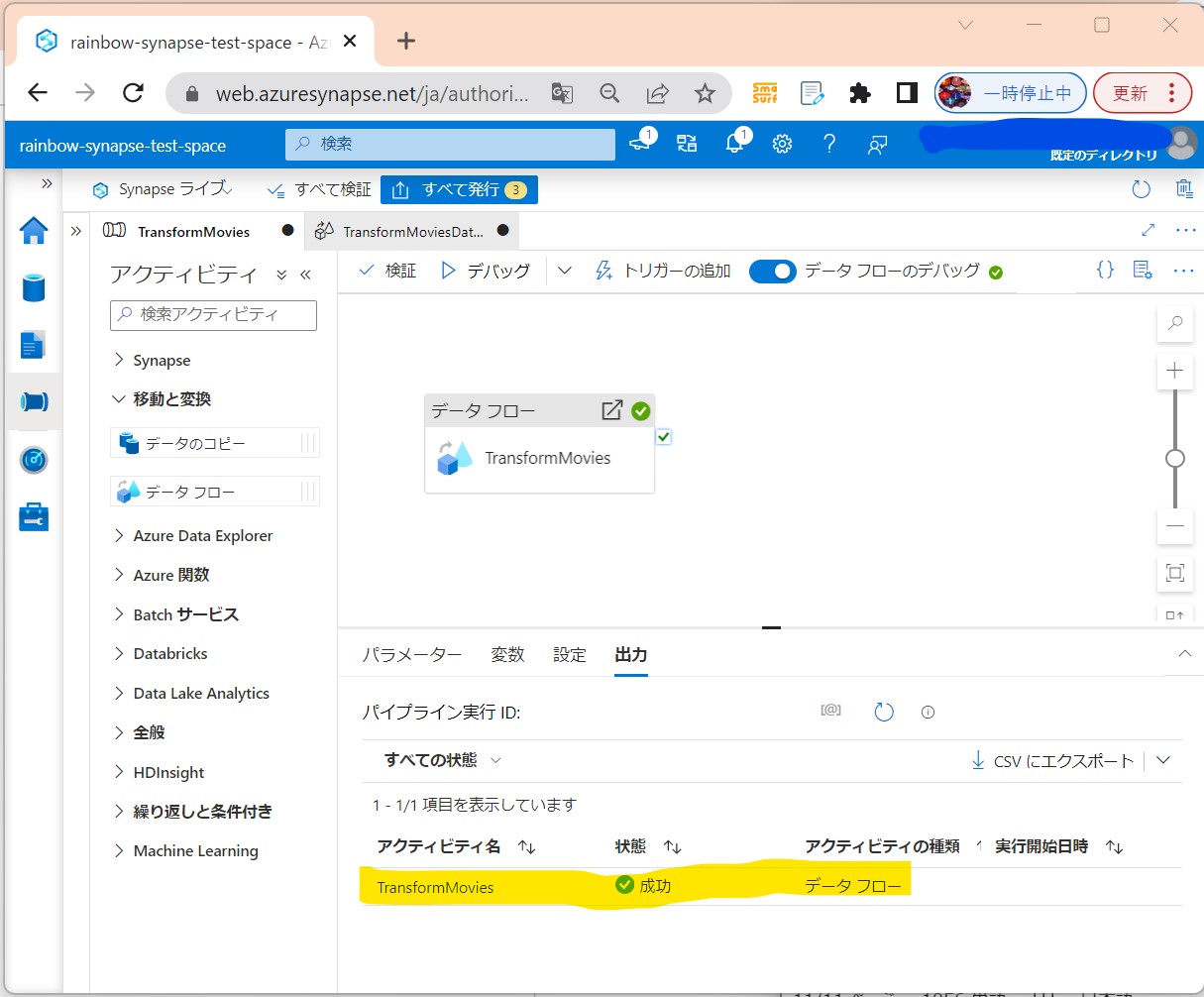
↓
・③「眼鏡マーク」から詳細に飛びます。
(図313①②)
↓
【注意】Azure Synapse Analyticsの料金について
非常に強力な分、料金も他のAzureサービスと比較すると高いので、注意が必要。