<目次>
(1) Base64のプログラムのサンプル(C++言語)と解説
(1-1) Base64とは?
(1-2) Base64のプログラム例(C++)
(1) Base64のプログラムのサンプル(C++言語)と解説
(1-1) Base64とは?
⇒(参考)Base64とは?概要やアルゴリズムについてご紹介
(1-2) Base64のプログラム例(C++)
早速ですが、Base64の実装例を見ていきます。今回は、既存のサイトのプログラムについてコメントを付加する形で解説を加えていますので、ご了承ください。
(引用元サイト)
(メソッド概要)
| base64_encode | ・引数でエンコード対象の文字列とその長さを受け取る ・while文で文字をループ ∟3文字読み込んだら、そのセットでエンコード処理を実施(4文字に変換) ∟変換後の結果(4文字)を結果用の変数に格納 ・最後の3文字セットが作れない端数部分のデコード処理があれば実行 |
| base64_decode | ・引数でエンコード結果を受け取る ・while文で文字をループ ∟4文字読み込んだら、そのセットでデコード処理を実施(3文字に変換) ∟変換後の結果(3文字)を結果用の変数に格納 ・最後の4文字セットが作れない端数部分のデコード処理があれば実行 |
| main | テスト用のmainメソッド |
(サンプル)
/*
・本ソースコードは下記サイトより引用しています。
(変数:base64_chars、メソッド:base64_encode、base64_decode)
https://renenyffenegger.ch/notes/development/Base64/Encoding-and-decoding-base-64-with-cpp/index#cpp-base64-h
・コメントについては全て"rainbow-engine.com"にて追記をしています。
・テスト用のmainメソッドについては"rainbow-engine.com"にて作成をしています。
*/
#include <iostream>
#include <sstream>
using namespace std;
static const string base64_chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
static inline bool is_base64(unsigned char c) {
return (isalnum(c) || (c == '+') || (c == '/'));
}
//# エンコードメソッド
//# 第一引数: Base64のエンコード対象の文字列
//# 第二引数: Base64のエンコード対象の文字列の長さ
string base64_encode(unsigned char const* bytes_to_encode, unsigned int in_len) {
//# 結果格納用の変数
string ret;
//# ループ用の変数
int i = 0;
int j = 0;
//# 「_3」はBase64変換前の文字セット(8bit×3=24bit)
//# 「_4」はBase64変換後の文字セット(6bit×4=24bit)
unsigned char char_array_3[3];
unsigned char char_array_4[4];
//# 入力文字列の文字数だけwhileで繰り返す(in_len--)
while (in_len--) {
//# Base64変換前の文字セット(8bit×3=24bit)に、入力の文字を1文字格納する
char_array_3[i++] = *(bytes_to_encode++);
//# 3の倍数でBase64エンコード変換を実施
if (i == 3) {
//# [00000011] [11112222] [22333333]の形で3バイトを6ビット毎に分割し、4バイトに再格納
//# 「& 0xXX」はマスクで、例えば「0xfc」なら「11111100」で先頭6ビットのみ残して、残りは切り落とす
//# 「>> N」や「<< N」はビットシフト演算子で、ビット内のバイトを右や左にズラします。
//# ⇒詳細は次で紹介する「値出力」版のプログラムを見ると、より理解が深まります。
char_array_4[0] = (char_array_3[0] & 0xfc) >> 2;
char_array_4[1] = ((char_array_3[0] & 0x03) << 4) + ((char_array_3[1] & 0xf0) >> 4);
char_array_4[2] = ((char_array_3[1] & 0x0f) << 2) + ((char_array_3[2] & 0xc0) >> 6);
char_array_4[3] = char_array_3[2] & 0x3f;
//# Base64の変換表に沿って、変換後の文字列を結果変数(ret)に格納
for(i = 0; (i <4) ; i++)
ret += base64_chars[char_array_4[i]];
//# 次の3文字セットのループに移るため、iの値をリセット
i = 0;
}
}
//# while文を抜けて、もし「i」が0でない場合
//# ⇒これ以上3の倍数が作れずに1文字or2文字で余った場合に、この分岐に突入
if (i)
{
//# 端数で3文字に満たない部分はゼロ埋め
for(j = i; j < 3; j++)
char_array_3[j] = '\0';
//# 3の倍数の時と同じ処理(8ビット×3組 →6ビット×4組へ変換 →8ビット×4組へ補完)を実施
char_array_4[0] = (char_array_3[0] & 0xfc) >> 2;
char_array_4[1] = ((char_array_3[0] & 0x03) << 4) + ((char_array_3[1] & 0xf0) >> 4);
char_array_4[2] = ((char_array_3[1] & 0x0f) << 2) + ((char_array_3[2] & 0xc0) >> 6);
char_array_4[3] = char_array_3[2] & 0x3f;
//# Base64の変換表に沿って、変換後の文字列を結果変数(ret)に格納
for (j = 0; (j < i + 1); j++)
ret += base64_chars[char_array_4[j]];
//# 8ビットが全て「0」埋めされているchar_array_4は「'='」で埋める
while((i++ < 3))
ret += '=';
}
return ret;
}
//# デコードメソッド
//# 第一引数: Base64のエンコード結果の文字列
string base64_decode(string const& encoded_string) {
//# エンコード結果の文字列の長さを取得
int in_len = encoded_string.size();
//# ループ用の変数
int i = 0;
int j = 0;
int in_ = 0;
//# 「_4」はBase64変換後のエンコード済み文字セット(6bit×4=24bit)
//# 「_3」はBase64変換前のデコード済み文字セット(8bit×3=24bit)
unsigned char char_array_4[4], char_array_3[3];
//# 結果格納用の変数
string ret;
//# 入力文字列の文字数だけwhileで繰り返す(in_len--) かつ 文字が'='でない場合
while (in_len-- && ( encoded_string[in_] != '=') && is_base64(encoded_string[in_])) {
//# Base64変換後の文字セット(8bit×4=32bit)に、入力の文字を1文字格納する
char_array_4[i++] = encoded_string[in_]; in_++;
//# 4の倍数でBase64のデコード変換を実施
if (i ==4) {
for (i = 0; i <4; i++)
char_array_4[i] = base64_chars.find(char_array_4[i]);
//# エンコード時の逆の処理を実施
char_array_3[0] = (char_array_4[0] << 2) + ((char_array_4[1] & 0x30) >> 4);
char_array_3[1] = ((char_array_4[1] & 0xf) << 4) + ((char_array_4[2] & 0x3c) >> 2);
char_array_3[2] = ((char_array_4[2] & 0x3) << 6) + char_array_4[3];
//# 変換後の文字列を結果変数(ret)に格納
for (i = 0; (i < 3); i++)
ret += char_array_3[i];
//# 次の3文字セットのループに移るため、iの値をリセット
i = 0;
}
}
//# もし「i」が0でない場合で「'='」にぶつかった場合
//# ⇒これ以上4の倍数が作れずに1文字or2文字or3文字で余った場合に、この分岐に突入
if (i) {
for (j = i; j <4; j++)
char_array_4[j] = 0;
for (j = 0; j <4; j++)
char_array_4[j] = base64_chars.find(char_array_4[j]);
//# エンコード時の逆の処理を実施
char_array_3[0] = (char_array_4[0] << 2) + ((char_array_4[1] & 0x30) >> 4);
char_array_3[1] = ((char_array_4[1] & 0xf) << 4) + ((char_array_4[2] & 0x3c) >> 2);
char_array_3[2] = ((char_array_4[2] & 0x3) << 6) + char_array_4[3];
for (j = 0; (j < i - 1); j++) ret += char_array_3[j];
}
return ret;
}
//#################################
//# RainbowPlanet独自追加
//# テスト用のmainメソッド
//# 「unsigned char input_str[]」の値を自由に変えて使って見てください
//#################################
int main(void){
//# 文字列リテラルは「const char[X]」型になる。
//# 更に「unsigned」が付いているため、「unsigned const char[X]」になる
unsigned char input_str[] = "RainbowEngine";
//unsigned char* input_str_ptr = input_str;
int len_str;
//# 文字列の長さを計算
//# [文字列全体の長さ] / [文字列1文字目の長さ]
len_str = sizeof(input_str) / sizeof(input_str[0]);
//# 終端文字(ヌル文字)の除去
len_str -= 1;
cout <<"(1)入力文字列 : "<< input_str << endl;
cout <<"(2)エンコード後文字列 : "<< base64_encode(input_str, len_str)<< endl;
cout <<"(3)デコード後文字列 : "<< base64_decode(base64_encode(input_str, len_str))<< endl;
}
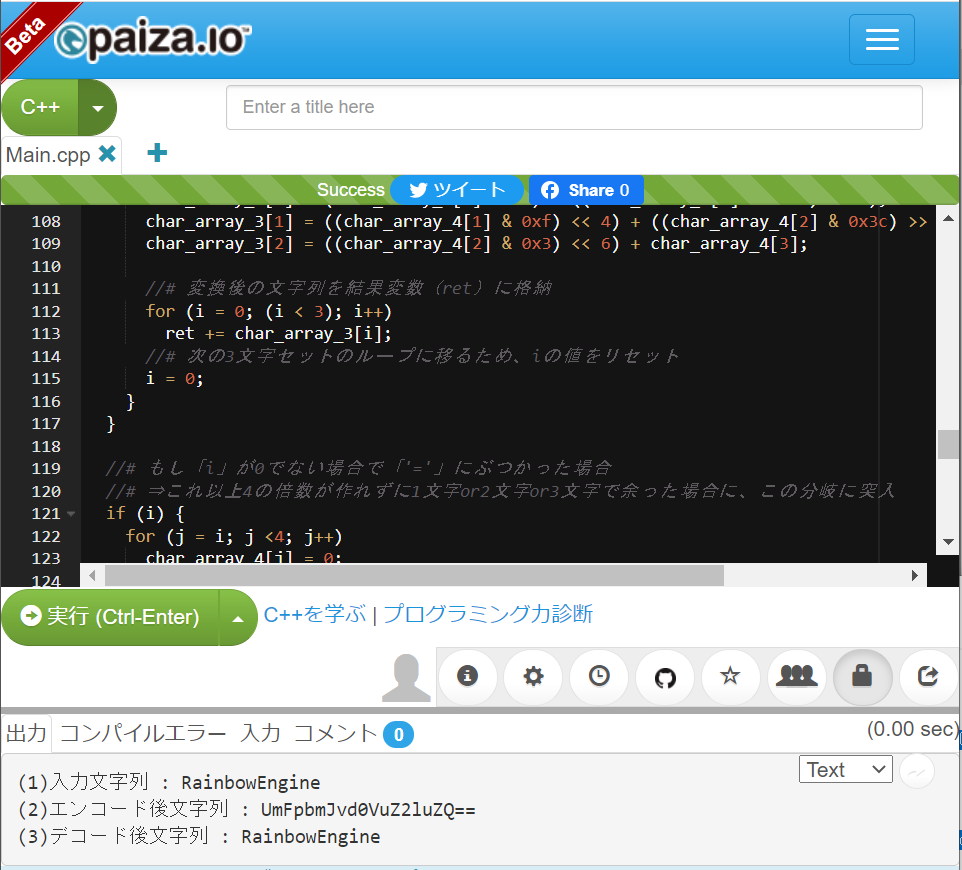
(図111)実行結果
エンコードの例です。「RainbowEngine」を入力し、エンコードすると「UmFpbmJvd0VuZ2luZQ==」になり
その後またデコードして戻すと「RainbowEngine」に戻る事が確認できました。
エンコードの例です。「RainbowEngine」を入力し、エンコードすると「UmFpbmJvd0VuZ2luZQ==」になり
その後またデコードして戻すと「RainbowEngine」に戻る事が確認できました。
●値を細かく出力して流れを追う
Base64のエンコード、デコードはビットの「マスク」や「シフト」を多分に用いるため、ソースだけを追っていると非常にイメージしにくい部分があります。そのため、値をcoutやprintして追って見たのが以下のプログラムです。
(サンプル)
/*
・本ソースコードは下記サイトより引用しています。
(変数:base64_chars、メソッド:base64_encode、base64_decode)
https://renenyffenegger.ch/notes/development/Base64/Encoding-and-decoding-base-64-with-cpp/index#cpp-base64-h
・コメントについては全て"rainbow-engine.com"にて追記をしています。
・テスト用のmainメソッドについては"rainbow-engine.com"にて作成をしています。
*/
#include <iostream>
#include <sstream>
#include <bitset>
using namespace std;
static const string base64_chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
static inline bool is_base64(unsigned char c) {
return (isalnum(c) || (c == '+') || (c == '/'));
}
//# エンコードメソッド
//# 第一引数: Base64のエンコード対象の文字列
//# 第二引数: Base64のエンコード対象の文字列の長さ
string base64_encode(unsigned char const* bytes_to_encode, unsigned int in_len) {
//# 結果格納用の変数
string ret;
//# ループ用の変数
int i = 0;
int j = 0;
//# 「_3」はBase64変換前の文字セット(8bit×3=24bit)
//# 「_4」はBase64変換後の文字セット(6bit×4=24bit)
unsigned char char_array_3[3];
unsigned char char_array_4[4];
//# 入力文字列の文字数だけwhileで繰り返す(in_len--)
while (in_len--) {
cout << "===LOOP:" << in_len << " i=" << i << " char_array_3[" << i << "] : " << *(bytes_to_encode) << endl;
//# Base64変換前の文字セット(8bit×3=24bit)に、入力の文字を1文字格納する
char_array_3[i++] = *(bytes_to_encode++);
//# 3の倍数でBase64エンコード変換を実施
if (i == 3) {
//# char_array_3[0]= 01010010 ⇒1文字目のバイト[R]
//# char_array_3[0] & 0xfc = 01010010 & 11111100(マスク) = 01010000
//# (char_array_3[0] & 0xfc) >> 2 = 00010100 ⇒1文字目のバイトの最初の6ビットを取得し、2ビット右にシフト
char_array_4[0] = (char_array_3[0] & 0xfc) >> 2;
//# 値の出力確認
bitset<8> char_array_4_1(char_array_4[0]);
bitset<8> char_array_3_1(char_array_3[0] & 0xfc); //# 1バイト目の先頭6ビット
cout << "====== char_array_4[0]= " << char_array_4_1 << " char_array_3_1= " << char_array_3_1 << endl;
//# char_array_3[0]= 01010010 ⇒1文字目のバイト[R]
//# char_array_3[0] & 0x03 = 01010010 & 00000011(マスク) = 00000010
//# (char_array_3[0] & 0x03) >> 4 = 00100000 ⇒1文字目のバイトの末尾の2ビットを取得し、4ビット左にシフト
//# char_array_3[1]= 01100001 ⇒2文字目のバイト[a]
//# char_array_3[1] & 0xf0 = 01100001 & 11110000(マスク) = 01100000
//# (char_array_3[1] & 0xf0) >> 4 = 00000110 ⇒2文字目のバイトの最初の4ビットを取得し、4ビット右にシフト
char_array_4[1] = ((char_array_3[0] & 0x03) << 4) + ((char_array_3[1] & 0xf0) >> 4);
//# 値の出力確認
bitset<8> char_array_4_2(char_array_4[1]);
bitset<8> char_array_3_2_1(char_array_3[0] & 0x03); //# 1バイト目の末尾2ビット
bitset<8> char_array_3_2_2(char_array_3[1] & 0xf0); //# 2バイト目の先頭4ビット
cout << "====== char_array_4[1]= " << char_array_4_2 << " char_array_3_2_1= " << char_array_3_2_1 << " char_array_3_2_2= " << char_array_3_2_2 << endl;
//# char_array_3[1]= 01100001 ⇒2文字目のバイト[a]
//# char_array_3[1] & 0x0f = 01100001 & 00001111(マスク) = 00000001
//# (char_array_3[1] & 0x0f) << 2 = 00000100 ⇒2文字目のバイトの末尾の4ビットを取得し、2ビット左にシフト
//# char_array_3[2]= 01101001 ⇒2文字目のバイト[i]
//# char_array_3[2] & 0xc0 = 01101001 & 11000000(マスク) = 01000000
//# (char_array_3[2] & 0xc0) >> 6 = 00000001 ⇒3文字目のバイトの最初の2ビットを取得し、6ビット右にシフト
char_array_4[2] = ((char_array_3[1] & 0x0f) << 2) + ((char_array_3[2] & 0xc0) >> 6);
//# 値の出力確認
bitset<8> char_array_4_3(char_array_4[2]);
bitset<8> char_array_3_3_1(char_array_3[1] & 0x0f); //# 2バイト目の末尾4ビット
bitset<8> char_array_3_3_2(char_array_3[2] & 0xc0); //# 3バイト目の先頭2ビット
cout << "====== char_array_4[2]= " << char_array_4_3 << " char_array_3_3_1= " << char_array_3_3_1 << " char_array_3_3_2= " << char_array_3_3_2 << endl;
//# char_array_3[2]= 01101001 ⇒2文字目のバイト[i]
//# char_array_3[2] & 0x3f = 01101001 & 00111111(マスク) = 00101001
//# char_array_3[2] & 0x3f ⇒3文字目のバイトの末尾の6ビットを取得する
char_array_4[3] = char_array_3[2] & 0x3f;
//# 値の出力確認
bitset<8> char_array_4_4(char_array_4[3]);
cout << "====== char_array_4[3]= " << char_array_4_4 << endl;
//# 変換後の文字列を結果変数(ret)に格納
for(i = 0; (i <4) ; i++)
ret += base64_chars[char_array_4[i]];
//# 次の3文字セットのループに移るため、iの値をリセット
i = 0;
}
}
//# while文を抜けて、もし「i」が0でない場合
//# ⇒これ以上3の倍数が作れずに1文字or2文字で余った場合に、この分岐に突入
if (i)
{
//# 端数で3文字に満たない部分はゼロ埋め
//# RainbowEngineの例では、[0]=e、[1]=0埋め、[2]=0埋めとなる
for(j = i; j < 3; j++){
char_array_3[j] = '\0';
cout << "======== j= " << j << " char_array_3[j]:" << char_array_3[j] << endl;
}
//# 3の倍数の時と同じ処理(8ビット×3組 →6ビット×4組へ変換 →8ビット×4組へ補完)を実施
char_array_4[0] = (char_array_3[0] & 0xfc) >> 2;
char_array_4[1] = ((char_array_3[0] & 0x03) << 4) + ((char_array_3[1] & 0xf0) >> 4);
char_array_4[2] = ((char_array_3[1] & 0x0f) << 2) + ((char_array_3[2] & 0xc0) >> 6);
char_array_4[3] = char_array_3[2] & 0x3f;
//# Base64の変換表に沿って、変換後の文字列を結果変数(ret)に格納
for (j = 0; (j < i + 1); j++){
ret += base64_chars[char_array_4[j]];
cout << "========== j=" << j << " ret:" << ret << endl;
}
//# 8ビットが全て「0」埋めされているchar_array_4は「'='」で埋める
while((i++ < 3))
ret += '=';
}
return ret;
}
//# デコードメソッド
//# 第一引数: Base64のエンコード結果の文字列
string base64_decode(string const& encoded_string) {
//# エンコード結果の文字列の長さを取得
int in_len = encoded_string.size();
//# ループ用の変数
int i = 0;
int j = 0;
int in_ = 0;
//# 「_4」はBase64変換後のエンコード済み文字セット(6bit×4=24bit)
//# 「_3」はBase64変換前のデコード済み文字セット(8bit×3=24bit)
unsigned char char_array_4[4], char_array_3[3];
//# 結果格納用の変数
string ret;
//# 入力文字列の文字数だけwhileで繰り返す(in_len--) かつ 文字が'='でない場合
while (in_len-- && ( encoded_string[in_] != '=') && is_base64(encoded_string[in_])) {
cout << "===LOOP:" << in_len << " i=" << i << " char_array_4[" << i << "] : " << encoded_string[in_] << endl;
//# Base64変換後の文字セット(8bit×4=32bit)に、入力の文字を1文字格納する
char_array_4[i++] = encoded_string[in_]; in_++;
//# 4の倍数でBase64のデコード変換を実施
if (i ==4) {
for (i = 0; i <4; i++)
char_array_4[i] = base64_chars.find(char_array_4[i]);
//# エンコード時の逆の処理を実施
//# char_array_4[0]= 00010100 ⇒1文字目のバイト[U] →2ビット左シフト
//# char_array_4[1] & 0x30 = 00100110 & 00110000(マスク) = 00[10]0000 ⇒2文字目のバイト[m] →4ビット右シフト
char_array_3[0] = (char_array_4[0] << 2) + ((char_array_4[1] & 0x30) >> 4);
//# 値の出力確認
bitset<8> char_array_4_0(char_array_4[0]);
bitset<8> char_array_4_1_1(char_array_4[1] & 0x30);
bitset<8> char_array_3_0(char_array_3[0]);
cout << "====== char_array_3[0]= " << char_array_3_0 << " char_array_4_0= " << char_array_4_0 << " char_array_4_1_1= " << char_array_4_1_1 << endl;
//# char_array_4[1] & 0xf = 00100110 & 00001111(マスク) = 0000[0110] ⇒2文字目のバイト[m] →4ビット左シフト
//# char_array_4[2] & 0x30 = 00000101 & 00111100(マスク) = 00[0001]00 ⇒3文字目のバイト[F] →2ビット右シフト
char_array_3[1] = ((char_array_4[1] & 0xf) << 4) + ((char_array_4[2] & 0x3c) >> 2);
//# 値の出力確認
bitset<8> char_array_4_1_2(char_array_4[1] & 0xf);
bitset<8> char_array_4_2_1(char_array_4[2] & 0x3c);
bitset<8> char_array_3_1(char_array_3[1]);
cout << "====== char_array_3[1]= " << char_array_3_1 << " char_array_4_1_2= " << char_array_4_1_2 << " char_array_4_2_1= " << char_array_4_2_1 << endl;
//# char_array_4[2] & 0x30 = 00000101 & 00000011(マスク) = 000000[01] ⇒3文字目のバイト[F] →6ビット左シフト
//# char_array_4[3]= 00101001 ⇒4文字目のバイト[p]
char_array_3[2] = ((char_array_4[2] & 0x3) << 6) + char_array_4[3];
//# 値の出力確認
bitset<8> char_array_4_2_2(char_array_4[2] & 0x3);
bitset<8> char_array_4_3(char_array_4[3]);
bitset<8> char_array_3_2(char_array_3[2]);
cout << "====== char_array_3[2]= " << char_array_3_2 << " char_array_4_2_2= " << char_array_4_2_2 << " char_array_4_3= " << char_array_4_3 << endl;
//# 変換後の文字列を結果変数(ret)に格納
for (i = 0; (i < 3); i++)
ret += char_array_3[i];
//# 次の3文字セットのループに移るため、iの値をリセット
i = 0;
}
}
//# もし「i」が0でない場合で「'='」にぶつかった場合
//# ⇒これ以上4の倍数が作れずに1文字or2文字or3文字で余った場合に、この分岐に突入
if (i) {
for (j = i; j <4; j++)
char_array_4[j] = 0;
for (j = 0; j <4; j++)
char_array_4[j] = base64_chars.find(char_array_4[j]);
//# エンコード時の逆の処理を実施
char_array_3[0] = (char_array_4[0] << 2) + ((char_array_4[1] & 0x30) >> 4);
char_array_3[1] = ((char_array_4[1] & 0xf) << 4) + ((char_array_4[2] & 0x3c) >> 2);
char_array_3[2] = ((char_array_4[2] & 0x3) << 6) + char_array_4[3];
for (j = 0; (j < i - 1); j++) ret += char_array_3[j];
}
return ret;
}
int main(void){
//# 文字列リテラルは「const char[X]」型になる。
//# 更に「unsigned」が付いているため、「unsigned const char[X]」になる
unsigned char input_str[] = "RainbowEngine";
//unsigned char* input_str_ptr = input_str;
int len_str;
//# 文字列の長さを計算
//# [文字列全体の長さ] / [文字列1文字目の長さ]
len_str = sizeof(input_str) / sizeof(input_str[0]);
//# 終端文字(ヌル文字)の除去
len_str -= 1;
cout <<"(1)入力文字列 : "<< input_str << endl;
//cout <<"(2)エンコード後文字列 : " << endl << base64_encode(input_str, len_str)<< endl;
//cout <<"(3)デコード後文字列 : "<< base64_decode(base64_encode(input_str, len_str))<< endl;
cout <<"(3)デコード後文字列 : "<< endl << base64_decode("UmFpbmJvd0VuZ2luZQ==")<< endl;
}
(図121)実行結果
文字を1文字ずつ読み込み、U→m→F→pと4文字揃ったタイミングでデコード処理をしている様子がうかがえます。
文字を1文字ずつ読み込み、U→m→F→pと4文字揃ったタイミングでデコード処理をしている様子がうかがえます。