<目次>
fetch_openmlの使い方について
STEP1:データをダウンロードする
STEP2:データの形状を確認する
STEP3:データを加工する
STEP4:データを表示する
fetch_openmlの使い方について
機械学習のデータをダウンロードする際に使用するfetch_openmlの概要と基本的な使い方についてご紹介します。
<fetch_openmlの概要>
・fetch_openmlはOpenMLからデータをダウンロードするメソッドです。
・sklearn.datasetsモジュールをインポートして使います。
・OpenMLは機械学習の実験用のデータベースで、オンライン上から誰でも無料でアクセスできます。
STEP1:データをダウンロードする
・今回はOpenMLのmnist_784というデータセットをダウンロードします。
(図111)
・ダウンロードはfetch_openmlメソッドで行います。(data, target)を返却しますが、dataは画像データ(28×28)のピクセル情報、targetは正解値のデータです(例:数字の4の画像なら4)。今回はdataをmnist_X、targetをmnist_yとして受け取っています。
# データを「https://www.openml.org/d/554」からロードする
mnist_X, mnist_y = fetch_openml("mnist_784", version=1, data_home=".", return_X_y=True, as_frame=False)
(補足)
パラメータ「data_home」でデータのダウンロード先を指定しています。
「=”.”」でPythonモジュールと同じ階層にダウンロード。例えば、配下の「tmp」フォルダ内に入れたい場合は「=”.\tmp”」と記載します(\はエスケープするため二つ連結)
パラメータ「data_home」でデータのダウンロード先を指定しています。
「=”.”」でPythonモジュールと同じ階層にダウンロード。例えば、配下の「tmp」フォルダ内に入れたい場合は「=”.\tmp”」と記載します(\はエスケープするため二つ連結)
(参考)APIドキュメント
STEP2:データの形状を確認する
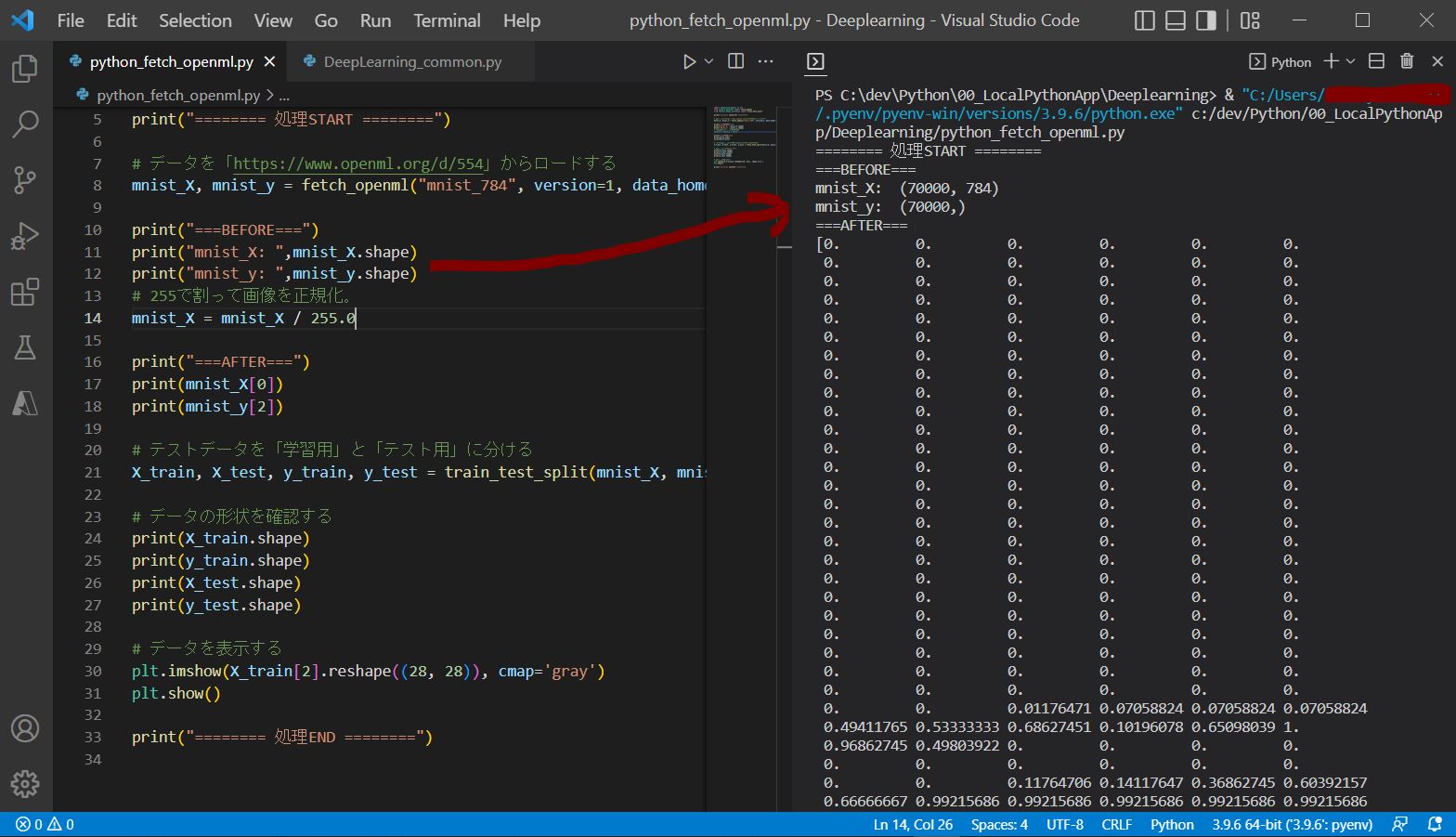
mnist_784の場合、ダウンロードしたデータは70000行(データ数)あり、この各行が画像データになっています。各行は784列(ピクセル数)あり、28×28ピクセルの画像データです。
(図120)

STEP3:データを加工する
fetch_openml関数で取得した値は255で割って正規化します(0~1の値にする)。正規化の目的として、値を小さくする事によりニューラルネットワーク上で扱いやすくする目的があります。
# 255で割って画像を正規化。 mnist_X = mnist_X / 255.0
ピクセルは2^8=255通りなので、255で割ると0~1の範囲に収まります。
STEP4:データを表示する
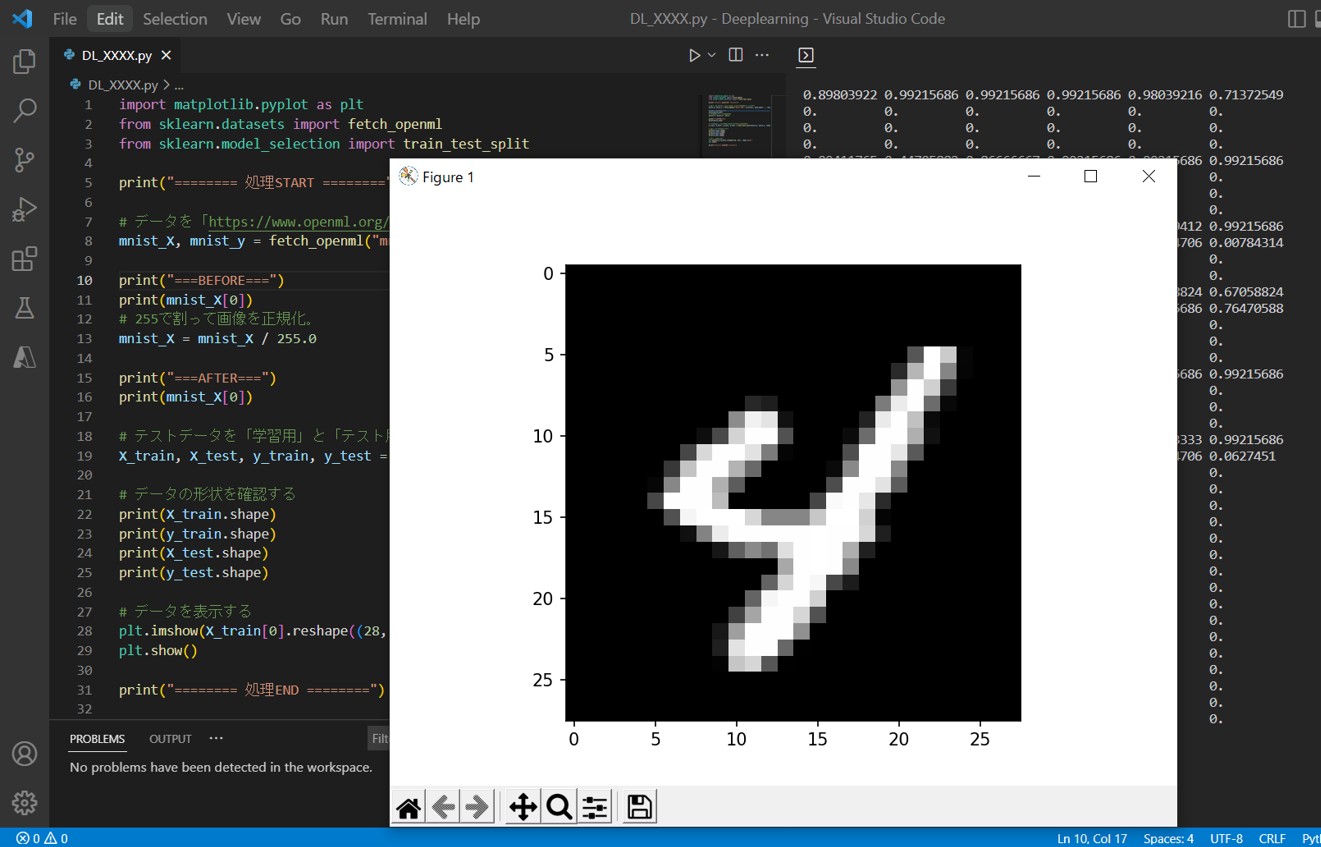
・matplotlibライブラリを使ってデータを表示します。
・imshowメソッドで画像として表示する事ができます。
・第1引数にピクセルデータを与えます。
・配列の784ピクセル分のデータをreshapeメソッドで、縦28×横28ピクセルに分解して与えます。
・cmap=’gray’でグレースケールデータに変更
・imshowメソッドで画像として表示する事ができます。
・第1引数にピクセルデータを与えます。
・配列の784ピクセル分のデータをreshapeメソッドで、縦28×横28ピクセルに分解して与えます。
・cmap=’gray’でグレースケールデータに変更
# データを表示する plt.imshow(X_train[0].reshape((28, 28)), cmap='gray') plt.show()
サンプルプログラム
上記STEP1~4を全て繋げたプログラムを掲載します。
(サンプルプログラム)
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
print("======== 処理START ========")
# データを「https://www.openml.org/d/554」からロードする
mnist_X, mnist_y = fetch_openml("mnist_784", version=1, data_home=".\\openml_data", return_X_y=True, as_frame=False)
print("===BEFORE===")
print(mnist_X[0])
# 255で割って画像を正規化。
mnist_X = mnist_X / 255.0
print("===AFTER===")
print(mnist_X[0])
# テストデータを「学習用」と「テスト用」に分ける
X_train, X_test, y_train, y_test = train_test_split(mnist_X, mnist_y, random_state=0, train_size=0.8)
# データの形状を確認する
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
# データを表示する
plt.imshow(X_train[0].reshape((28, 28)), cmap='gray')
plt.show()
print("======== 処理END ========")