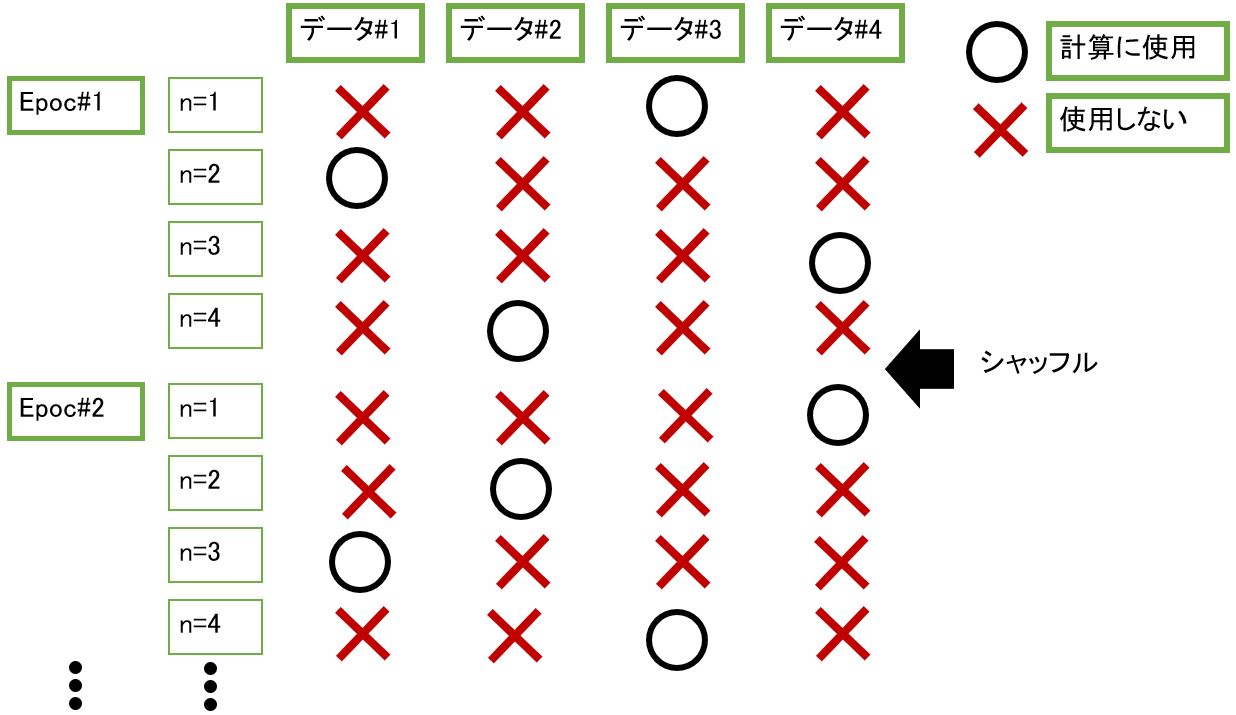
<目次>
(1) KerasのTokenizerの使い方(具体例付き)
KerasのTokenizerとは?
主な機能とインスタンス生成
(1-1) fit_on_texts の使い方
(1-2) texts_to_sequences の使い方
(1-3) texts_to_matrix(One-hot)の使い方
(1-4) KerasのTokenizerの挙動確認(Python)
(1) KerasのTokenizerの使い方(具体例付き)
KerasのTokenizerとは?
・データ(文章など)をトークン化(悪用可能な意味や値を持たない非機密値)する処理。
・これが文章の統計分析やDeep Learningにも使える。
主な機能とインスタンス生成
KerasのTokenizerの主な機能は以下の通りです。
- fit_on_texts:複数の文(sentences)を入力にして「辞書」を作成します。
- texts_to_sequences:「辞書」とテキストを突合して各単語のインデックス列へ変換します。
- texts_to_matrix:突合結果を行列へ変換します(One-hotなど)。
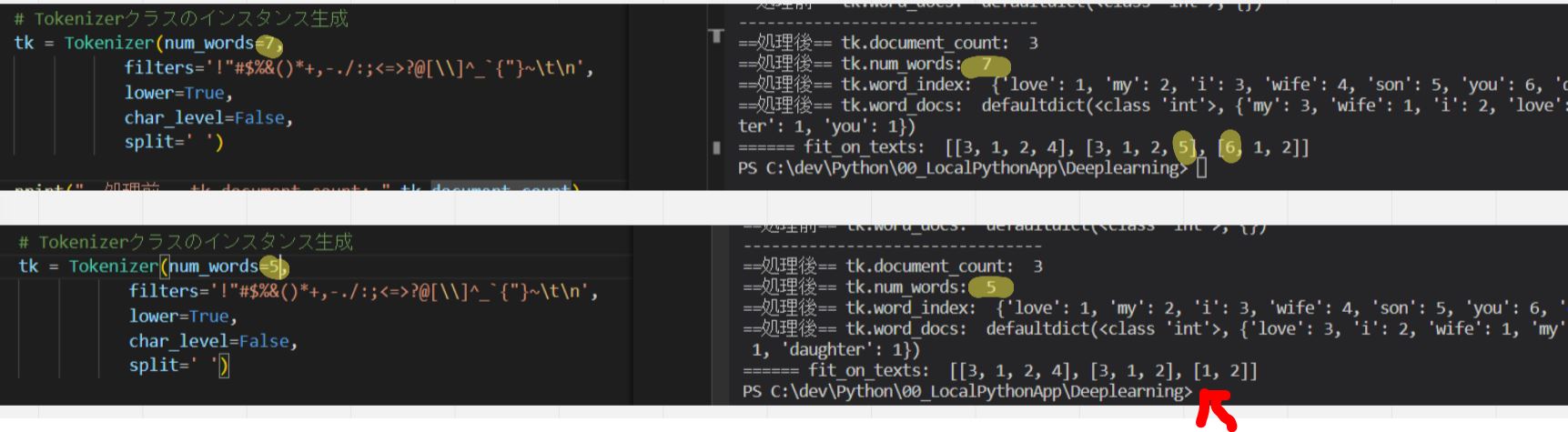
インスタンス生成時の主な引数例は以下です(num_words は「word_index」の序列の何番目の単語まで保持するかを指定)。
⇒詳しくは Tokenizer(Keras API) を参照。
(図123)
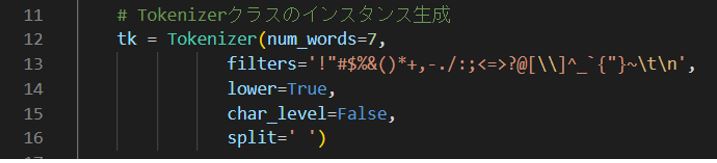
(図124)7⇒5にすると「’you’: 6」や「’daughter’: 7」は処理「texts_to_sequences」の対象外になる。
(1-1) fit_on_texts の使い方
STEP1-1:サンプル文から辞書を作成
メソッド「fit_on_texts」
・複数の文(sentences)を入力にして「辞書」を作ります。
(入力例)
sentences = [
'i love my wife',
'I, love my son',
'You love my daughter!'
]
(処理例)
・内部的には登場回数の集計や、それに応じたインデックス付与(word_index)も行っています。
・それらの情報はTokenizerのメンバーである「word_index」や「word_docs」で取得可能
(出力例)
tk.word_index
⇒{'love': 1, 'my': 2, 'i': 3, 'wife': 4, 'son': 5, 'you': 6, 'daughter': 7}
tk.word\_docs
⇒defaultdict(\, {'love': 3, 'my': 3, 'wife': 1, 'i': 2, 'son': 1, 'you': 1, 'daughter': 1})
(図121)
(1-2) texts_to_sequences の使い方
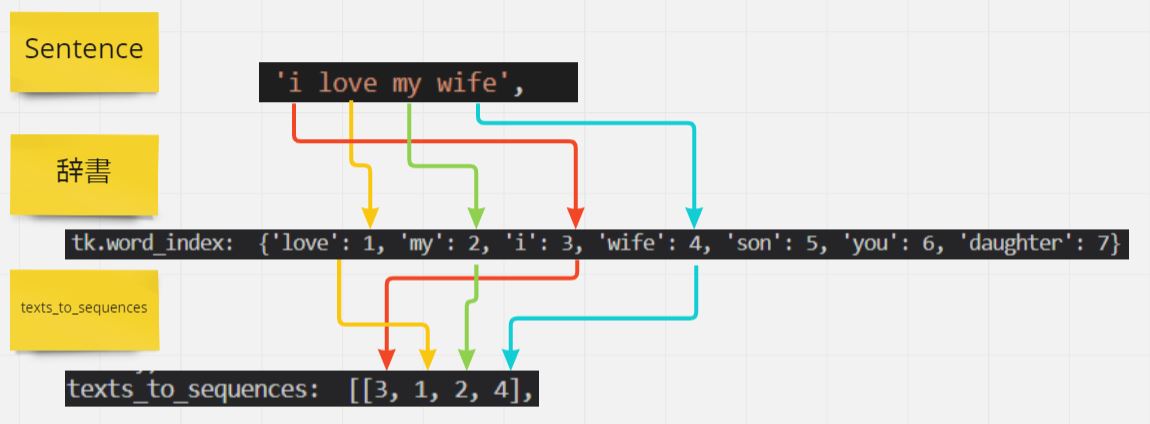
メソッド「texts_to_sequences」
・「辞書」と「テストデータ」を突合するメソッドです。
・基本的には「fit_on_texts」で作った辞書を入力にして使います。
・注意点として、引数は「リスト」形式のため [XXXXX] のように渡します。
(入力例)
・「fit_on_texts」の結果
・sentences = ['i love my wife', 'I, love my son', 'You love my daughter!']
(処理例)
・各文(sentence)ごとに辞書のindexと突合したマップを作成
(図122)
(出力例)
tk.texts_to_sequences(sentences) ⇒[[3, 1, 2, 4], [3, 1, 2, 5], [6, 1, 2]]
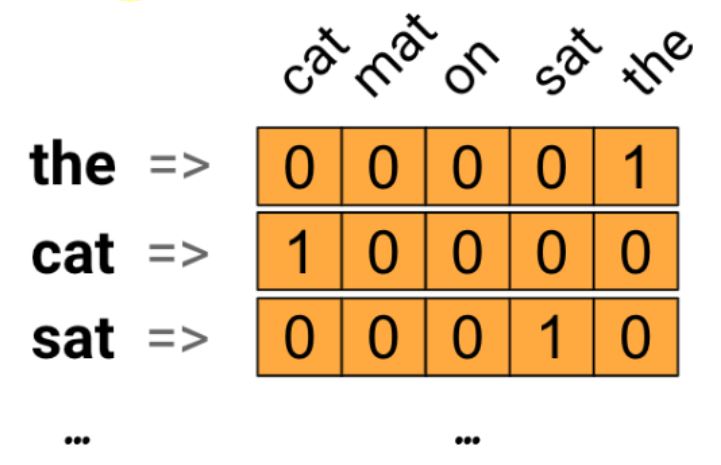
(1-3) texts_to_matrix(One-hot)の使い方
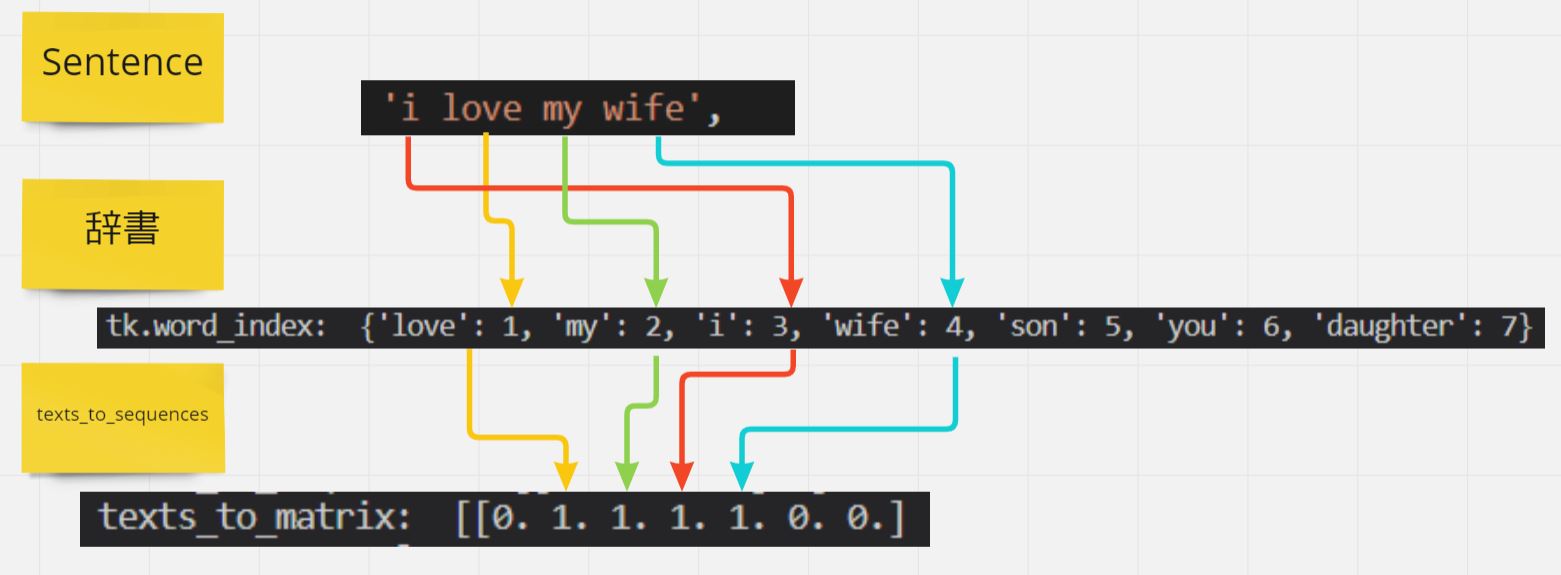
メソッド「texts_to_matrix」
・基本的には「fit_on_texts」で作った辞書を入力にして使います。
・突合結果として出来るマトリクスを「One-hot encoding」と呼びます。
・注意点として、引数は「リスト」形式のため [XXXXX] のように渡します。
(入力例)
・「fit_on_texts」の結果
・sentences = ['i love my wife', 'I, love my son', 'You love my daughter!']
(処理例)
・各文(sentence)ごとに辞書のindexと突合したマップを作成
(図126)
(出力例)
tk.texts_to_matrix(sentences) ⇒[[0. 1. 1. 1. 1. 0. 0.]
(図125)(参考)公式ページの図はこんな感じ
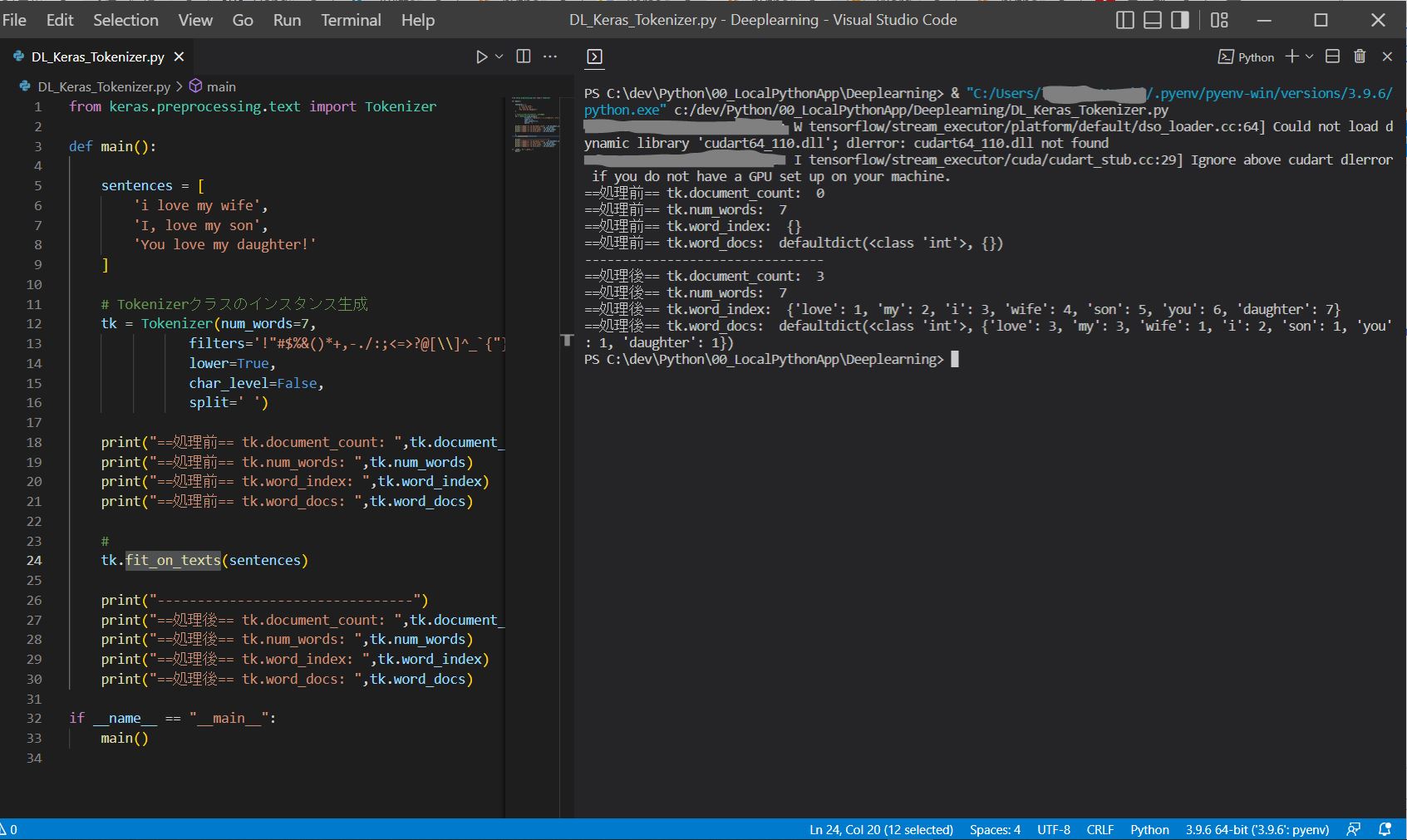
(1-4) KerasのTokenizerの挙動確認(Python)
from keras.preprocessing.text import Tokenizer
def main():
sentences = [
'i love my wife',
'I, love my son',
'You love my daughter!'
]
# Tokenizerクラスのインスタンス生成
tk = Tokenizer(num_words=7,
filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{"}~\t\n',
lower=True,
char_level=False,
split=' ')
print("==処理前== tk.document_count: ", tk.document_count)
print("==処理前== tk.num_words: ", tk.num_words)
print("==処理前== tk.word_index: ", tk.word_index)
print("==処理前== tk.word_docs: ", tk.word_docs)
# 複数の文(sentences)を入力にして「辞書」を作ります。
tk.fit_on_texts(sentences)
print("--------------------------------")
print("==処理後== tk.document_count: ", tk.document_count)
print("==処理後== tk.num_words: ", tk.num_words)
print("==処理後== tk.word_index: ", tk.word_index)
print("==処理後== tk.word_docs: ", tk.word_docs)
# 「辞書」と「テストデータ」を突合するメソッドです。
print("====== texts_to_sequences: ", tk.texts_to_sequences(sentences))
print("====== texts_to_matrix: ", tk.texts_to_matrix(sentences))
if __name__ == "__main__":
main()
(出力例)
==処理前== tk.document_count: 0
==処理前== tk.num_words: 7
==処理前== tk.word_index: {}
==処理前== tk.word_docs: defaultdict(<class 'int'>, {})
--------------------------------
==処理後== tk.document_count: 3
==処理後== tk.num_words: 7
==処理後== tk.word_index: {'love': 1, 'my': 2, 'i': 3, 'wife': 4, 'son': 5, 'you': 6, 'daughter': 7}
==処理後== tk.word_docs: defaultdict(<class 'int'>, {'wife': 1, 'i': 2, 'my': 3, 'love': 3, 'son': 1, 'you': 1, 'daughter': 1})
====== texts_to_sequences: [[3, 1, 2, 4], [3, 1, 2, 5], [6, 1, 2]]