<目次>
(1) PythonでのWebスクレイピングについて
やりたいこと
STEP0:概要
STEP1:必要なパッケージのインストール
STEP2:サンプルプログラムの作成(疎通編)
STEP3:サンプルプログラムの作成(robots.txtに従う)
(1) PythonでのWebスクレイピングについて
やりたいこと
・Pythonで試してみる(迷惑を掛けない範囲で)
→そもそもWebスクレイピングとは?を知りたい方は「コチラの記事」を参照
STEP0:概要
・PythonにはWebスクレイピングを非常に簡単に行うためのライブラリがあります。
・今回はその一つである「Beautiful Soup」を使った手順をご紹介します。
・また、モラルを守るため「robots.txt」に従ったプログラムを後半で紹介します。
STEP1:必要なパッケージのインストール
> pip install beautifulsoup4
(図111)
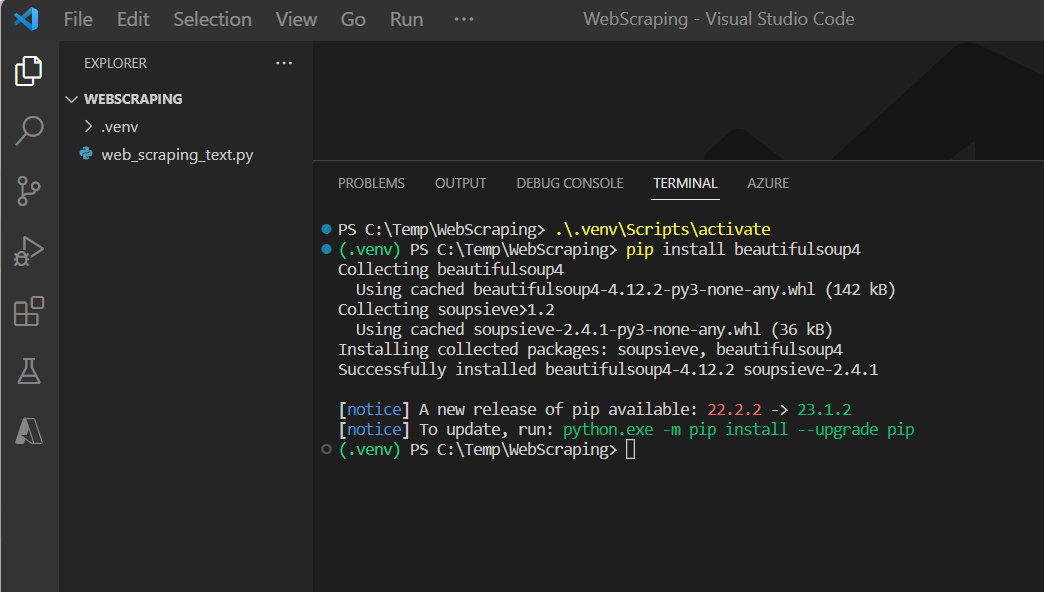
↓
(図112)
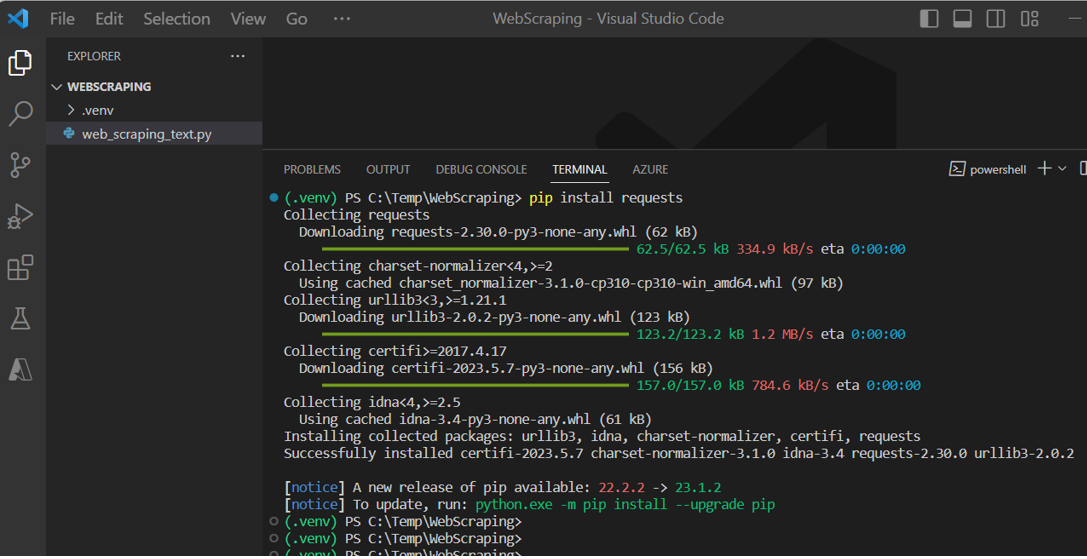
STEP2:サンプルプログラムの作成(疎通編)
まずは疎通です。ページのタイトルを取得します。
STEP2-1:サンプルプログラムの準備
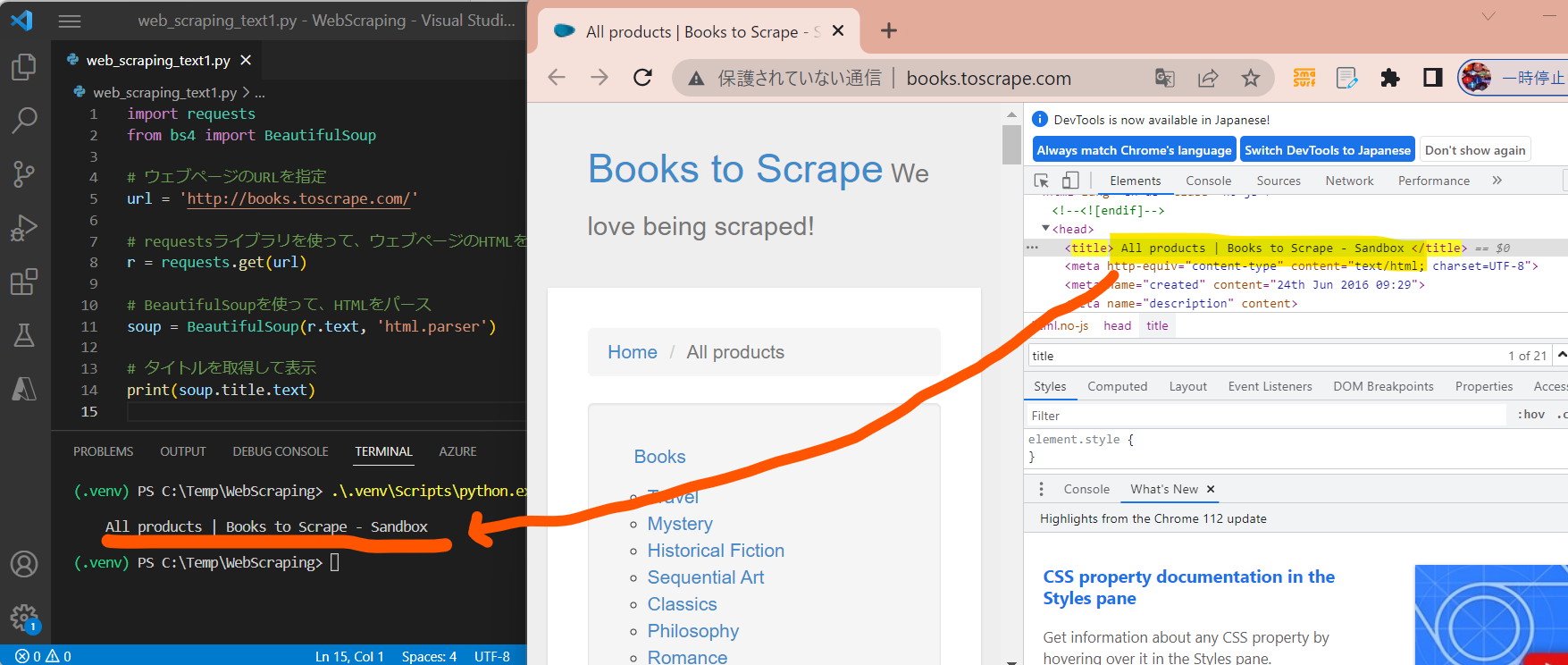
import requests from bs4 import BeautifulSoup # ウェブページのURLを指定 url = 'http://books.toscrape.com/' # requestsライブラリを使って、ウェブページのHTMLを取得 r = requests.get(url) # BeautifulSoupを使って、HTMLをパース soup = BeautifulSoup(r.text, 'html.parser') # タイトルを取得して表示 print(soup.title.text)
STEP2-2:実行
↓以下のスクレイピングのテスト用サイト(スクレイピングを歓迎している)を使ってテスト
①Quotes to Scrape – http://quotes.toscrape.com/
②Books to Scrape – http://books.toscrape.com/
(実行結果例)
All products | Books to Scrape – Sandbox
(図211)
STEP3:サンプルプログラムの作成(robots.txtに従う)
(サンプルプログラム)
import re
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse
# ウェブページのURLを指定
url = 'http://books.toscrape.com/'
# url = 'http://books.toscrape.com/'
# 規約に従ってウェブページにアクセス可能かチェックする関数
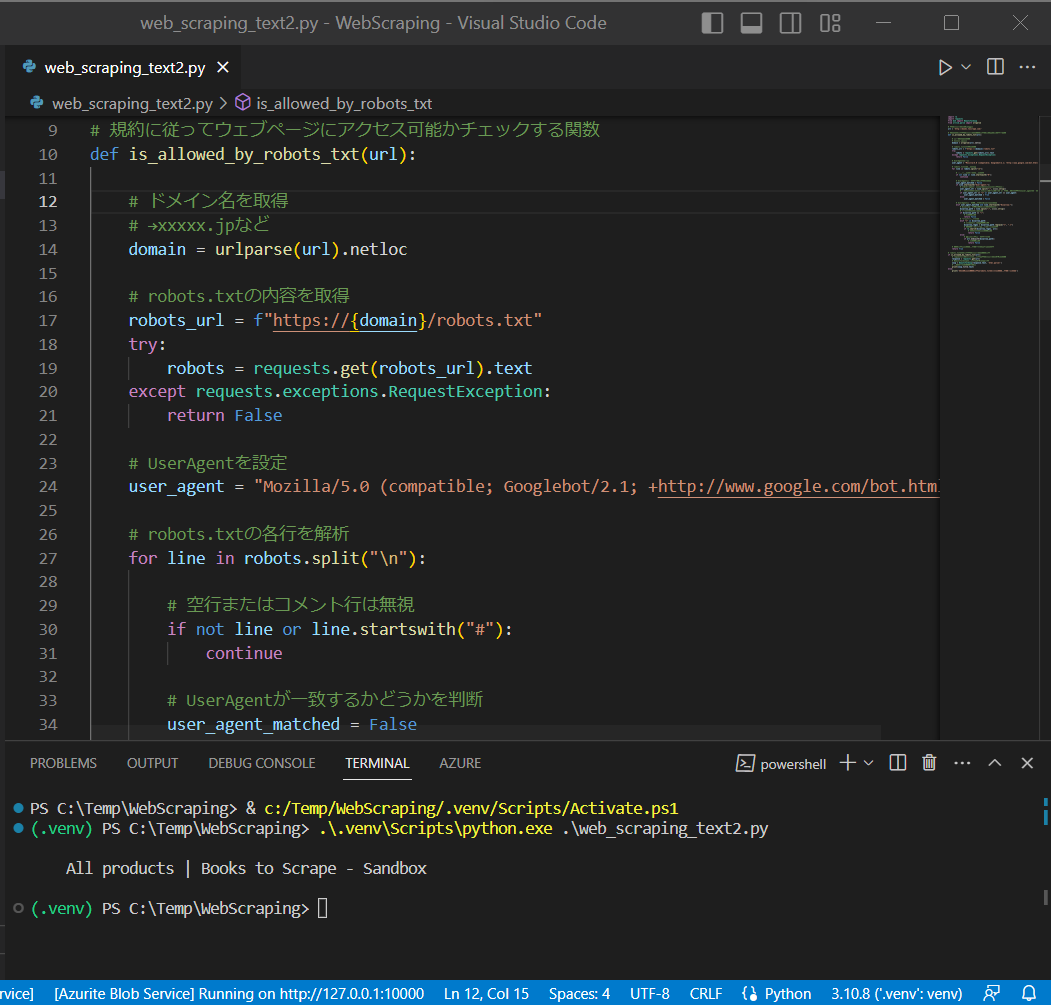
def is_allowed_by_robots_txt(url):
# ドメイン名を取得
# →xxxxx.jpなど
domain = urlparse(url).netloc
# robots.txtの内容を取得
robots_url = f"https://{domain}/robots.txt"
try:
robots = requests.get(robots_url).text
except requests.exceptions.RequestException:
return False
# UserAgentを設定
user_agent = "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
user_agent_matched = False
# robots.txtの各行を解析
for line in robots.split("\n"):
# 空行またはコメント行は無視
if not line or line.startswith("#"):
continue
# UserAgentが一致するかどうかを判断
if line.startswith("User-agent:"):
# 「User-agent: xxxxxx」のxxxxxxの部分を抽出
user_agent_str = line.split(":", 1)[1].strip()
# 一致の場合(robots.txtがワイルドカート or スクレイピング者のuser_agentと一致)
if user_agent_str == "*" or user_agent_str == user_agent:
user_agent_matched = True
else:
user_agent_matched = False
# UserAgentが一致した場合のDisallowの判断
elif user_agent_matched and line.startswith("Disallow:"):
# Disallow: 以降のエンドポイントを抽出
disallow_path = line.split(":", 1)[1].strip()
# "/"の場合、全部不許可
if disallow_path == "/":
# 許可しない
return False
# "*"が含まれる場合
elif "*" in disallow_path:
# 「*」を「.*」で置き換え
disallow_regex = disallow_path.replace("*", ".*")
# 正規表現によるパターンマッチング
if re.search(disallow_regex, url):
# 合致の場合:許可しない
return False
else:
# 最後の部分が一致する場合
if url.endswith(disallow_path):
# 許可しない
return False
# アクセスが許可されている場合はTrueを返す
return True
# robots.txtに従ってウェブページにアクセス
if is_allowed_by_robots_txt(url):
# requestsライブラリを使って、ウェブページのHTMLを取得
response = requests.get(url)
# BeautifulSoupを使って、HTMLをパース
soup = BeautifulSoup(response.text, 'html.parser')
# タイトルを取得して表示
print(soup.title.text)
else:
print('このURLへのスクレイピングはrobots.txtにより許可されていません。')
(結果例:正常系)
入力:url = 'http://books.toscrape.com/' 出力:All products | Books to Scrape - Sandbox
(図311)
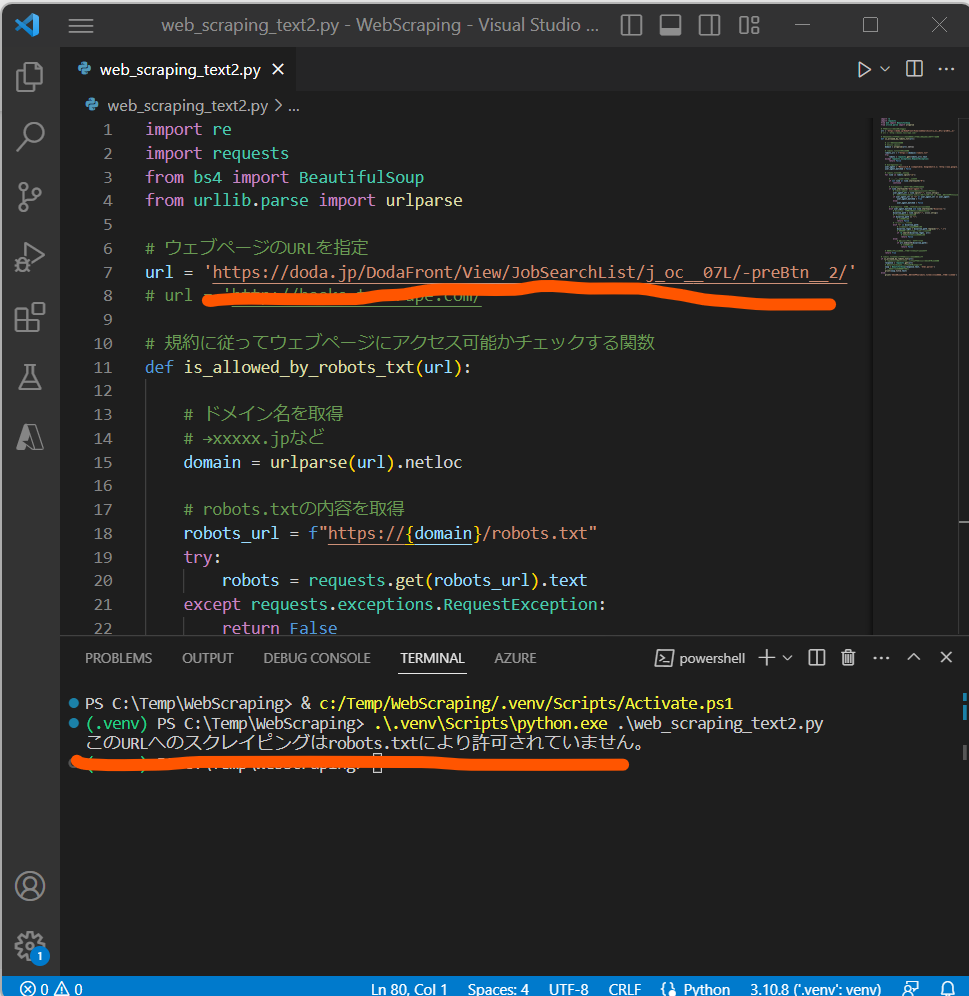
(結果例:異常系)→スクレイピングNGのURLを指定すると、ガードが掛かる(エラーになる)事の確認。
入力:url = ‘https://doda.jp/DodaFront/View/JobSearchList/j_oc__07L/-preBtn__2/’
出力:このURLへのスクレイピングはrobots.txtにより許可されていません。
(図312)