(0)目次&概説
(1) エラー対応1:UnicodeEncodeError
(1-1) 発生状況・エラーメッセージ
(1-1-1) エラーメッセージ
(1-1-2) エラーとなったソース
(1-2) 原因
(1-2-1) 全体のフロー
(1-2-2) 各エンコーディング箇所の考察
(1-3) 対処方法
(1-4) 補足事項
(1) エラー対応1:UnicodeEncodeError
(1-1) 発生状況・エラーメッセージ
Web上にあるcsvデータを”datapackage”パッケージを用いて変数にロードし、それをPandasの”read_csv”関数でDataframeに取り込み、最後にPandasの”to_sql”関数でDBにINSERTしようとした際に発生しました(EngineはSQLAlchemyの”create_engine”で作成)。
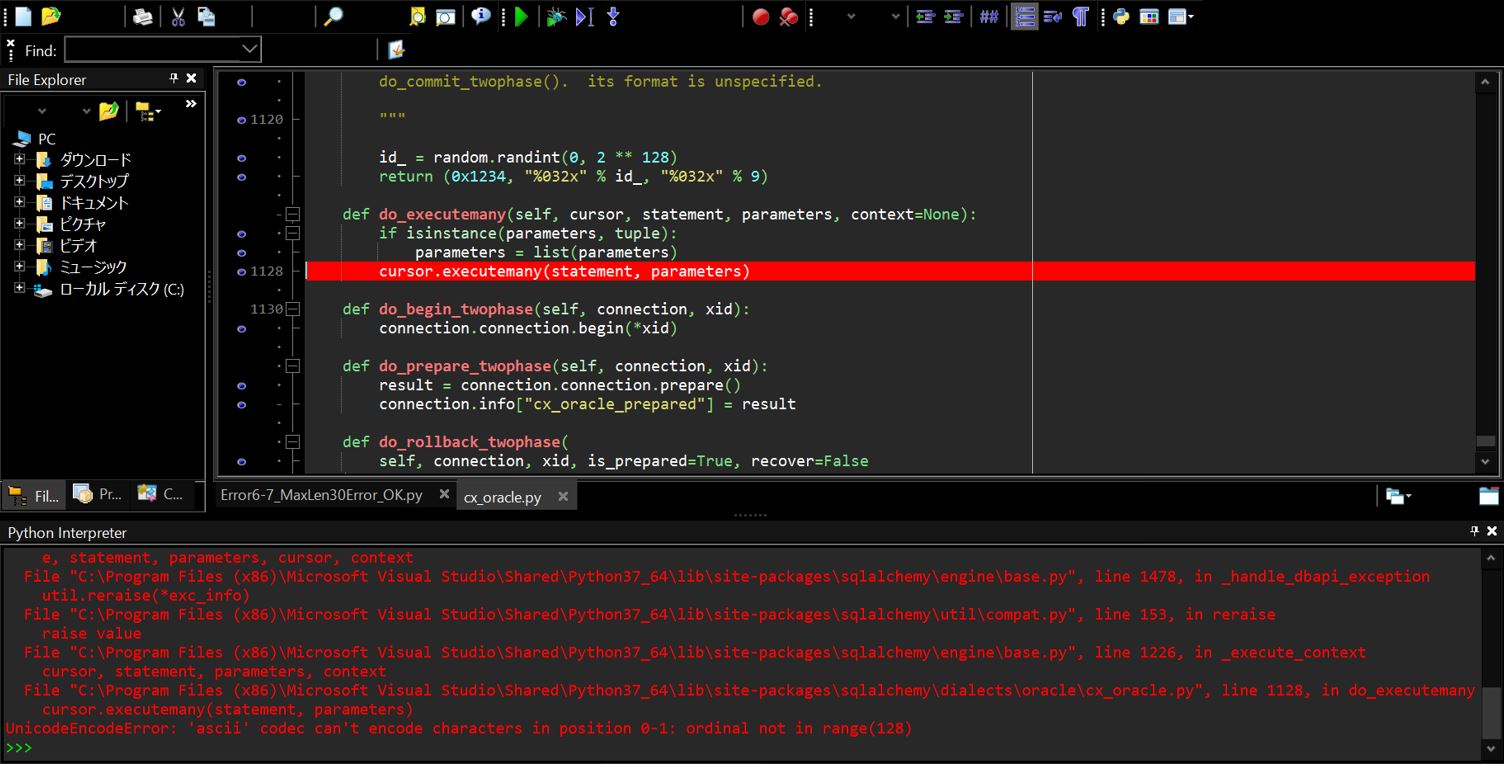
(1-1-1) エラーメッセージ
(例1)
UnicodeEncodeError: 'ascii' codec can't encode character '\xa3' in position 0: ordinal not in range(128)
(例2)
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
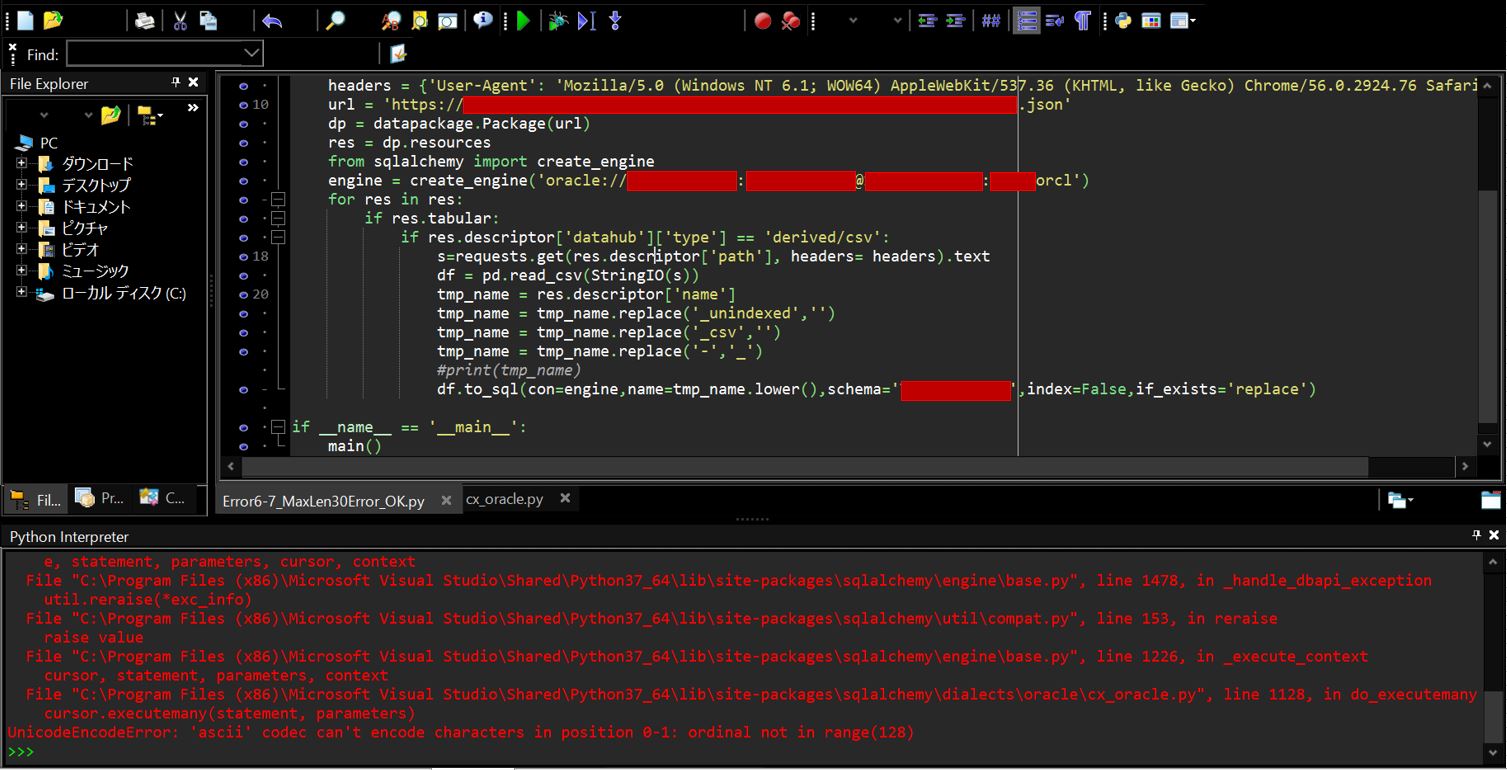
(1-1-2) エラーとなったソース
import datapackage
import sqlalchemy
import pandas as pd
import requests
from io import StringIO
def main():
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.76 Safari/537.36'}
url = 'https://[your URL].json'
dp = datapackage.Package(url)
res = dp.resources
from sqlalchemy import create_engine
engine = create_engine('oracle://[your schema]:[password]@[hostname]:[port]/[sid]')
for res in res:
if res.tabular:
if res.descriptor['datahub']['type'] == 'derived/csv':
s=requests.get(res.descriptor['path'], headers= headers).text
df = pd.read_csv(StringIO(s))
tmp_name = res.descriptor['name']
tmp_name = tmp_name.replace('_unindexed','')
tmp_name = tmp_name.replace('_csv','')
tmp_name = tmp_name.replace('-','_')
df.to_sql(con=engine, name=tmp_name.lower(), schema='TENNISDBUSR2', index=False, if_exists='replace')
if __name__ == '__main__':
main()
(図101)
(1-2) 原因
結論としては環境変数「NLS_LANG」のエンコーディング設定をしていなかったため、エラーが発生していました。
以降で上記の結論に至るまでの調査プロセスについても備忘として記載しておきます。
まず「UnicodeEncodeError: ‘ascii’ codec can’t encode characters~」のメッセージから「Unicode文字」をエンコード(文字列⇒バイト列への変換)時のエラーである事が読み取れます。ただし、エンコードといっても複数個所でエンコードがされており、どこの箇所のエンコードなのか?を特定していく必要があると考えます。
(1-2-1) 全体のフロー
まず、全体のフローとしてはおおよそ次の図のようになってきます。
(図201)
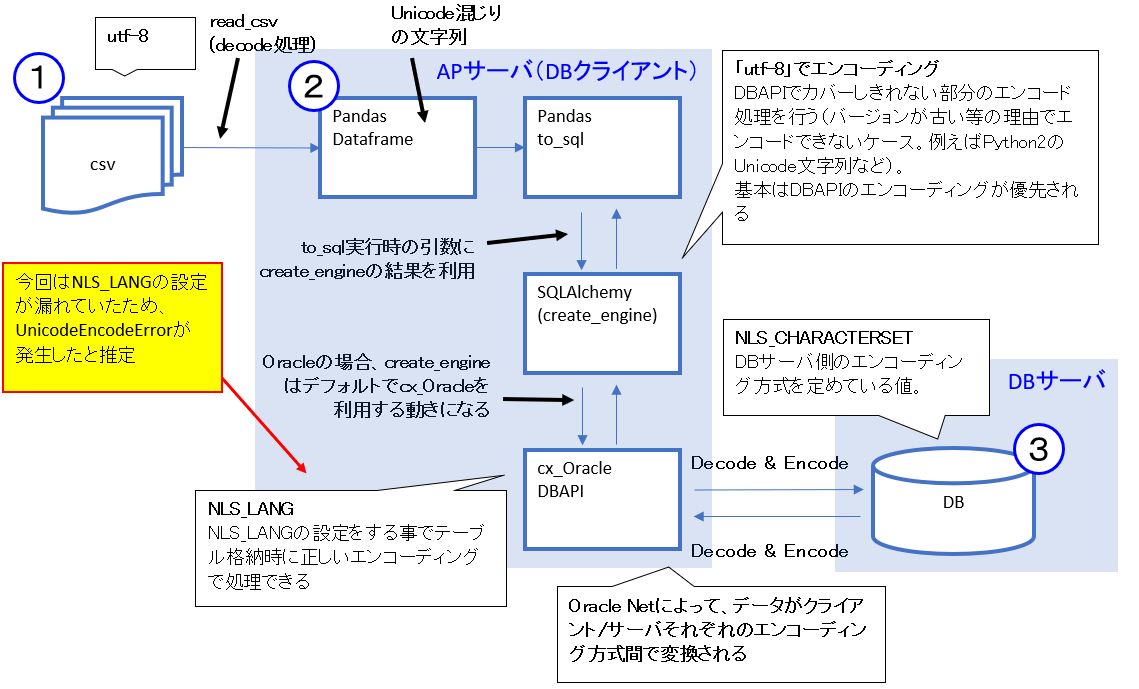
<全体のフロー>
(1-2-2) 各エンコーディング箇所の考察
そしてエンコーディング処理が入るのは、主に次の3か所になります。
1)csv→(read_csv)→DataframeのDecode処理
read_csvはエンコーディングの指定がない場合はデフォルトで”UTF-8″を使うそうですが、今回のcsvファイルも”UTF-8″なので、この箇所は問題ありません。
2)create_engineでのencoding指定
次にエンコーディングの指定が可能な部分が「create_engine」の箇所ですが、ドキュメントを読む限り、ここで指定したエンコーディングはDBAPIでカバーしきれない部分のエンコード処理を行っているようです(バージョンが古い等の理由でエンコードできないケース。例えばPython2のUnicode文字列など)。ですので、基本はDBAPIのエンコーディングが優先されます。
3)NLS_LANGのエンコーディング設定
最後がOracleDBに接続するクライアント側の環境変数「NLS_LANG」によるエンコーディング方式の指定です。そして今回の「’UnicodeEncodeError: ‘ascii’ codec can’t encode character~」のエラーの原因はここの指定が漏れていたため発生しています。メッセージからも”ascii”コーデックと書かれているので、UTF-8系のエンコーディング方式を指定してあげれば、Unicode文字のエンコードが出来てエラーが解消すると推測できます。
(1-3) 対処方法
クライアントからDBへのCRUD操作をする際のエンコーディング方式を指定する環境変数「NLS_LANG」の設定を次のコードで行います。Pythonの場合は「os」モジュールをインポートします。
・追加コード
import os os.environ['NLS_LANG'] = ".AL32UTF8"
・追加した後の全文
import os
import datapackage
import sqlalchemy
import pandas as pd
import requests
from io import StringIO
def main():
os.environ['NLS_LANG'] = ".AL32UTF8"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.76 Safari/537.36'}
url = 'https://[your URL].json'
dp = datapackage.Package(url)
res = dp.resources
from sqlalchemy import create_engine
engine = create_engine('oracle://[your schema]:[password]@[hostname]:[port]/[sid]')
for res in res:
if res.tabular:
if res.descriptor['datahub']['type'] == 'derived/csv':
s=requests.get(res.descriptor['path'], headers= headers).text
df = pd.read_csv(StringIO(s))
tmp_name = res.descriptor['name']
tmp_name = tmp_name.replace('_unindexed','')
tmp_name = tmp_name.replace('_csv','')
tmp_name = tmp_name.replace('-','_')
df.to_sql(con=engine,name=tmp_name.lower(),schema='TENNISDBUSR2',index=False,if_exists='replace')
if __name__ == '__main__':
main()
(1-4) 補足事項
1)DBAPIとは?
PythonでリレーショナルDBを操作するためのAPI仕様のことで、PEP249にて記載されています。PEPというのは”Python Enhancement Proposal”の略で、Pythonの機能拡張に関する詳細設計書のようなドキュメントでPythonのコミュニティに提出されたりしています。
このDBAPIの仕様は異なるリレーショナルDB間で統一する事で、例えDBを操作するモジュール(Oracleなら”cx_Oracle”、SQLServerなら”pyodbc”、MySQLなら”PyMySQL”等)が異なっても、同じインターフェイスを利用できます。
例えば”Module Interface”に書かれたconnect()コンストラクタなど、DBの種類が異なっても似た要領で記述できます。
(例1) SQLServer
pyodbc.connect()で接続
driver='{SQL Server}'
server='[hostname]'
database='[database name]'
uid='[username]'
pwd='[password]'
cnxn=pyodbc.connect('DRIVER='+driver+';SERVER='+server+';DATABASE='+database+';UID='+uid+';PWD='+pwd+';')
(例2) Oracle
cx_Orale.connect()で接続
server='[hostname]' port='[port]' srvname='[sid]' uid='[your shcema]' pwd='[your password]' dsn_tns = cx_Oracle.makedsn(server, port, service_name=srvname) cnxn = cx_Oracle.connect(user=uid, password=pwd, dsn=dsn_tns)
2)Unicodeオブジェクトとは?
Unicodeとは世界各国の文字を扱える「文字集合」(正確には「符号化文字集合」)です。
Python2においては「u’….’」リテラルで囲まれたオブジェクトなどはUnicodeオブジェクトと呼ばれており、str型とUnicode型はencode/decodeメソッドを用いて下記のように相互変換を行っていました。
①Unicode ⇒ encode() ⇒ str
②str ⇒ decode() ⇒ Unicode
しかしPython3においてはUnicode文字は通常の「str型」の中で使えるようになりました。Python2との対比で見ると次のような形になります。
(表)
| Python3 | Python3型 | Python3リテラル | Python2で対応するもの(≒なもの) | Python2型 | Python2リテラル |
| 文字列 | str | ‘xxxx’ | Unicode文字列 | unicode | u’xxxx’ |
| バイト列 | bytes | b’xxxx’ | バイト文字列 | str | ‘xxxx’ |
<備考>
・Python2,3いずれも、文字列/Unicode文字列⇒バイト文字列/バイト列への変換はencode()を使う
・Python3ではstr型の中でUnicode文字を扱える
・Python2,3いずれも、バイト文字列/バイト列⇒文字列/Unicode文字列への変換はdecode()を使う
・Python3のバイト列は文字列としての連結操作等が不可(あくまで「バイト」の列であるため)
3)ロケールとは?
(構文)
[ベース言語]_[使用地域].[コードセット]
(例)ドイツ語の「de」+スイス使用の「CH」+コードセット「UTF-8」の例
de_CH.UTF-8