(0)目次&概説
(1) エラー:HTTP Error 403: Forbidden
(1-1) 発生状況・エラーメッセージ
(1-2) 原因
(1-3) 対処方法
(1-3-1) 修正前のプログラム
(1-3-2) 修正後のプログラム
(1-4) 用語説明
(1-4-1) User-Agentとは
(1-4-2) User-Agentの一般的な記述内容(構文)
(1-4-3) Firefoxの場合の記述内容(構文)
(1) エラー:HTTP Error 403: Forbidden
(1-1) 発生状況・エラーメッセージ
Web上で公開されているcsvデータのURLに対して、Pandasの「read_csv」を使ってアクセスしようとした際にエラーが出ました。エラーメッセージの最後の一行は次のように表示されています。
urllib.error.HTTPError: HTTP Error 403: Forbidden
(図001)
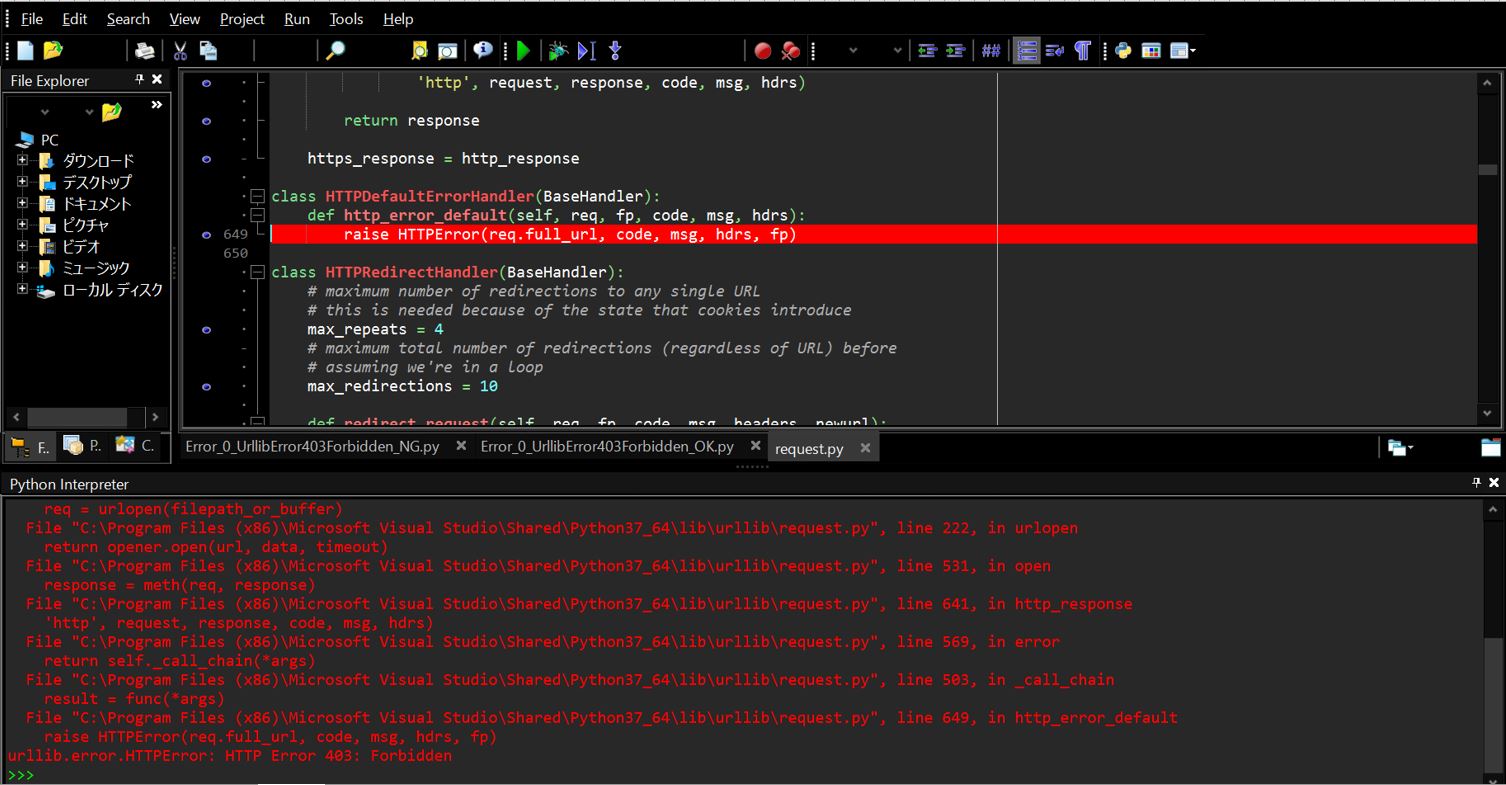
(図002)

(1-2) 原因
原因と考えられるのは、アクセスしようとしているURLが「非ブラウザ」のリクエストを許可しない設定になっている点です。HTTPヘッダーの基本の構文は次のような形式です。
'User-Agent': '[product] / [product-version] [comment]'
実際PythonからリクエストのデフォルトのHTTPヘッダーは次のようになっており、非ブラウザのリクエストになっています。
'User-Agent': 'python-requests/2.13.0'
この「’python-requests/2.13.0’」の部分などをブラウザからのリクエストと認識されるように書き換えていく事になります。
(1-3) 対処方法
「非ブラウザ」のリクエストが許可されていないので、HTTPリクエストヘッダーの内容を「ブラウザ」リクエストとして明示的に書き換えてリクエストを送ります。
(1-3-1) 修正前のプログラム
import datapackage
import pandas as pd
import requests
def main():
url = 'https://datahub.io/core/s-and-p-500-companies-financials/datapackage.json'
dp = datapackage.Package(url)
res = dp.resources
for res in res:
if res.tabular:
r = requests.get(res.descriptor['path'], stream=True)
print(r.headers)
df = pd.read_csv(res.descriptor['path'])
print(res.descriptor['path'])
if __name__ == '__main__':
main()
■修正ポイント
①最初に「headers = {‘XXXX’}」を書いてHTTPヘッダーを指定する事でブラウザリクエストとして送信しています。
②requestsパッケージのgetメソッドで先程のヘッダーを指定した状態でHTTPレスポンスを受け取り、その内容(テキスト)を変数(s)に格納しています。
③read_csvの引数はパスではなくStringIOオブジェクトに格納したcsvのデータを渡しています
| requestsパッケージ | PythonのHTTPライブラリ |
| ∟api.pyモジュール | GETリクエストを送ってレスポンスを返却するgetメソッドや同様にPOSTメソッドを送るメソッドなどが実装されているモジュール |
| ∟getファンクション | 指定したURLに対してHTTPのGETリクエストを送り、HTTPのレスポンスを返却します(models.pyモジュール⇒Responsetクラスのインスタンス)。例えば正常終了の場合は<Response [200]>を返します。 |
| ∟text属性 | HTTPレスポンスの内容を返却(実際の中身のテキスト値=str型) |
(1-3-2) 修正後のプログラム
import datapackage
import pandas as pd
import requests
from io import StringIO
def main():
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.76 Safari/537.36'}
url = 'https://datahub.io/core/s-and-p-500-companies-financials/datapackage.json'
dp = datapackage.Package(url)
res = dp.resources
for res in res:
if res.tabular:
s=requests.get(res.descriptor['path'], headers= headers).text
df = pd.read_csv(StringIO(s))
print(res.descriptor['path'])
if __name__ == '__main__':
main()
| 行数 | プログラム | 解説 |
| 8 | headers = {‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.76 Safari/537.36’} | ブラウザリクエストとして認識させるため、HTTPリクエストヘッダーを定義しています。 |
| 9 | dp = datapackage.Package(url) | datapackageパッケージのPackageクラスをインポートして、Packageのインスタンスを作成しています。
型:<class ‘datapackage.package.Package’> |
| 10 | res = dp.resources | Packageインスタンスのresourcesメソッドを用いて”Resouce”オブジェクトのlistを返却します。
入力: print(type(res)) 入力: print(res) |
| 12 | if res.tabular: | 表形式かどうかを判断するために”Resouce”オブジェクトのtabular属性をチェックしています。この値がTrueの場合は”Resouce”オブジェクトが表形式であると言えます。 |
| 13 | s=requests.get(res.descriptor[‘path’], headers= headers).text | 「res.descriptor[‘path’]」で指定したURLの資源に対して、上で定義したヘッダを付与したHTTPのGETリクエストを送り、getメソッドの戻り値のレスポンスの内容を「text」属性で取得。 |
| 14 | df = pd.read_csv(StringIO(s)) | 上記のcsvデータの内容を「read_csv」メソッドでPandasのDataframeに取り込みます。 |
(図003)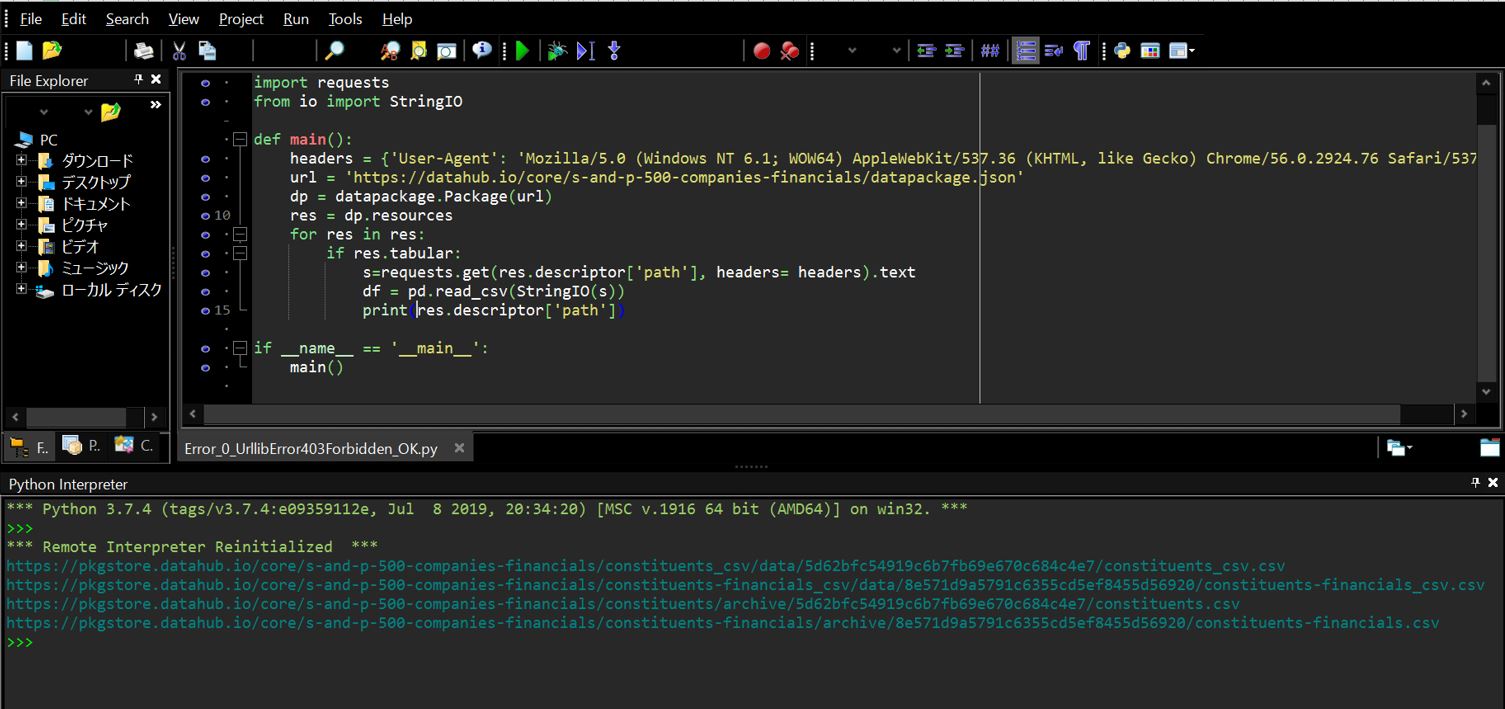
(1-4) 用語説明
(1-4-1) User-Agentとは
User-AgentはブラウザからWebサイトにアクセスする際に使うソフトウェアです。Webサイトにアクセスする際にはHTTPのリクエストヘッダーに’User-Agent’のラベル名でエージェントの名前を送っています。サーバーはこの’User-Agent’の情報から、どのようなデバイス(PCやスマホ)からのアクセスかを判断し、そのデバイスにあった情報を返します。ただし、ブラウザやOSの種類の情報を持っているのでアクセス解析にも利用されるものの、上記の通りユーザー側で値を操作できるため正確な統計とはならないリスクもあります。
(1-4-2) User-Agentの一般的な記述内容(構文)
Mozilla/5.0 (<system-information>) <platform> (<platform-details>) <extensions>
①<system-information>
ブラウザが動作している「デバイス」(Macintoshなど)やシステム情報(OSなど)を記述しています。
(例1)Windows NT X.X (“X.X”はバージョン)
1993~1996年頃のWindows製の32bitOSです。実際はサーバーとして動作する”Windows NT Server”とワークステーション(PCやネットワーク機器の集合)として動作する”Windows NT Workstation”とがあります。
(例2)WoW64
Windows OSのサブシステムで、64bitOS上で32bitのアプリケーションを動作させる事ができます。
(例3)Trident
Void LinuxをベースにしたGUIベースのOSです。
②<platform>
ブラウザのレンダリングエンジンの情報が記載されています。例えば「AppleWebKit/537.36」などはAppleが中心となって作成しているレンダリングエンジンです。
③<platform-details>
上記<platform>の詳細情報が記載されています。例えばKHTML(オープンソースのレイアウトエンジン)などレンダリングエンジンの名前が入るケースがあります。
KHTMLは”Konquerer”と呼ばれるLinuxのKDEデスクトップのために開発されたもので、AppleWebKitもこのKHTMLから派生しています。「like Gecko」の文言を付与する事でGeckoが受け取るような最新のページを受け取る事が出来ます。
④<extensions>
リクエストしているクライアント端末のブラウザ情報(Chrome/51.0.2704.103)や、ブラウザにて利用可能なサードパーティ製の改修などを検知するための情報です。
(1-4-3) Firefoxの場合の記述内容(構文)
Firefoxの場合の記述内容は次の通りです。
Mozilla/5.0 (platform; rv:geckoversion) Gecko/geckotrail Firefox/firefoxversion
①Mozilla/5.0
Mozillaに適合したブラウザである事を示す一般的なトークンで、IEやChromeなどでも冒頭にこの文言を記述するケースが多く、「ブラウザ戦争」などの歴史的な経緯もあり多くのブラウザ種類で「おまじない」的に記述されています。
②[platform]
ブラウザが起動しているOSの種類を記述しています(Windows、Linux、Mac、Android他)。
③rv:[geckoversion]
Geckoのバージョンを記述します。最近のブラウザではFirefoxのバージョンと同じケースが多いです。
④Gecko/geckotrail
ブラウザがGeckoに基づいて動作している事を記述しています。スラッシュ(/)の後にある”geckotrail”はデスクトップPCの場合は常に固定で「20100101」にします。
⑤Firefox/firefoxversion
ブラウザがFireFoxである事を記述しています。「/」の後にバージョンを記述しています。