(0)目次&概説
(1) 検証概要
(2) 検証環境
(3) 検証準備
(3-1) サンプルデータ作成(インデックス無)
(3-2) サンプルデータ作成(インデックス有)
(3-3) 実行計画の参照方法
(3-4) バッファキャッシュのクリア方法
(3-5) 時間の測定方法
(3-6) 測定の手順
(4) 検証
(4-1) 測定&実行計画チェック(1回目)
(4-2) サンプルデータの追加(準備)
(4-3) 測定&実行計画チェック(2回目)
(4-4) インデックス断片化させる(準備)
(4-5) 測定&実行計画チェック(3回目)
(5) 考察と今後の取り組み
(5-1) 考察
(5-2) 反省点や次回への課題
(1) 検証概要
インデックスの効果を測定するために、照会や更新の速度をインデックスがある場合と、ない場合とで比較します。
>目次にもどる
(2) 検証環境
今回の検証では以下の環境を利用します。
| OS | CentOS release 6.8 (Final) |
| ビット数 | 64ビット |
| CPU | Intel(R) Xeon(R) CPU E5-2640 0 @ 2.50GHz |
| メモリ | 1.8GB |
| データベース | Oracle Database 11g Release 2 Standard Edition |
| ツール | Oracle SQL Developer 1.5.5 |
(3) 検証準備
(3-1) サンプルデータ作成(インデックス無)
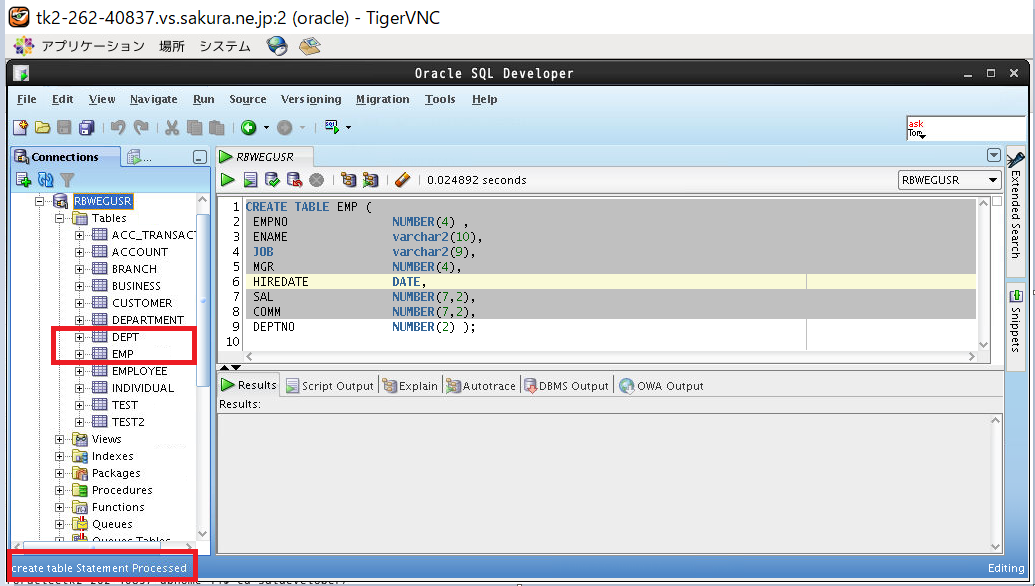
まずはCREATE TABLE文で「DEPTテーブル」と「EMPテーブル」を作成します。
--DEPTテーブルの作成 CREATE TABLE DEPT ( DEPTNO NUMBER(7), DNAME varchar2(500), LOC varchar2(500) ); --EMPテーブルの作成 CREATE TABLE EMP ( EMPNO NUMBER(8) , ENAME varchar2(500), JOB varchar2(150), MGR NUMBER(8), HIREDATE DATE, SAL NUMBER(9,2), COMM NUMBER(9,2), DEPTNO NUMBER(7) );
(例)CREATE TABLEの実行例
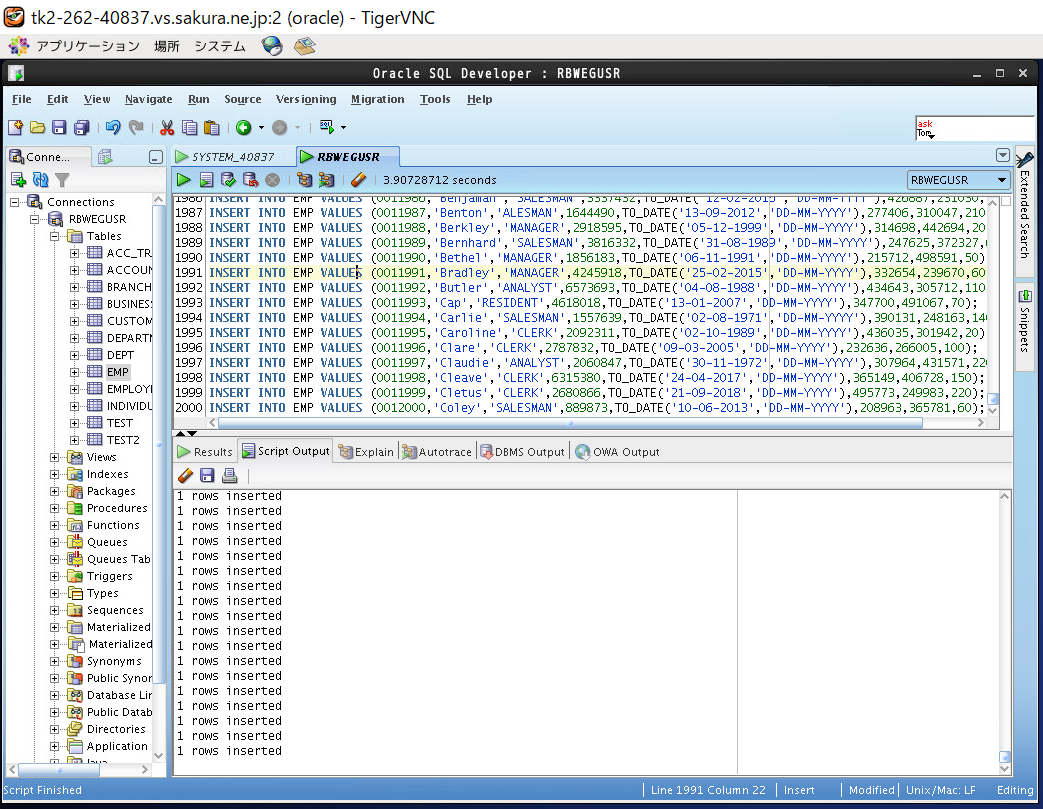
次にテストデータのレコード約20万件を挿入します。
INSERT INTO EMP VALUES (0000001,'John','CLERK',7232722,TO_DATE('08-10-1979','DD-MM-YYYY'),483838,234616,150);
INSERT INTO EMP VALUES (0000002,'William','SALESMAN',1562604,TO_DATE('19-04-1979','DD-MM-YYYY'),199778,298362,260);
INSERT INTO EMP VALUES (0000003,'James','ALESMAN',4162312,TO_DATE('20-07-2009','DD-MM-YYYY'),490481,376206,230);
・・・(中略)・・・
INSERT INTO EMP VALUES (0199998,'Cecil','ANALYST',1785036,TO_DATE('19-02-1995','DD-MM-YYYY'),213688,290646,230);
INSERT INTO EMP VALUES (0199999,'Eddie','RESIDENT',1996673,TO_DATE('20-04-2019','DD-MM-YYYY'),440955,223425,50);
INSERT INTO EMP VALUES (0200000,'Lloyd','SALESMAN',7794050,TO_DATE('03-09-1972','DD-MM-YYYY'),431105,455920,170);
(3-2) サンプルデータ作成(インデックス有)
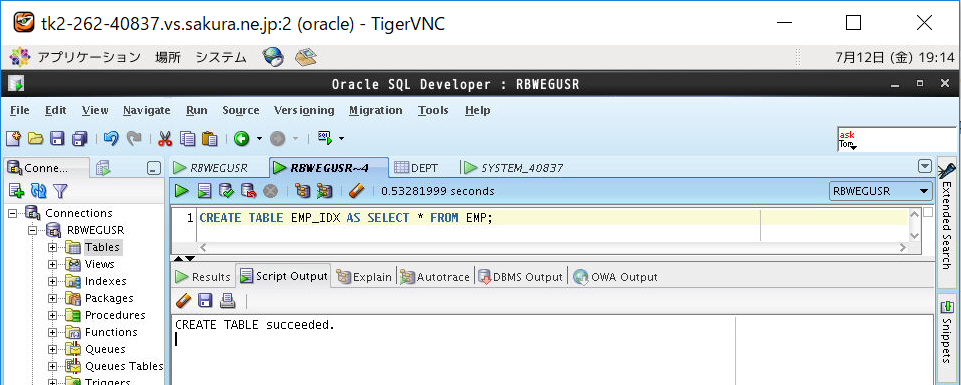
上記で作成したEMP表(インデックスなし)のテーブルをコピーする形で作成します。
--テーブル作成 --既存のテーブルをコピーしてテーブルを作成する CREATE TABLE EMP_IDX AS SELECT * FROM EMP;
テーブルの作成後に主キーを追加します。Oracleの場合は主キーを設定する事でインデックスが追加されるため、インデックス単体での追加は不要となります。
ALTER TABLE EMP_IDX ADD PRIMARY KEY(EMPNO);
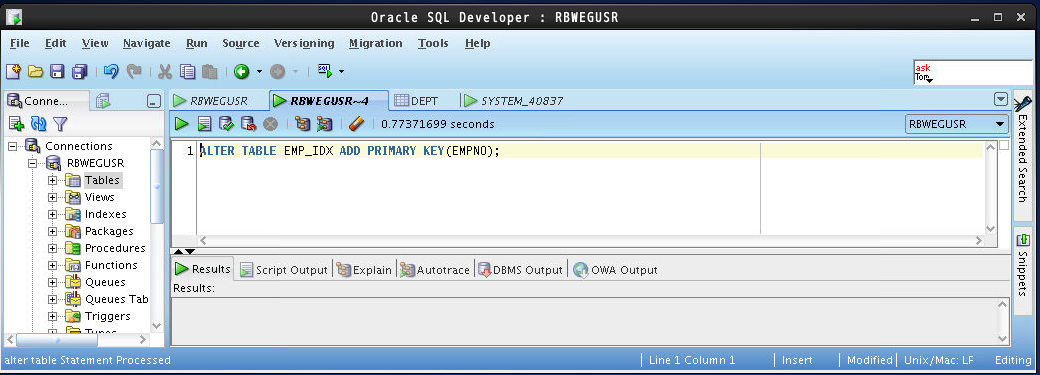
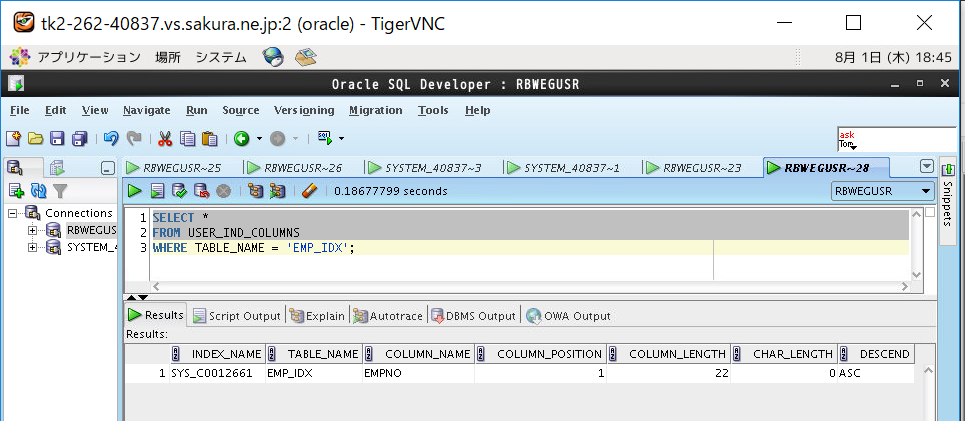
インデックスが足されたかどうか?は以下のコマンドで確認します。
SELECT * FROM USER_IND_COLUMNS WHERE TABLE_NAME = 'EMP_IDX';
今回は主キーを足したら自動的にインデックスが追加されましたが、本来インデックスのみを追加するコマンドとしては以下の通りです。
CREATE INDEX [インデックス名] ON [テーブル名](EMPNO);
(3-3) 実行計画の参照方法
実行計画とはSQLの処理の順序に関する計画です。Oracleの場合は「コストベース・オプティマイザ」と呼ばれる機能を用いて、最も効率的なアクセスルートを決定します。「最も効率的」をどのように判断しているか?については「コスト」を計算して判断しています。「コスト」は「テーブルやインデックス情報」や「ディスクI/O」や「CPU利用率」や「メモリー使用量」などの「統計情報」をベースに算出されます。実行計画はSQL Developerから以下の手順で参照します。
(1)「Open SQL Worksheet」を押下して新しいワークシートを開きます
(2)ワークシートに実行計画を取得するSQLを貼り付けます
(3)「Execute Explain Plan」(F6)を押下して実行計画を作成します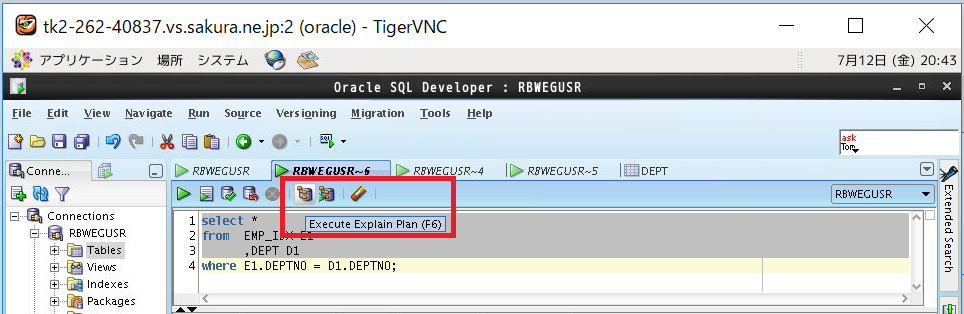
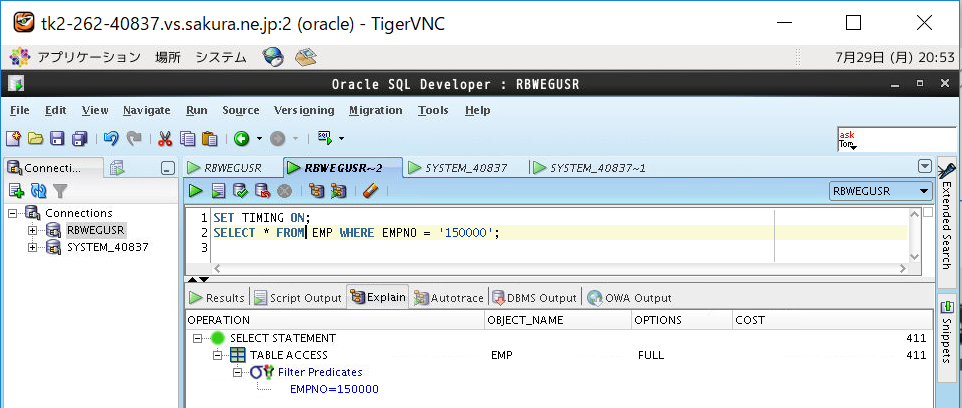
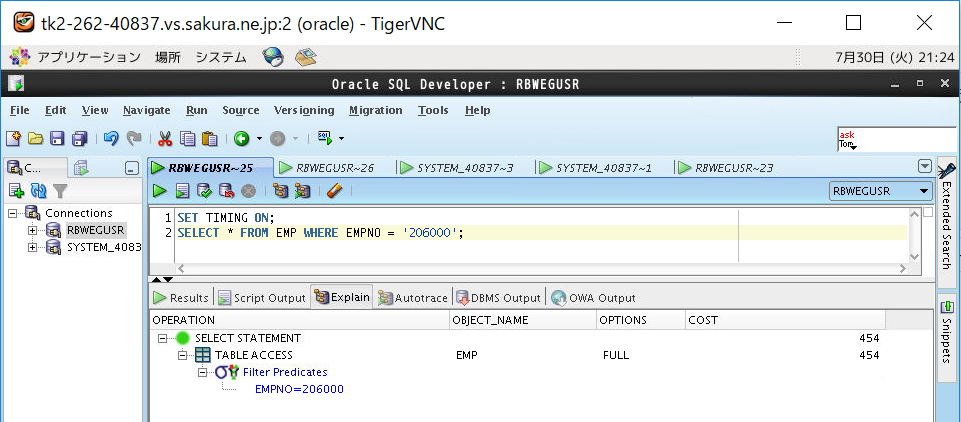
実際に実行計画を見てみると、インデックスなしのテーブル「EMP」のコストが「410」(FULL SCAN)に対して、インデックスありのテーブル「EMP_IDX」のコストは1/4の「120」(FAST FULL SCAN)となっています。
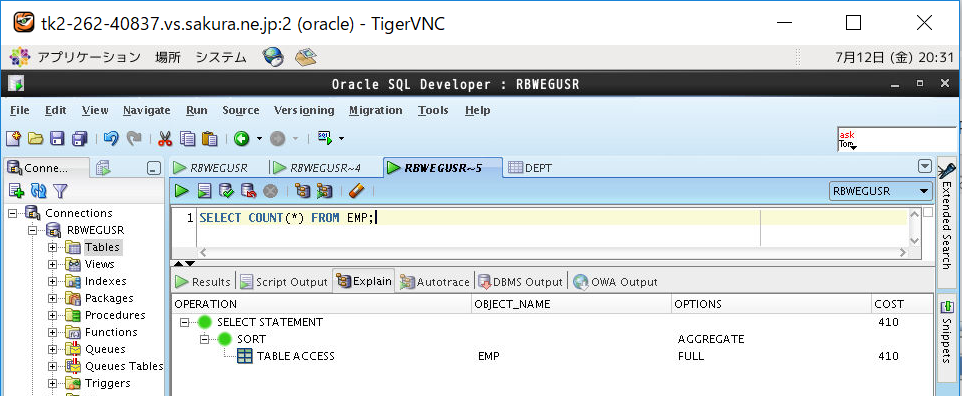
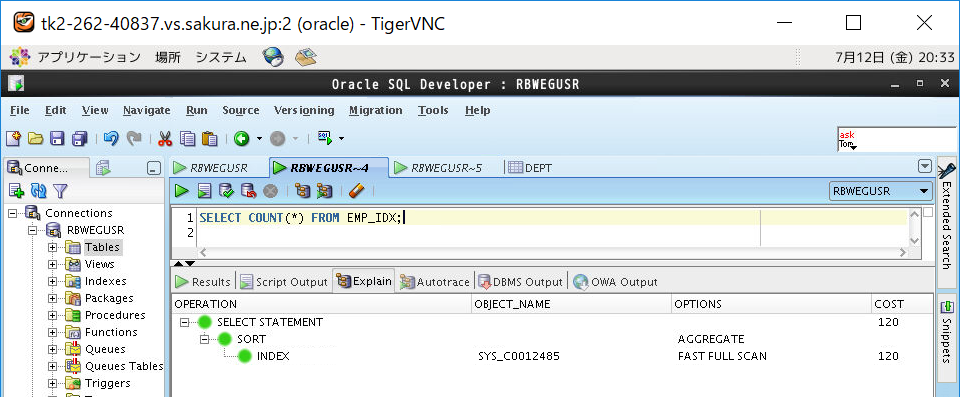
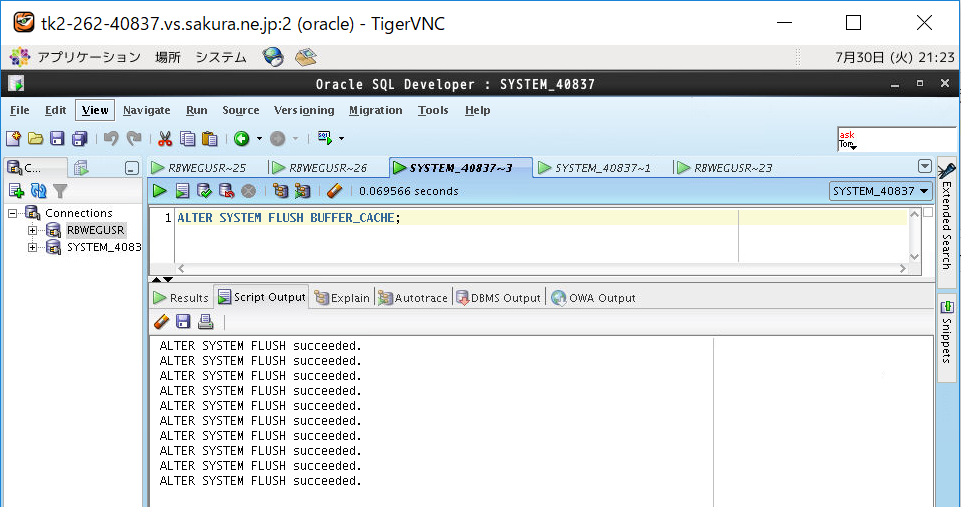
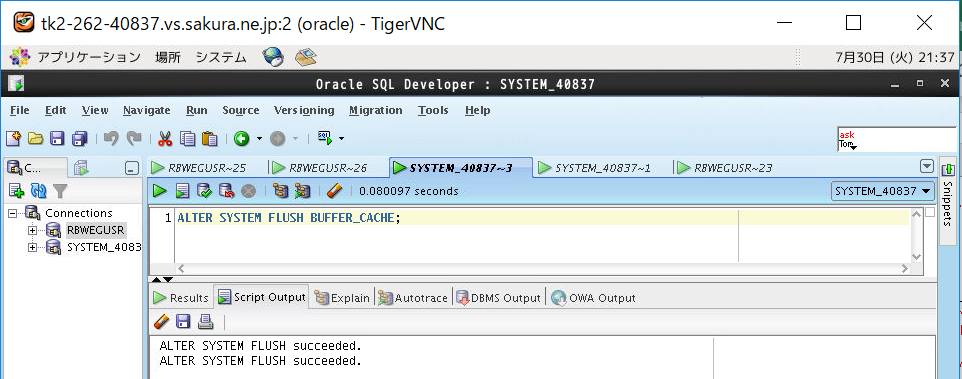
(3-4) バッファキャッシュのクリア方法
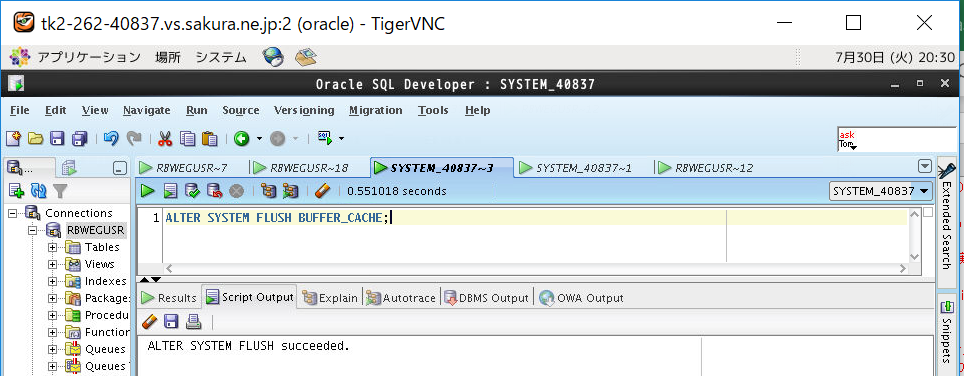
SQLの性能試験をする際はバッファキャッシュ上のデータをクリアする必要があります。理由はメモリ内のバッファキャッシュ上にキャッシュデータが残存していると、クエリの処理時にディスク(データファイル)を参照しに行く必要がなくなるため、レスポンスが早くなり正当な評価とならない可能性があるためです。キャッシュクリアは以下のコマンドで実行します。
ALTER SYSTEM FLUSH BUFFER_CACHE;
(3-5) 時間の測定方法
SQLの実行時間の測定は「SET TIMING ON;」句で実施できます。
SET TIMING ON; SELECT * FROM EMP_IDX WHERE EMPNO = '150001';
(3-6) 測定の手順
測定は以下のような手順で実施します。
①インデックスあり表(B木)の実行計画を取得
②インデックスあり表(B木)をSELECTして時間計測
③バッファキャッシュクリア
④インデックスなし表の実行計画を取得
⑤インデックスなし表をSELECTして時間計測
⑥バッファキャッシュクリア
(4) 検証
(4-1) 測定&実行計画チェック(1回目)
<想定結果>
INDEXを設定した直後の状態のため(断片等が発生していないため)、「インデックスなし」よりも「インデックスあり」の方が速度が速くなる。
<試験結果>
| インデックス有無 | 処理時間 (単位:ms) |
1回目との差分 |
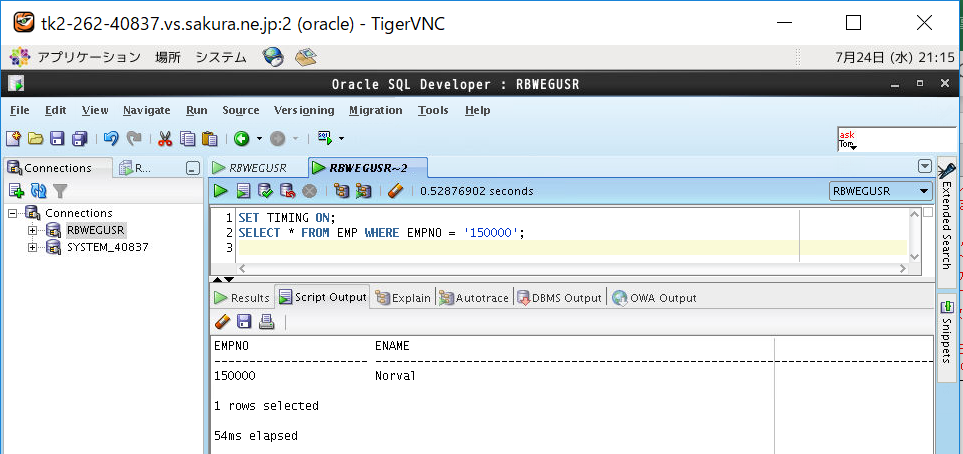
| あり | 10 | 0 |
| なし | 54 | 0 |
<画面キャプチャ>
①インデックスあり表(B木)の実行計画を取得
②インデックスあり表(B木)をSELECTして時間計測
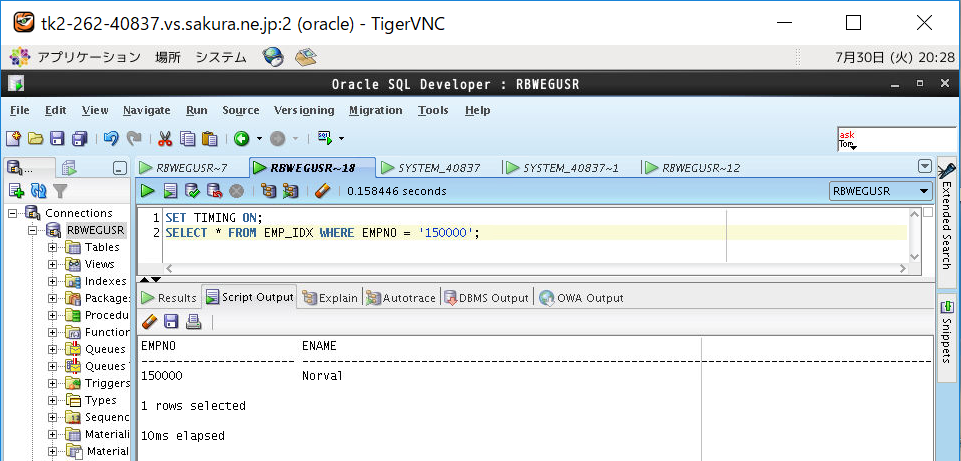
③バッファキャッシュクリア
④インデックスなし表の実行計画を取得
⑤インデックスなし表をSELECTして時間計測
⑥バッファキャッシュクリア
(4-2) サンプルデータの追加(準備)
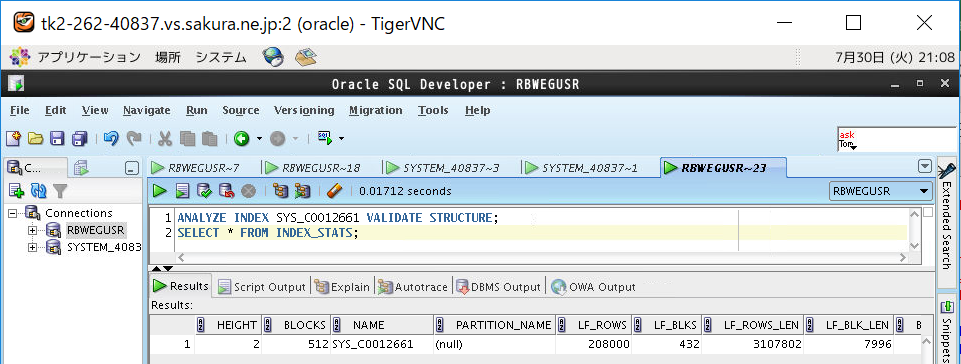
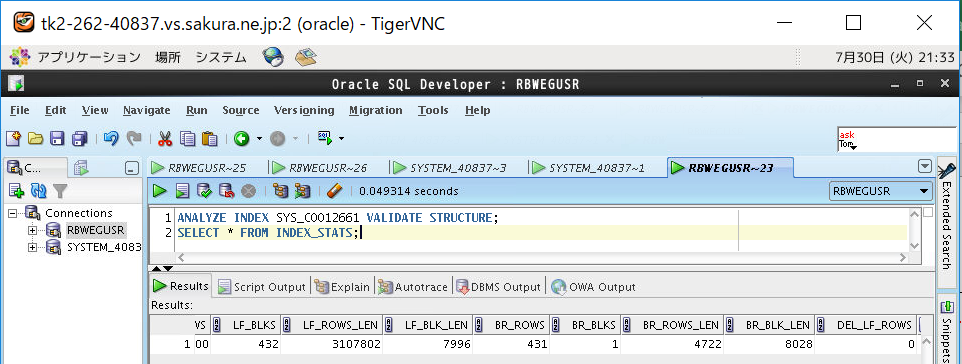
約8000行を追加でINSERTします。インデックスありの方(EMP_IDX)はINSERT後にインデックスのステータスや統計情報を以下のコマンドでチェックします。
ANALYZE INDEX SYS_C0012661 VALIDATE STRUCTURE; SELECT * FROM INDEX_STATS;
EMP表
EMP_IDX表
インデックスのステータスをチェック
(4-3) 測定&実行計画チェック(2回目)
<想定結果>
・「インデックスなし」は前回とほぼ変わらない
(レコード件数が増えただけのため)
・「インデックスあり」は前回よりも照会時間が遅くなる
(INSERTしてINDEXが最適化されていない状態のため)
<試験結果>
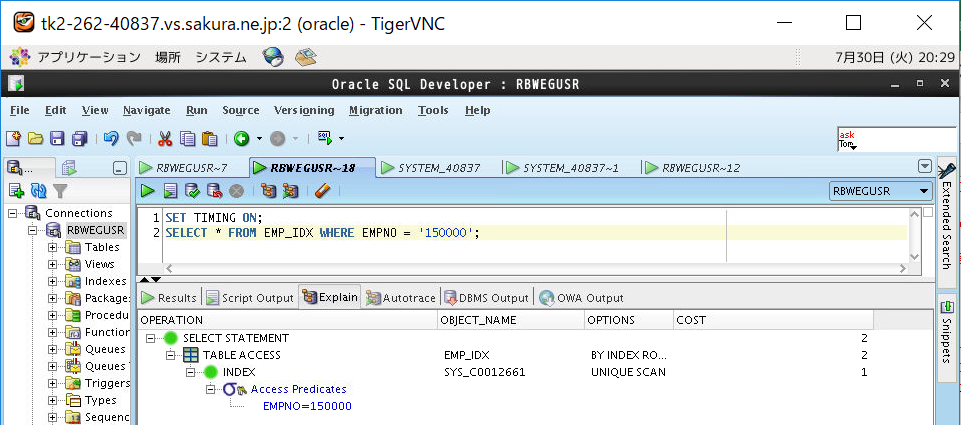
(a)インデックス範囲内の検索(EMPNO=’150000′)
| インデックス有無 | 処理時間 (単位:ms) |
1回目との差分 |
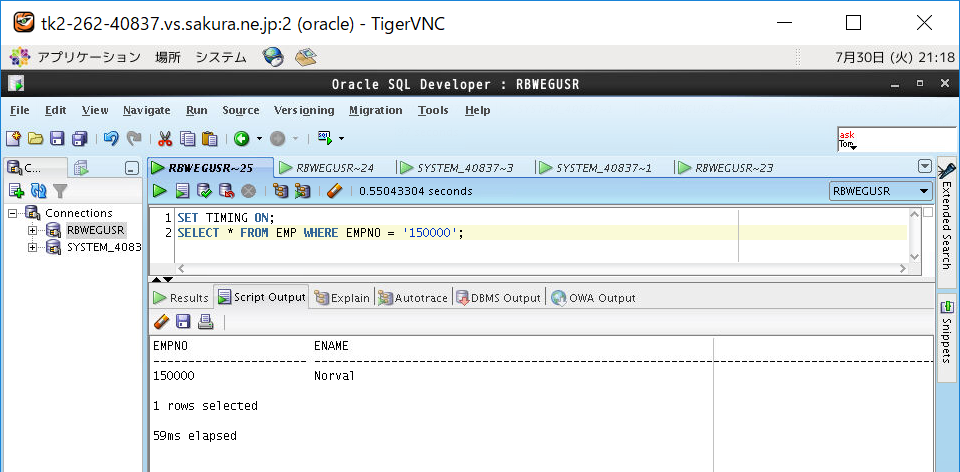
| あり | 13 | +3 |
| なし | 59 | +5 |
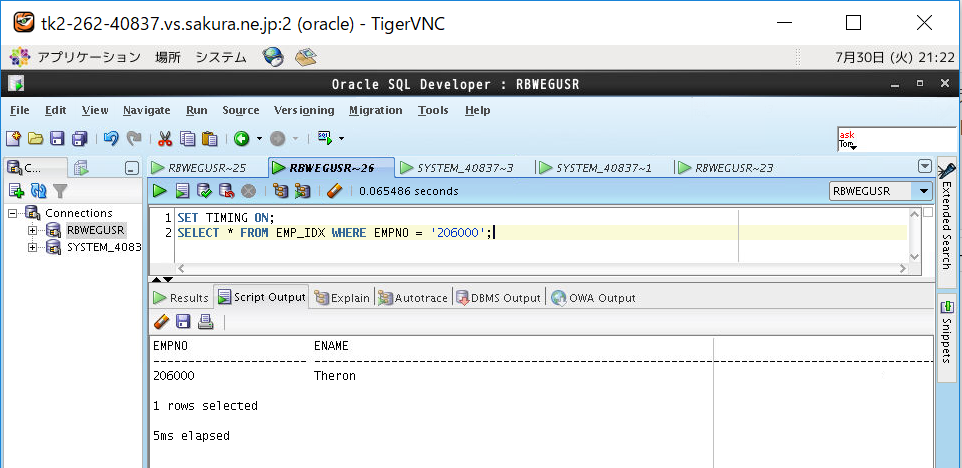
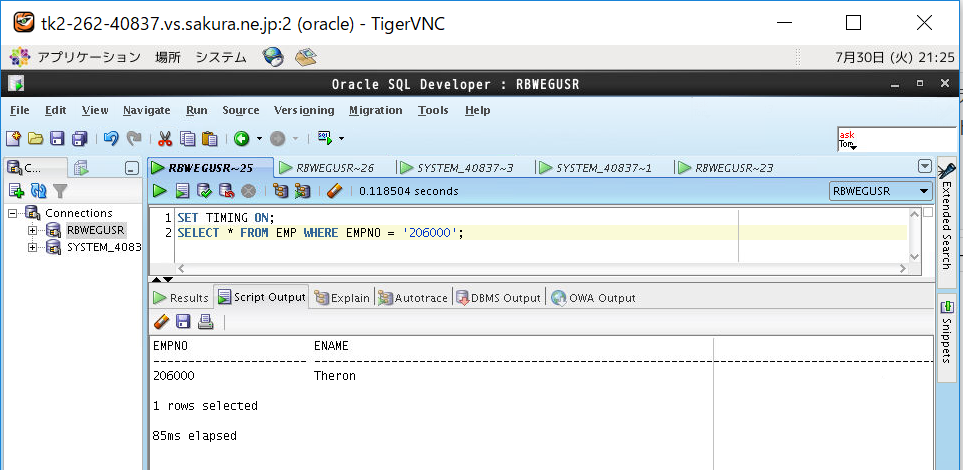
(b)インデックス範囲内の検索(EMPNO=’206000′)
| インデックス有無 | 処理時間 (単位:ms) |
1回目との差分 |
| あり | 5 | -5 |
| なし | 85 | +41 |
<画面キャプチャ:(a)インデックス範囲内の検索(EMPNO=’150000′)>
①インデックスあり表(B木)の実行計画を取得
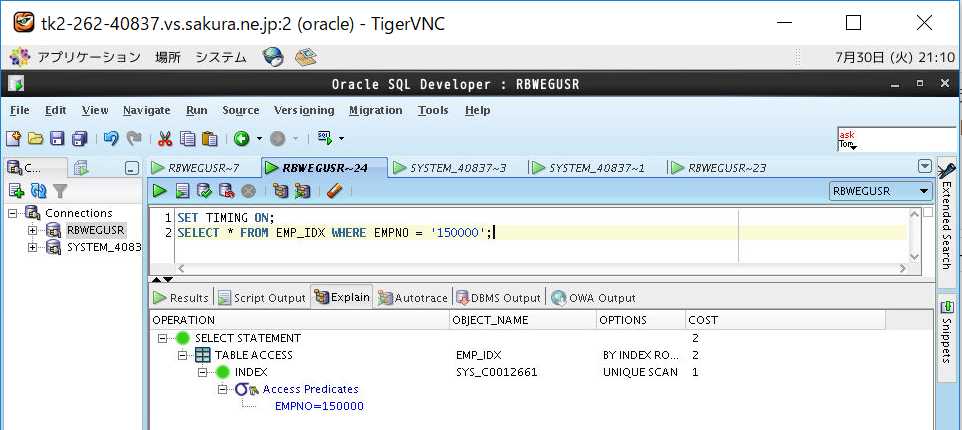
②インデックスあり表(B木)をSELECTして時間計測
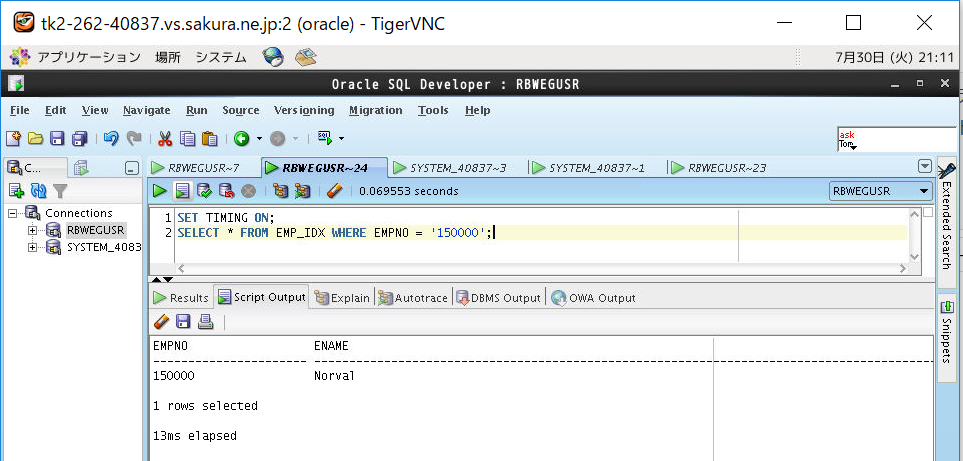
③バッファキャッシュクリア
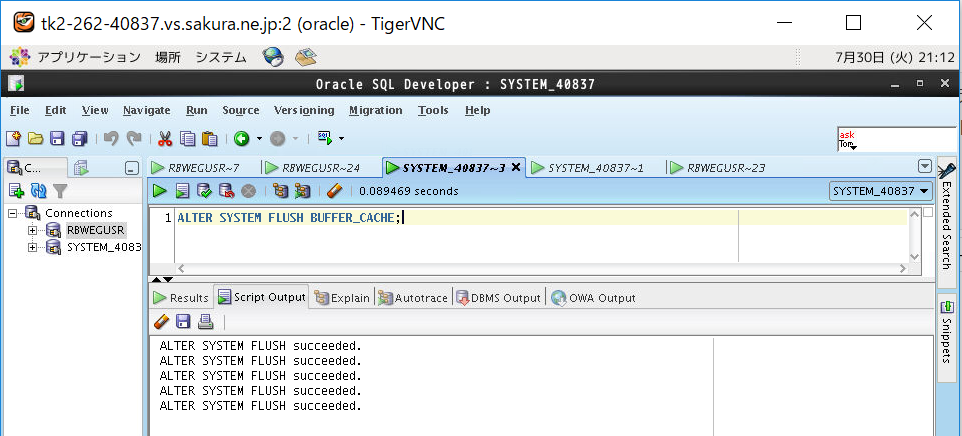
④インデックスなし表の実行計画を取得
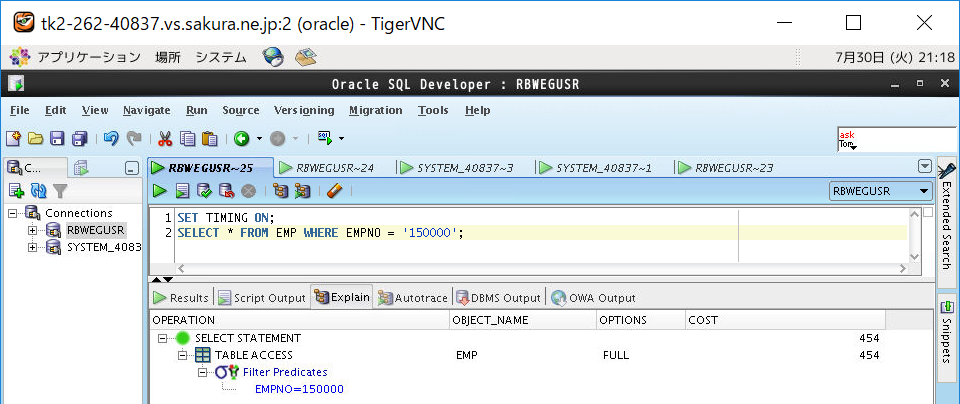
⑤インデックスなし表をSELECTして時間計測
⑥バッファキャッシュクリア
>目次にもどる
<画面キャプチャ:(b)インデックス範囲内の検索(EMPNO=’206000′)>
①インデックスあり表(B木)の実行計画を取得
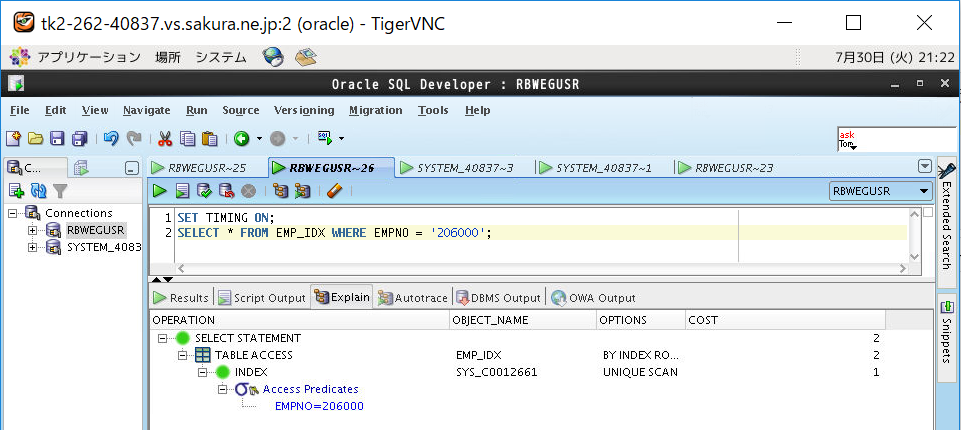
②インデックスあり表(B木)をSELECTして時間計測
③バッファキャッシュクリア
④インデックスなし表の実行計画を取得
⑤インデックスなし表をSELECTして時間計測
⑥バッファキャッシュクリア
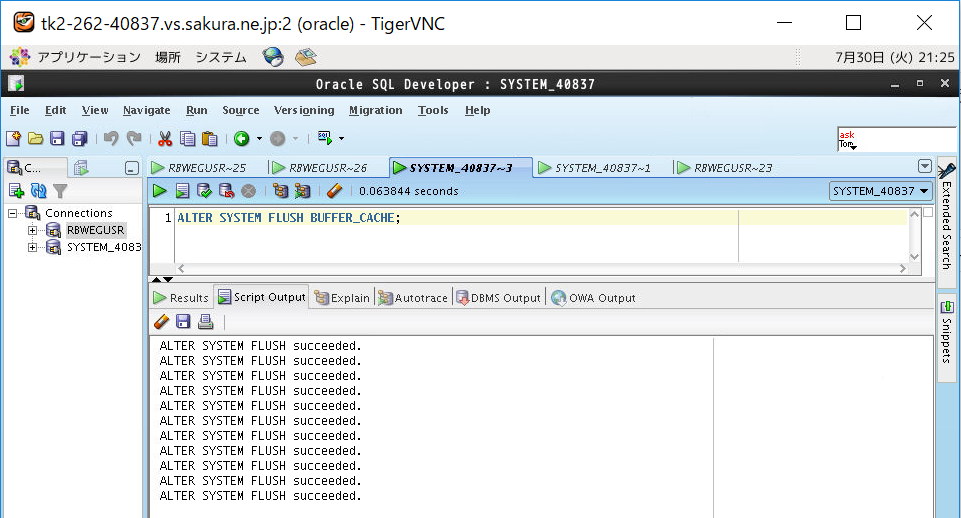
(4-4) インデックス断片化させる(準備)
インデックスはB木のルート→リーフまでの階層数が高くなると効率が低下します。DELTE処理を大量に行うとBツリーのHeight(ツリーの階層数)が高くなるとされている為、実際にDELETE処理を行い意図的に断片化させてHeightを上昇させる事を狙います。下記はEMPNOが3の倍数の場合に行を削除するDELETE文です。
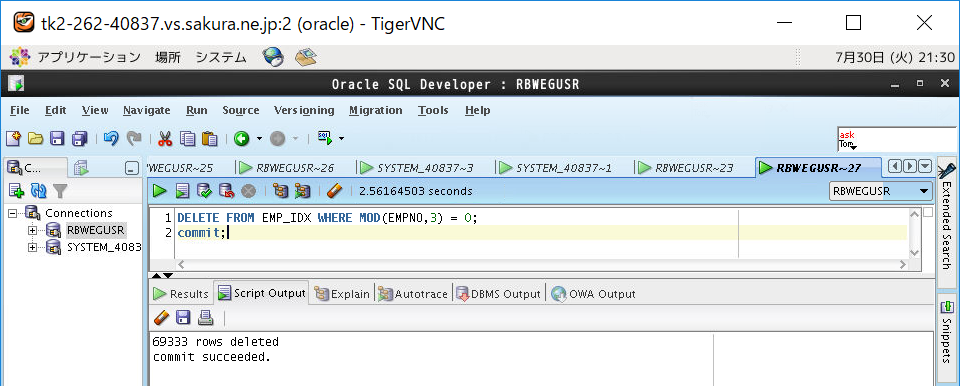
DELETE FROM EMP_IDX WHERE MOD(EMPNO,3) = 0;
EMP表について削除を実施
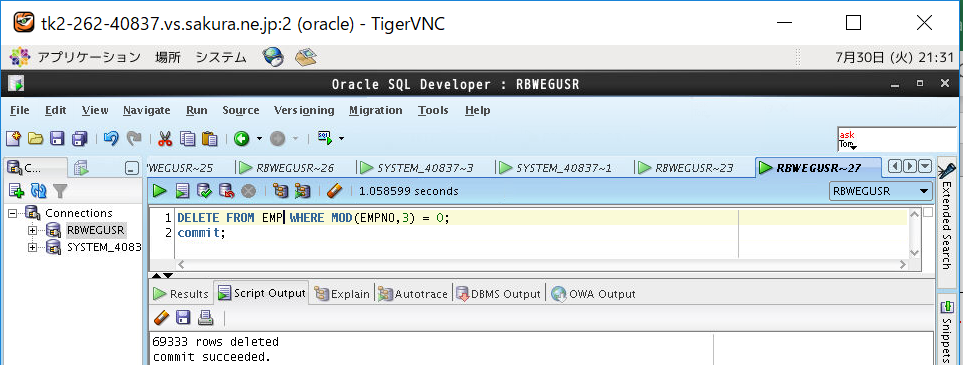
EMP_IDXについて削除を実施
(4-5) 測定&実行計画チェック(3回目)
<想定結果>
・「インデックスなし」は前回とほぼ変わらない
(レコード件数が減っただけのため)
・「インデックスあり」は前回よりも照会時間が遅くなる
(DELETEしてINDEXが最適化されていない状態のため)
<試験結果>
| インデックス有無 | 処理時間 (単位:ms) |
1回目との差分 |
| あり | 16 | +6 |
| なし | 77 | +23 |
<画面キャプチャ>
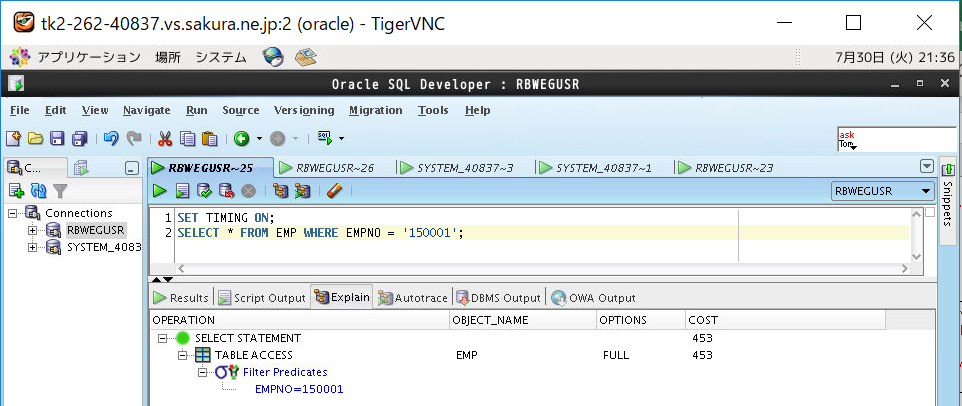
①インデックスあり表(B木)の実行計画を取得
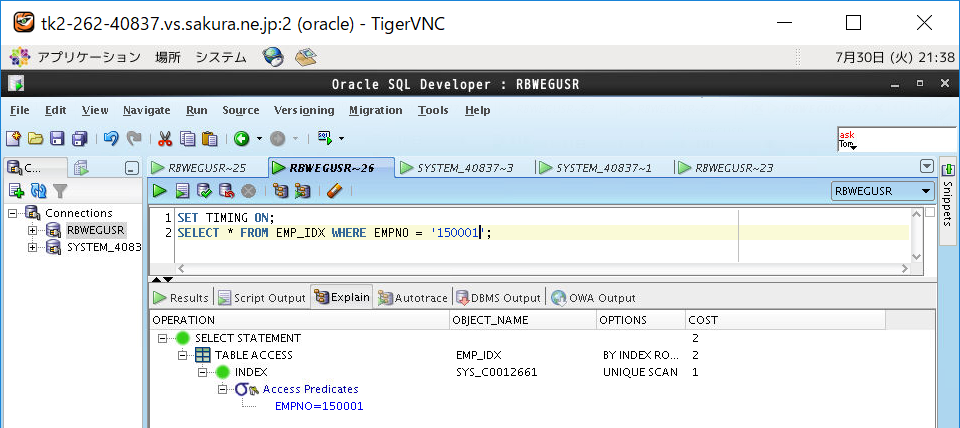
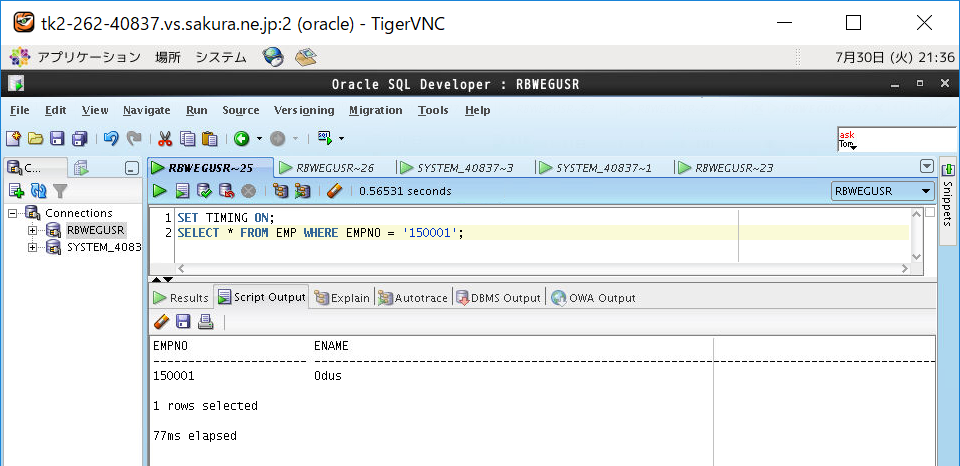
②インデックスあり表(B木)をSELECTして時間計測
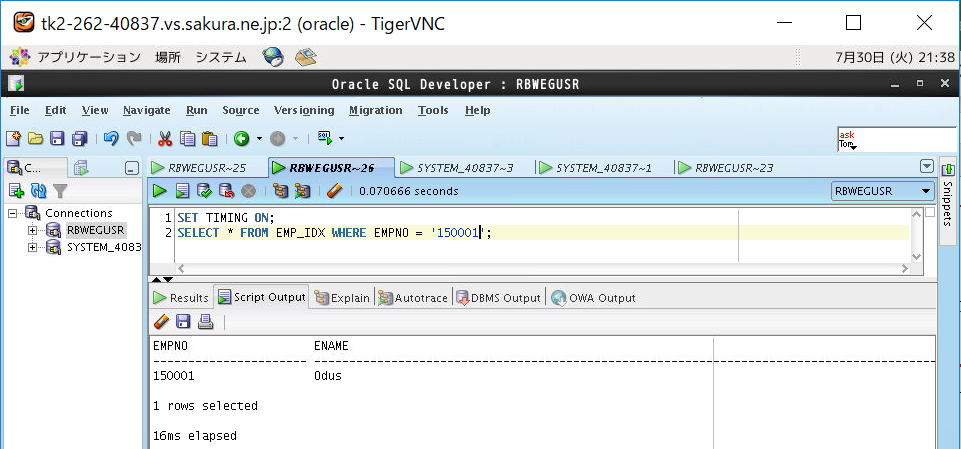
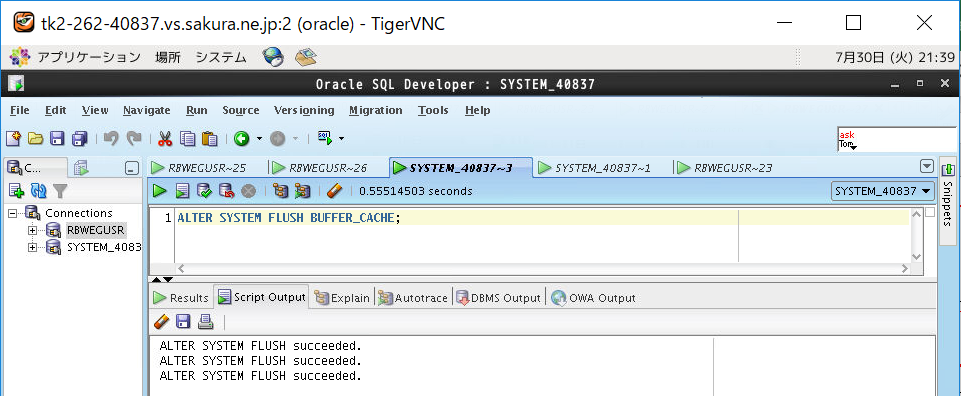
③バッファキャッシュクリア
④インデックスなし表の実行計画を取得
⑤インデックスなし表をSELECTして時間計測
⑥バッファキャッシュクリア
(5) 考察と今後の取り組み
(5-1) 考察
原則はインデックスがあった方が照会速度(SELECT)が速く、4回の測定結果を平均すると「約6.25倍」、時間にすると平均で「約57.75ms」速いという結果になりました。またINSERTに関しては、今回実施した範囲では照会速度(SELECT)への影響はありませんでした。しかしDELETEに関しては、大量に行った後に速度の低下が見られました(約数ms)。インデックスの統計情報(INDEX_STATS)に関しては、DELETEにより「DEL_LF_ROWS」列と「DEL_LF_ROWS_LEN」列に更新が掛かりました。
(5-2) 反省点や次回への課題
・インデックス再編成の確認
今回INSERTとDELETEを2種類実施しましたが、INDEXが断片化するには至りませんでした。なので次回はINDEXを意図的に断片化させる方法を探して実行し、INDEXの再編成の効果測定をしたいです。
・INSERT/DELETEの時間測定
これはミス(測定漏れ)でした。1回目と2回目の間に追加8000行INSERTしたタイミング等で測定を行うべきでした。
>目次にもどる