(0)目次&概説
(1) データベースのインデックスとは
(2) インデックスはどのような場面で使う?
(3) インデックスの主要な方式
(3-1) B木
(3-2) B+木
(3-3) ビットマップ
(4) 各DB製品毎のインデックス概要
(4-1) Oracleの場合
(4-2) SQLServerの場合
(1) データベースのインデックスとは
データベースの性能を向上させる技術です。「検索対象項目」と「レコード格納位置ポインタ」の情報を用いて、位置を特定して直接アクセスを行う事で検索速度を向上させます。インデックスが設定されていない場合はテーブルのフルスキャンする(最初から最後まで1件ずつ見る)ため、時間が掛かってしまいます。ただし、インデックスを設定すると検索対象の表の更新速度が下がるというデメリットもあるので、最適な使い方を見極める必要があります。
(2) インデックスはどのような場面で使う?
インデックスは以下のようなケースで使用します。
①検索対象表の行数が多い場合
⇒行数が少ないと、テーブルのスキャン時間よりもインデックスの検索の方が時間が掛かるため
②検索対象表の更新(UPDATE)が少ない場合
③検索対象表の追加(INSERT)や削除(DELETE)が少ない場合
⇒INSERT、UPDATE、DELETEを行うとインデックスの調整が必要となるため、大量の更新が発生するテーブルに多数のインデックスを設けると更新処理の性能に影響してしまいます。
(3) インデックスの主要な方式
(3-1) B木
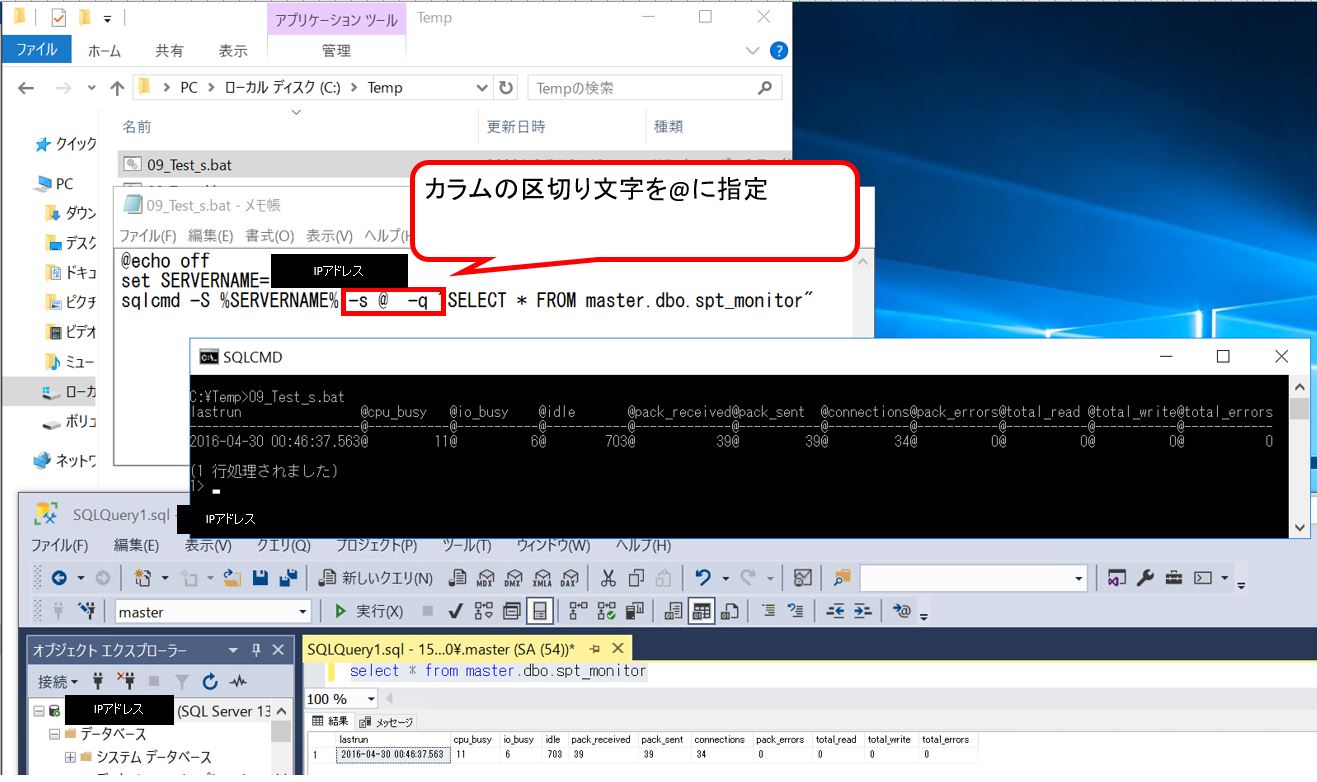
ツリー状の構造をしており、中央値を根(root)にしつつ、その「子」ノードで左側がrootより小さい値、右側がrootよりも大きい値のキー値とデータを保持します。
同様の規則で更に分解した、リーフノードがあります。データの保持は分岐点(子)と、先端(リーフノード)にて保持しています。
強みとして、子ノードにもデータを持てるため、アクセス頻度が高いノードをより根(root)の近くに置く事で速度向上が見込めます。
(3-2) B+木
B木と似ているが、違いとしては以下の通り。
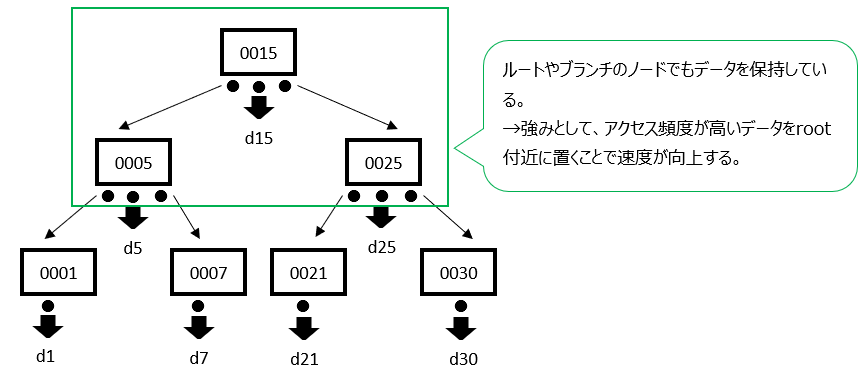
(1) 子ノードではキー値のみを保持して、データはリーフノード(端)にまとめて保持しています。
(2) リーフノードのデータ同士がポインタで接続されているため、範囲での検索スピードが向上する
強みとしては、リーフノードが全てポインタで接続されているため、フルスキャン時に1つの直線的な経路で全てのデータにアクセスできる点です(速い)。
(3-3) ビットマップ
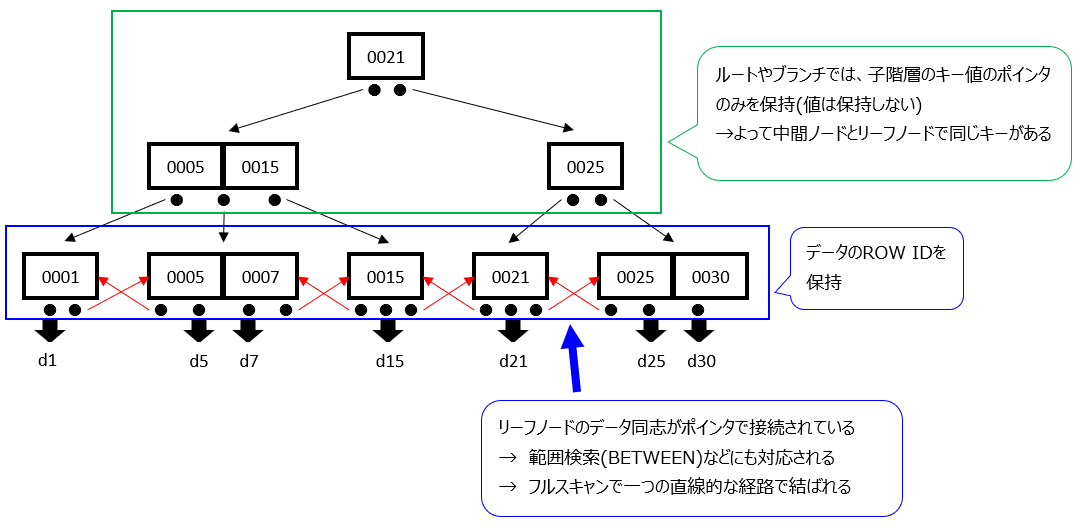
テーブルと対になるビットマップの情報を利用する方式です。テーブルのあるカラムAの値を並べた表(ビットマップ)を作り、レコード毎にカラムAの値の場所にフラグを立てたようなイメージです。
実データの比較をすることなく、ビットの検索のみでレコードを特定できるため、カーディナリティが低い場合は高速で、テーブルをJOINする場合もビット同士のANDやORを行うだけで抽出ができるため高速になります。
(4) 各DB製品毎のインデックス概要
(4-1) Oracleの場合
| カーディナリティ 低 |
カーディナリティ 高 |
|
| 非定型SQL | ビットマップ | – |
| 定型SQL | – | B木 |
(4-2) SQLServerの場合
SQL Serverのインデックスは大きく2種類に分類されます(クラスタ化/非クラスタ化)。代表的な種類とその特徴は以下の通りです。
| クラスタ化 | Clustered | テーブルに1個のみ設定可能(ソートして格納するため)で、主キー作成時に自動的に作成される。B木のリーフノードにデータを保持し、インデックスのキーでソートされた状態でディスクに格納されている。 |
| 非クラスタ化 | Nonclustered | テーブルに999個まで設定可能で、一意キー作成時に自動的に作成される。クラスタ化インデックスと組み合わせて使用可能。 結合条件で頻繁に利用される列に対して利用されます。 |
| 非クラスタ化 ∟複合 |
Unique | 複数の列の組み合わせにより作成されているインデックス。ルート~中間~リーフノードに値を保持するため、速度が低下する恐れがある。 |
| 非クラスタ化 ∟付加 |
Filtered | 上記の複合インデックスで、リーフノードでのみ値を保持したバージョン。 |