(0)目次&概説
(1) テーブル定義の検討項目
(2) データ型について
(2-1) char
(2-2) nchar
(2-3) varchar
(2-4) nvarchar
(3) 桁数とバイト数
(3-1) tinyint
(3-2) smallint
(3-3) int
(4) その他:データベースキャラクターセット
(4-1) キャラクターセットとは?
(4-2) どのような場面で使われる
(1) テーブル定義の検討項目
この節ではDBのテーブル定義において検討が必要となる項目と、それぞれの説明を記載します。
| 論理名 | 実装で使わない別名で、仕様書やコミュニケーションを容易にするために付ける名前。 |
| 物理名 | 実装で使う名前で、DBのカラムを一意に特定する。 |
| PK | RDBでレコードを一意に識別するためのカラム。一意制約+NotNull制約を組み合わせたものと同等。 |
| NotNull | 空値を許容しない設定。例えば従業員テーブルで従業員番号に対して、必ず従業員の名前があるためNOT NULLを設定する。 |
| パーティションキー | ・パーティションにはいくつも種類があり「レンジ」「リスト」「ハッシュ」などがある。 ・Oracleの場合はパーティションは専用のセグメントに格納されます ・表をパーティション化する主な理由 ①データが大規模(2GB以上)の場合 ②期間等で区切れて特定の期間のみ更新される場合 ③操作するデータを限定する事によるパフォーマンス向上(しかしテーブルは同じのためAP的には差を意識せずに済む) |
| インターバル | レンジパーティションの拡張機能で、インターバルを設定しておくと、必要に応じて新しいパーティションを作成してくれます。 (例)四半期の区分 PARTITION Q1 VALUES LESS THAN (TO_DATE(‘2019-04-01′,’yyyy-mm-dd’)) PARTITION Q2 VALUES LESS THAN (TO_DATE(‘2019-07-01′,’yyyy-mm-dd’)) PARTITION Q3 VALUES LESS THAN (TO_DATE(‘2019-10-01′,’yyyy-mm-dd’)) PARTITION Q4 VALUES LESS THAN (TO_DATE(‘2020-01-01′,’yyyy-mm-dd’)) |
| データ型 | カラムのデータ型を指定します(※後述の「データ型」の章を参照) |
| 桁数 | カラムの桁数を指定します(※後述の「桁数」の章を参照) |
| バイト数 | カラムのバイトを指定します(※後述の「桁数」の章を参照) |
| デフォルト値 | カラムのデフォルト値を設定します。 |
| コード値 | コード値を保持するカラムである場合、そのルールを記述する。 |
| インデックス | インデックスを貼ったカラムがあれば、その情報を指定します。 |
(2) データ型について
型名に「var」が付くのは可変長である事を意味し、「n」が先頭に付く場合はUnicode対応(全角にも対応)で、先頭に無い場合はASCII対応です。
(2-1) char
char:固定長の半角文字列
例:char(2)はA1、A2、A3など
(2-2) nchar
nchar:固定長の全角文字列
例:nchar(2)は1金、2金、3金など
(2-3) varchar
varchar:可変長の半角文字列
例:名前とか
(2-4) nvarchar
nvarchar:可変長の全角文字列
例:名前とか
(3) 桁数とバイト数
int型は以下のように、いくつか種類があります。
(3-1) tinyint
tinyint:0~255まで保持可能。
2桁に確実に収まるなら使用可能で、1バイトを消費する。
(3-2) smallint
smallint:-32,768~32,767まで保持可能。
4桁に確実に収まるなら使用可能で、2バイトを消費する。
(3-3) int
int:-2,147,483,648~2,147,483,647まで保持可能。
9桁に確実に収まるなら使用可能で、4バイトを消費する。
nvarcharはUnicodeを扱うため、全角半角問わず同じバイト数で格納する。つまり、nvarchar(10)は半角10文字、全角10文字を格納できる?
(4) その他:データベースキャラクターセット
(4-1) キャラクターセットとは?
下記の記事でも触れていますが、DBの文字列(CHAR,VARCHARなど)に関わる文字コード(正確には①「符号化文字集合」と②「文字符号化方式」)の指定をします。
https://rainbow-engine.com/linux-oracle-db-install4/#title10
①「符号化文字集合」と②「文字符号化方式」については下記の記事を参照頂けたらと思います。
https://rainbow-engine.com/linux-garbled-japanese/
(4-2) キャラクタセット確認用のSQL
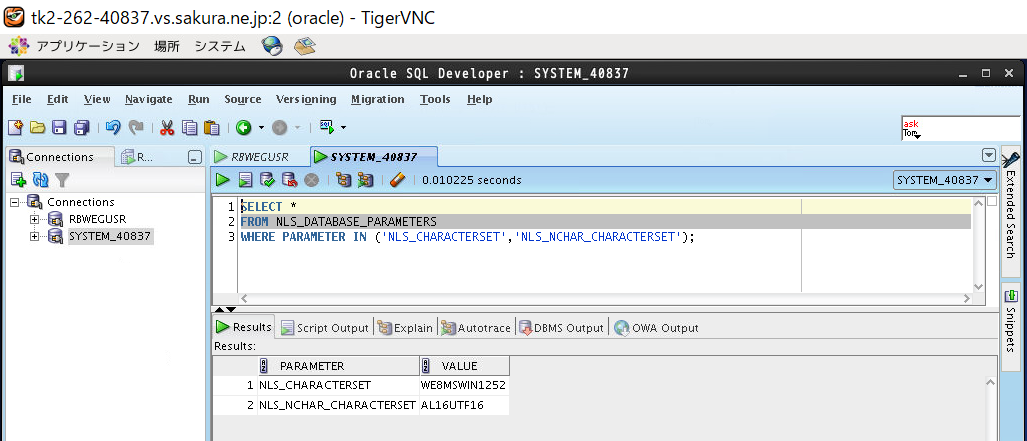
データベースキャラクターセットは以下のSQLを使って確認ができます。
SELECT *
FROM NLS_DATABASE_PARAMETERS
WHERE PARAMETER IN ('NLS_CHARACTERSET','NLS_NCHAR_CHARACTERSET');
(図1)
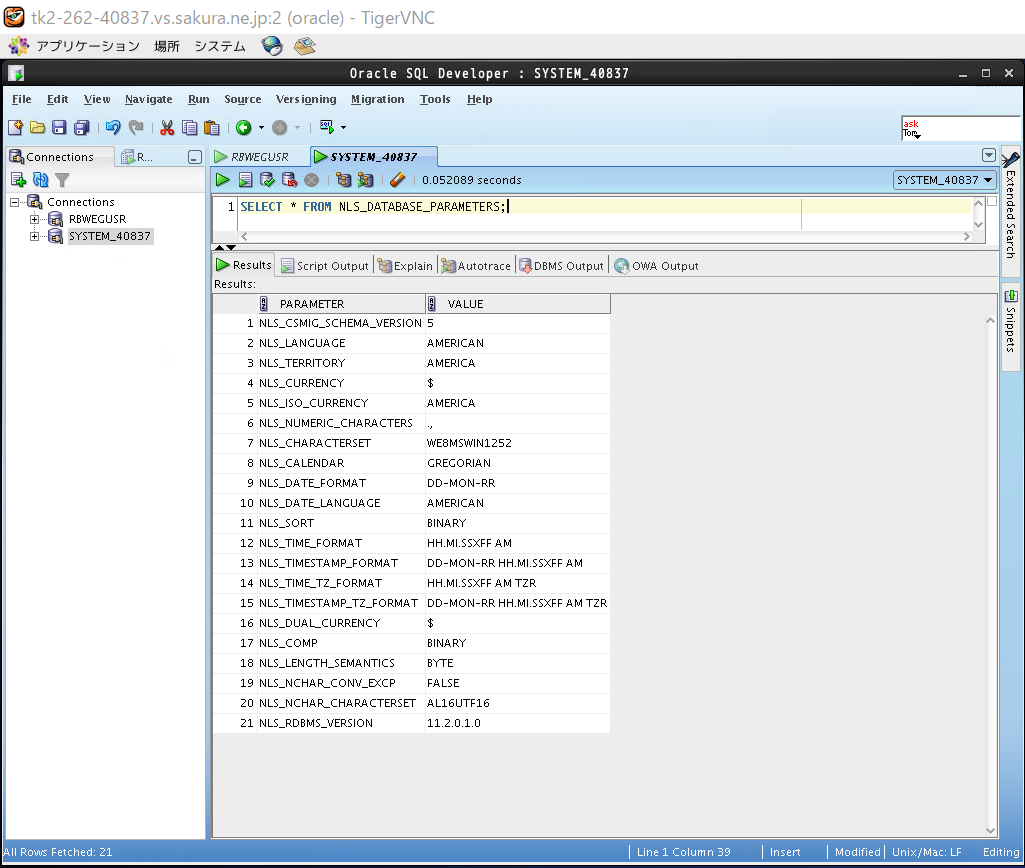
(図2)