<目次>
(1) Pythonでランダムな座標データを生成する方法
(1-1) 使う構文
(1-2) サンプルプログラム
(1-3) 補足:データの座標を全体的にシフトしたい場合
(1) Pythonでランダムな座標データを生成する方法
タイトルの通り、Pythonでランダムな座標データを生成する方法をご紹介します。前提として、今回ご紹介する方法は「numpy」という数値計算を得意とするライブラリを使います。
(1-1) 使う構文
●構文①:numpy.random.RandomState
(構文)
rng = np.random.RandomState(seed)
(説明)
擬似乱数を生成するためのRandomstateインスタンスを生成します。引数seedを与える事で、ランダム状態を保持して、毎回一貫して同じ値を取得する事ができます(≒疑似乱数ジェネレーター=random number generatorの初期化処理)。
→今回は引数に「123」を与え、毎回同じランダムデータで検証できるように、1パターンに固定。
●構文②:numpy.random.RandomState.randn(d0,d1,…,dn)
(構文)
x1 = rng.randn(d0,d1,…,dn)
(説明)
・概要:標準正規分布(standard normal distribution)から、1つ以上のランダムデータのサンプルを返す。
・引数:d0, d1, …, dnはサンプルデータの次元。N個指定すればN次元の配列(d0, d1, …, dnの形)を生成。指定した数の分だけ、その次元でデータ数が生成される。
・戻り値:N次元の配列を生成します。配列にはランダムデータが格納され、平均(mean)=0、分散(variance)=1のガウス分布のデータになっています。
●補足:randnは数学的にはどんなデータなの?
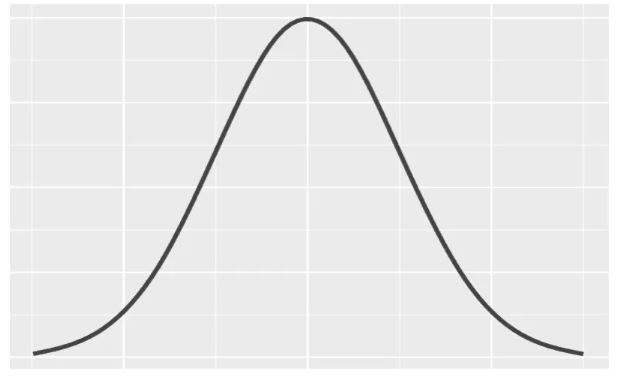
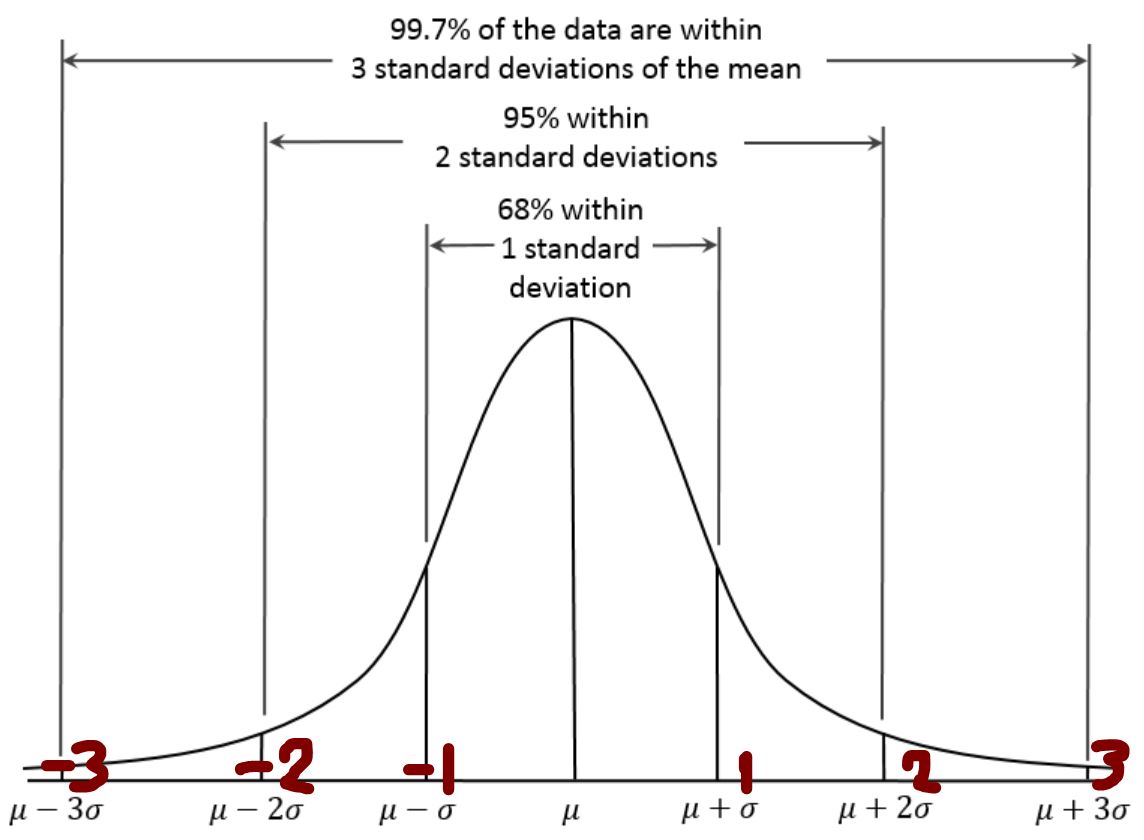
・一言で言うと、(図100)ような正規分布(ガウス分布)のグラフから、ランダムで値を生成します。
(図100)正規分布
↓
・正規分布の密度関数は次のように表されます。
(図101)
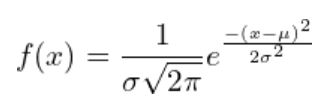
※この時、μ=平均、σ=標準偏差
↓
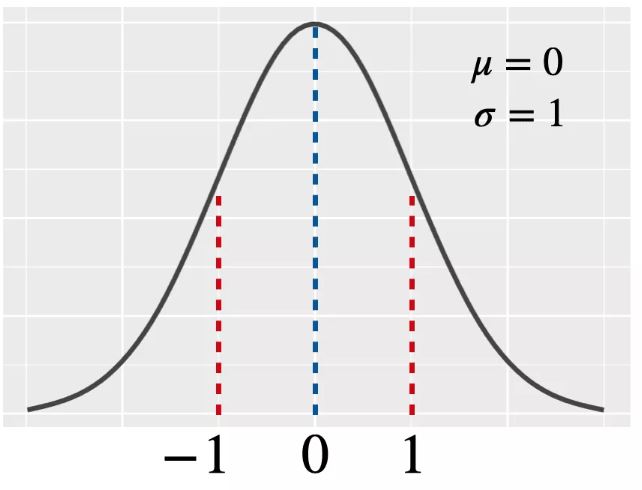
・この中でもrandn関数で出る「標準正規分布」は平均=0(μ=0)、標準偏差=1(σ=1)です。
(図102)
↓
・つまり、式としては次のように簡素化できます。
(図103)
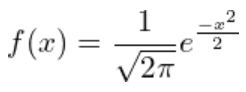
↓
・よって、データの約68%は±1の範囲に入る、約95%は±2の範囲に入るといった形のデータになります。
(図104)
(1-2) サンプルプログラム
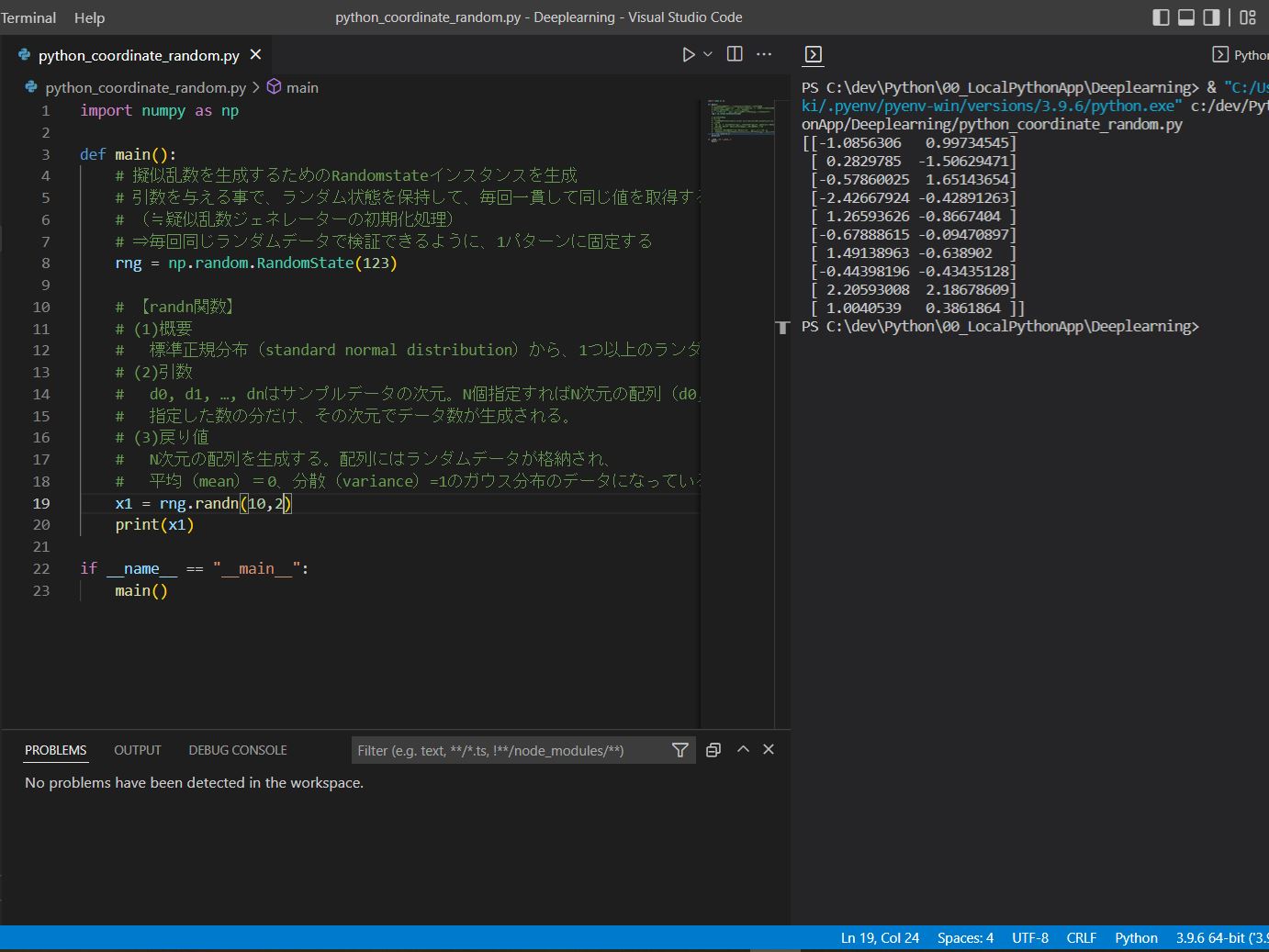
・2次元の例をご紹介します(d0,d1を指定)。
(サンプル①)
import numpy as np
def main():
rng = np.random.RandomState(123)
# 2次元=d0,d1を指定
x1 = rng.randn(5,2)
print(x1)
if __name__ == "__main__":
main()
(実行例①)
[[-1.0856306 0.99734545] [ 0.2829785 -1.50629471] [-0.57860025 1.65143654] [-2.42667924 -0.42891263] [ 1.26593626 -0.8667404 ] [-0.67888615 -0.09470897] [ 1.49138963 -0.638902 ] [-0.44398196 -0.43435128] [ 2.20593008 2.18678609] [ 1.0040539 0.3861864 ]]
(図121)
→固定しているので、何回実行しても同じランダム座標の組合せになります。
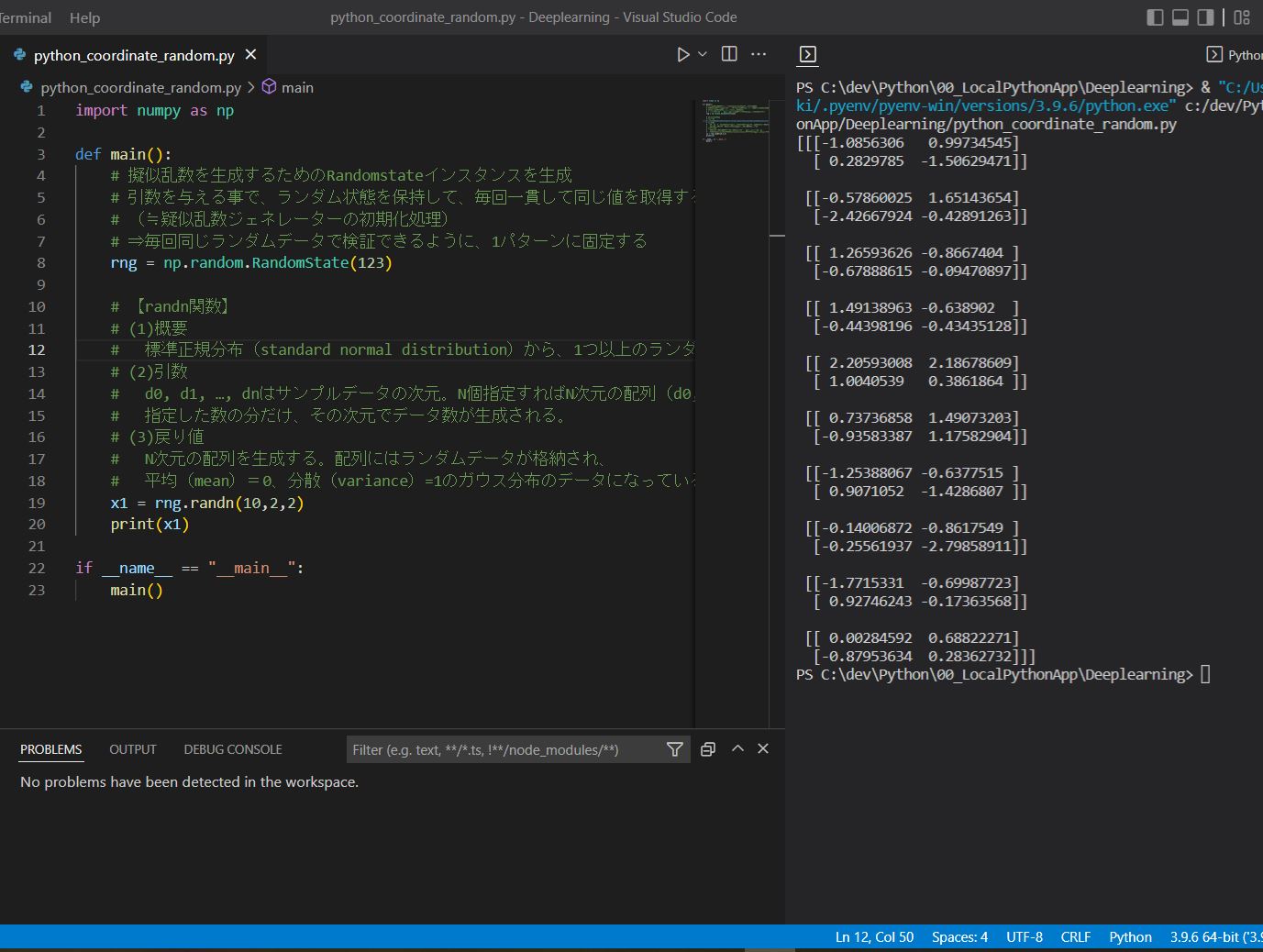
・3次元の例をご紹介します(d0,d1,d2を指定)。
(サンプル②)
import numpy as np
def main():
rng = np.random.RandomState(123)
# 3次元=d0,d1,d2を指定
x1 = rng.randn(10,2,2)
print(x1)
if __name__ == "__main__":
main()
(実行例②)
[[[-1.0856306 0.99734545] [ 0.2829785 -1.50629471]] [[-0.57860025 1.65143654] [-2.42667924 -0.42891263]] [[ 1.26593626 -0.8667404 ] [-0.67888615 -0.09470897]] [[ 1.49138963 -0.638902 ] [-0.44398196 -0.43435128]] [[ 2.20593008 2.18678609] [ 1.0040539 0.3861864 ]] [[ 0.73736858 1.49073203] [-0.93583387 1.17582904]] [[-1.25388067 -0.6377515 ] [ 0.9071052 -1.4286807 ]] [[-0.14006872 -0.8617549 ] [-0.25561937 -2.79858911]] [[-1.7715331 -0.69987723] [ 0.92746243 -0.17363568]] [[ 0.00284592 0.68822271] [-0.87953634 0.28362732]]]
(図122)
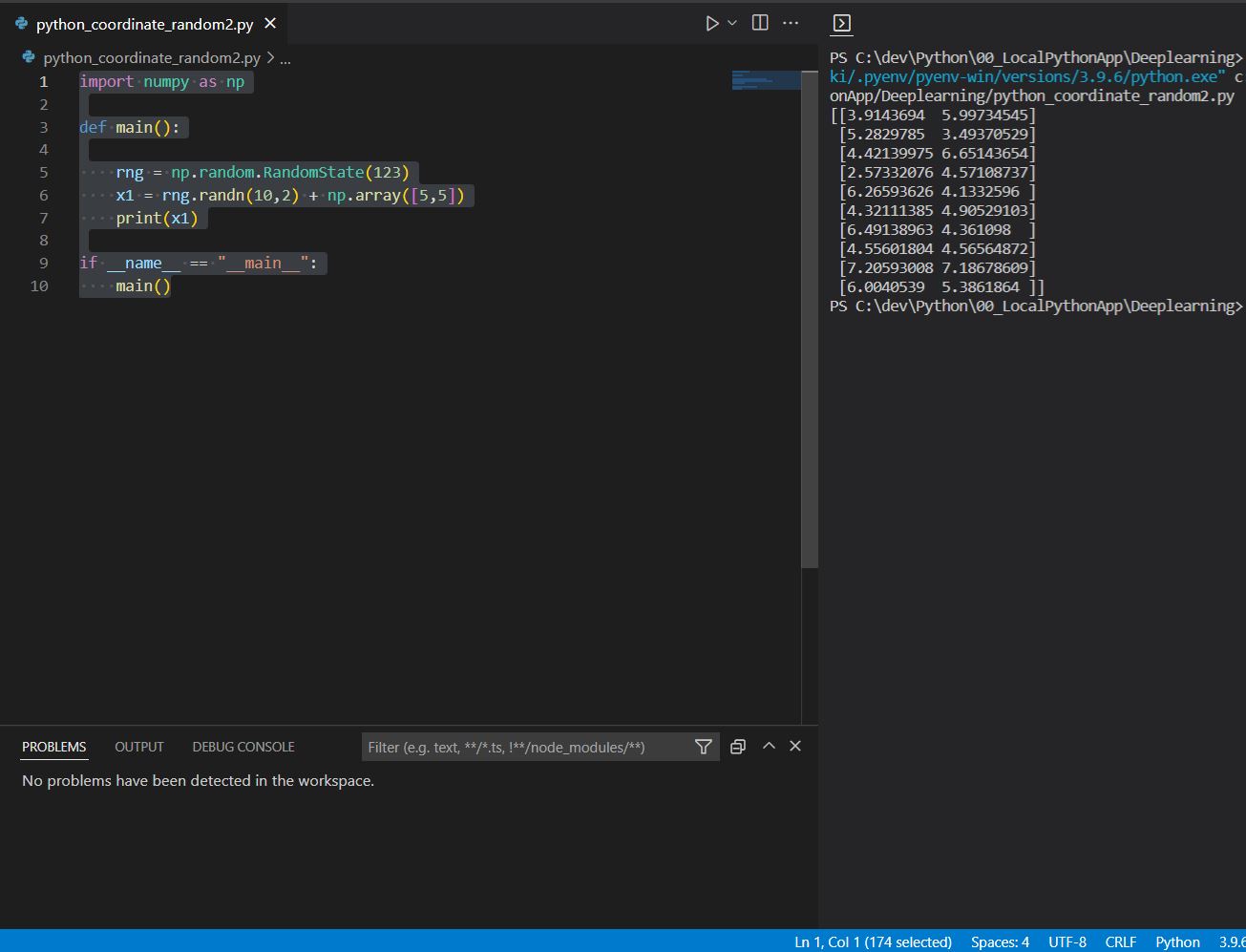
(1-3) 補足:データの座標を全体的にシフトしたい場合
次のような形でnp.array([N,N])を加算する事で、各データを(N,N)だけシフトできます。
(サンプル)
import numpy as np
def main():
rng = np.random.RandomState(123)
x1 = rng.randn(10,2) + np.array([5,5])
print(x1)
if __name__ == "__main__":
main()
(結果例)
[[3.9143694 5.99734545] [5.2829785 3.49370529] [4.42139975 6.65143654] [2.57332076 4.57108737] [6.26593626 4.1332596 ] [4.32111385 4.90529103] [6.49138963 4.361098 ] [4.55601804 4.56564872] [7.20593008 7.18678609] [6.0040539 5.3861864 ]]
(図131)