<目次>
(1) PythonでJSON形式データの値を取得する手順について
(1-1) サンプル①:ローカルのJSONファイルの読み込み(単純構造)
(1-2) サンプル②:ローカルのJSONファイルの読み込み(ネスト構造)
(1-3) サンプル③:APIコールのレスポンス結果(JSON)の値取得(Pandasなし)
(1) PythonでJSON形式データの値を取得する手順について
本記事ではPythonを使って、JSON形式のデータから値を取得するためのサンプルプログラムを2通りご紹介します。
(1-1) サンプル①:ローカルのJSONファイルの読み込み(単純構造)
こちらはローカルにあるテスト用JSON形式ファイルを読み込み、pandasライブラリを使って、データを分解して表形式で取得しています。
(テストデータ)
{
"address1": ["神奈川県"],
"address2": ["横浜市神奈川区"],
"address3": ["羽沢南"],
"kana1": ["カナガワケン"],
"kana2": ["ヨコハマシカナガワク"],
"kana3": ["ハザワミナミ"],
"prefcode": ["14"],
"zipcode": ["2210866"]
}
(サンプルプログラム)
import json
import pandas as pd
def parse_json_pandas_main():
# JSON形式のデータの保存パス
path = r"C:\dev\Python\00_LocalPythonApp\Sample_JsonParse\TestData\TestData_After.json"
# JSONライブラリを用いて、JSONファイルのデータをJSONオブジェクトとしてロード
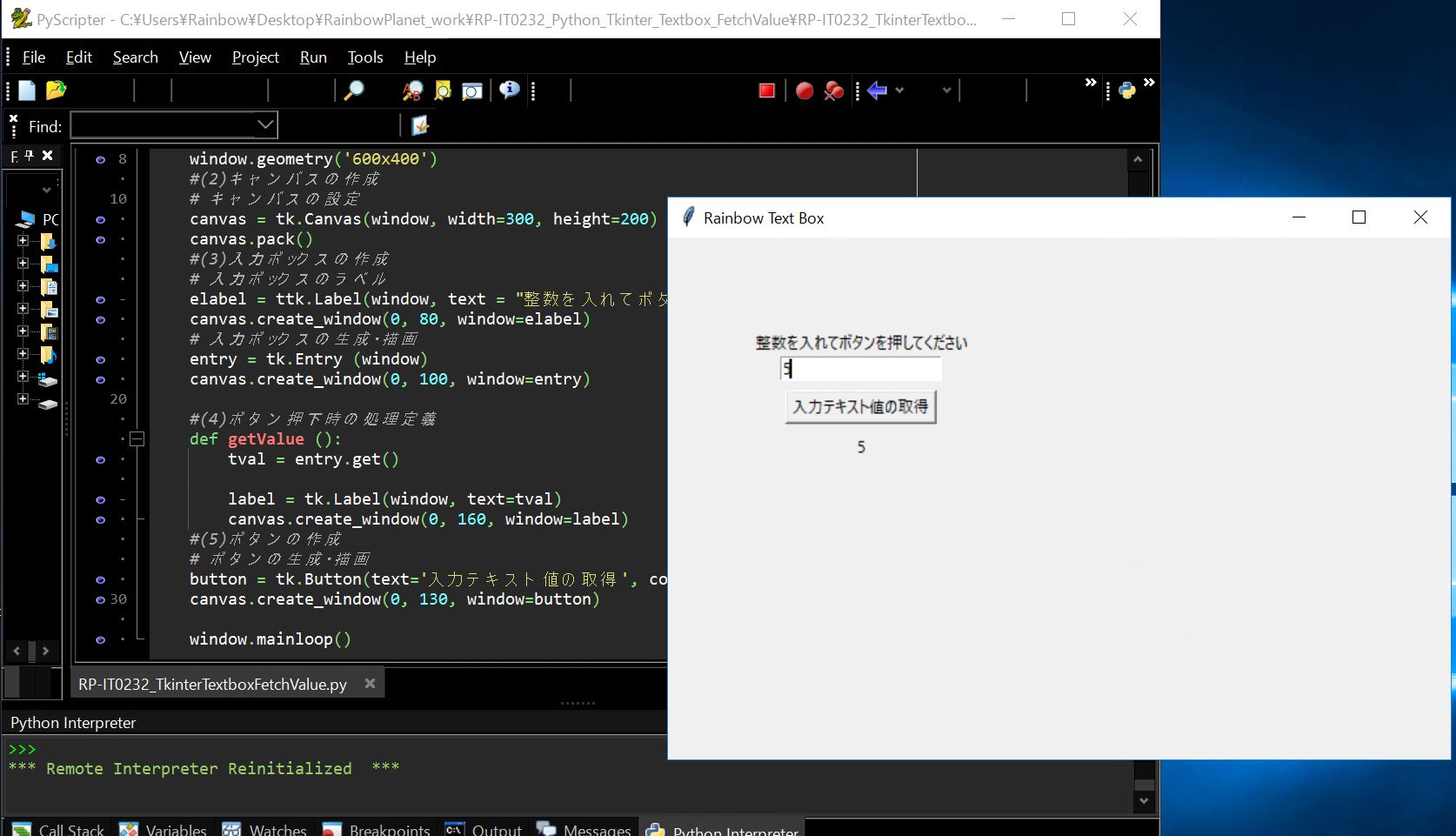
df = pd.read_json(path)
print(df)
if __name__ == "__main__":
parse_json_pandas_main()
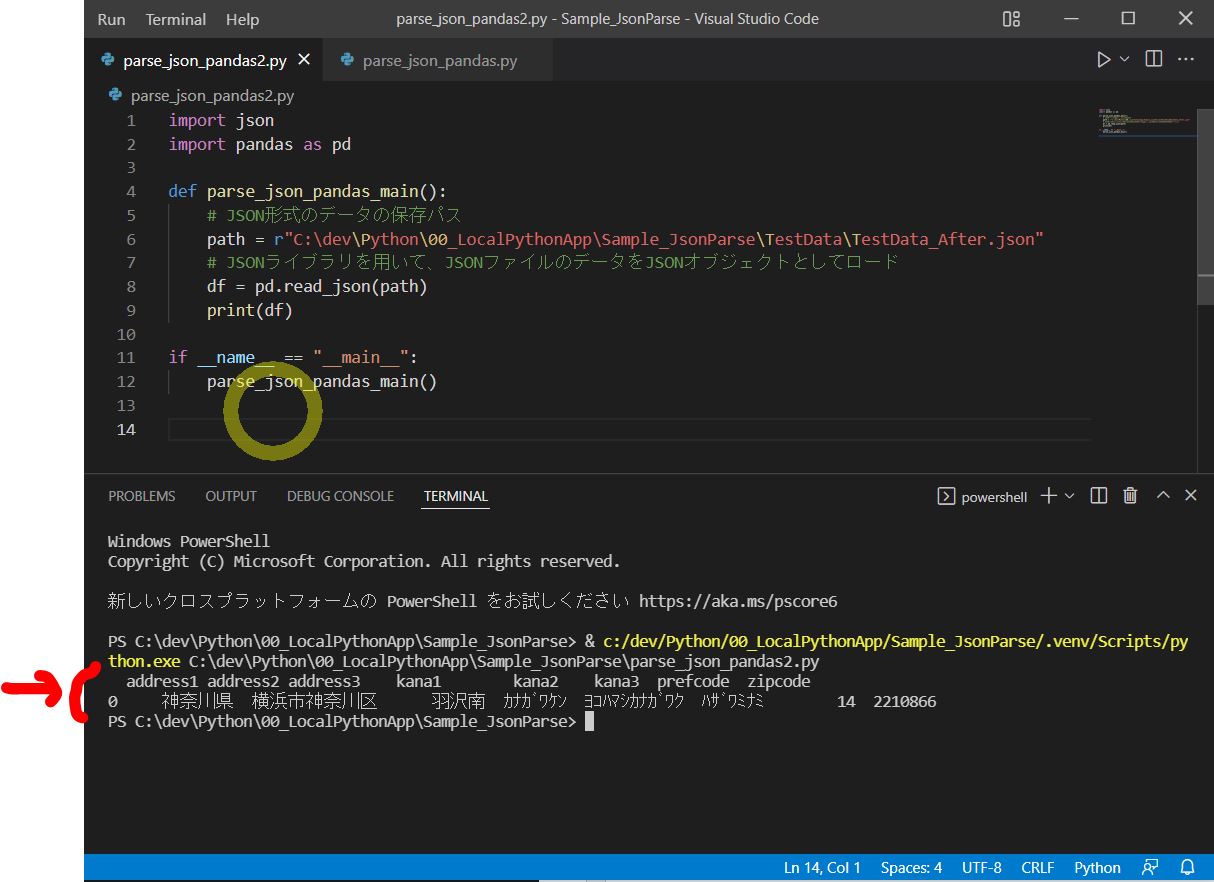
(実行結果)
address1 address2 address3 kana1 kana2 kana3 prefcode zipcode 0 神奈川県 横浜市神奈川区 羽沢南 カナガワケン ヨコハマシカナガワク ハザワミナミ 14 2210866
(図141)pandasのread_jsonで読み込み
(1-2) サンプル②:ローカルのJSONファイルの読み込み(ネスト構造)
こちらはローカルにあるテスト用JSON形式ファイルを読み込み、pandasライブラリを使って、データを分解して表形式で取得しています。特徴として、Key「”students”」に対するValueがネストされています。
(テストデータ)
{
"school_name": "Rainbow小学校",
"class": "1年生",
"students": [
{
"id": "ST001",
"name": "太郎",
"math": 84,
"physics": 74,
"chemistry": 64
},
{
"id": "ST002",
"name": "次郎",
"math": 98,
"physics": 36,
"chemistry": 84
},
{
"id": "ST003",
"name": "三郎",
"math": 87,
"physics": 65,
"chemistry": 76
}]
}
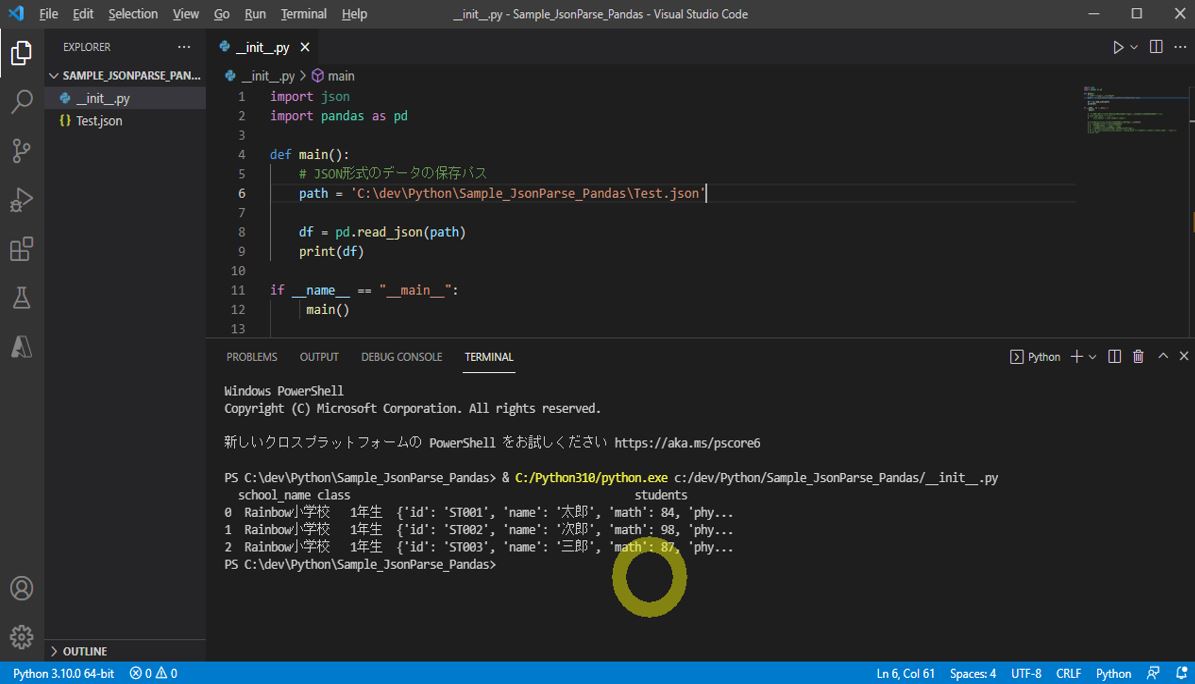
↓Beforeの図
(図131)pandasのread_jsonで単純にJSONを読み込んだだけの場合、こんな感じ
(サンプルプログラム)
import json
import pandas as pd
def parse_json_pandas_main():
# JSON形式のデータの保存パス
path = r"[ご自身のテストデータのパス]\XXXX.json"
# JSONライブラリを用いて、JSONファイルのデータをJSONオブジェクトとしてロード
with open(path,'r',encoding='utf-8', errors='ignore') as f:
json_object = json.loads(f.read())
# pandasの「json_normalize」関数を用いてデータを正規化
# 第1引数:json形式のオブジェクト
# 第2引数:分解対象のデータのkey
# 第3引数:その他、分解した明細に付与するデータ
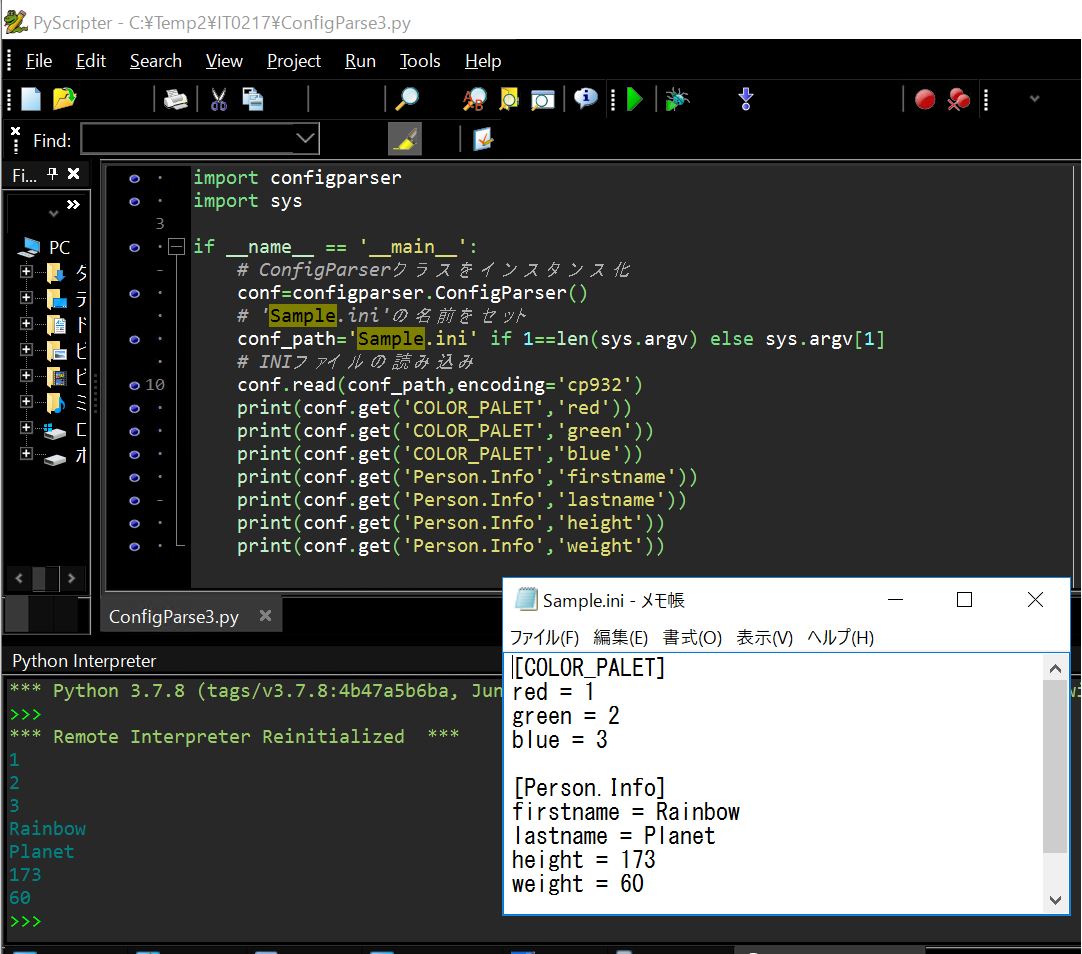
df = pd.json_normalize(json_object, record_path =['students'],meta=['school_name', 'class'])
print (df)
# if __name__ == "__main__":
# main()
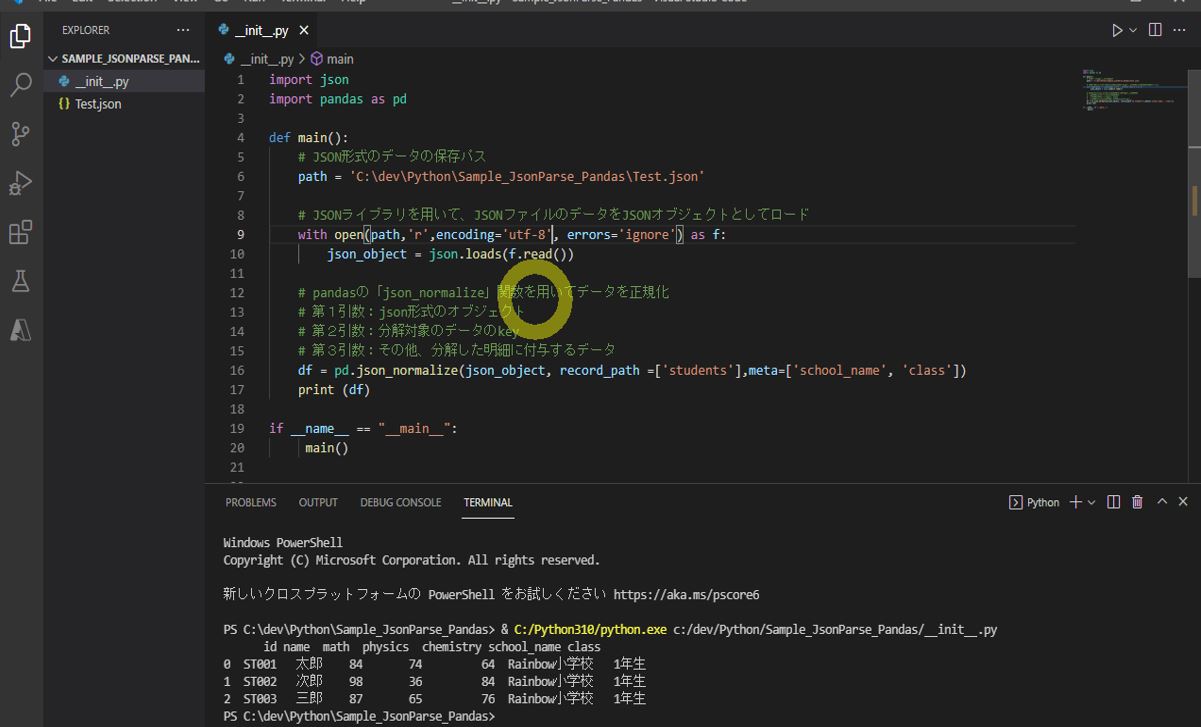
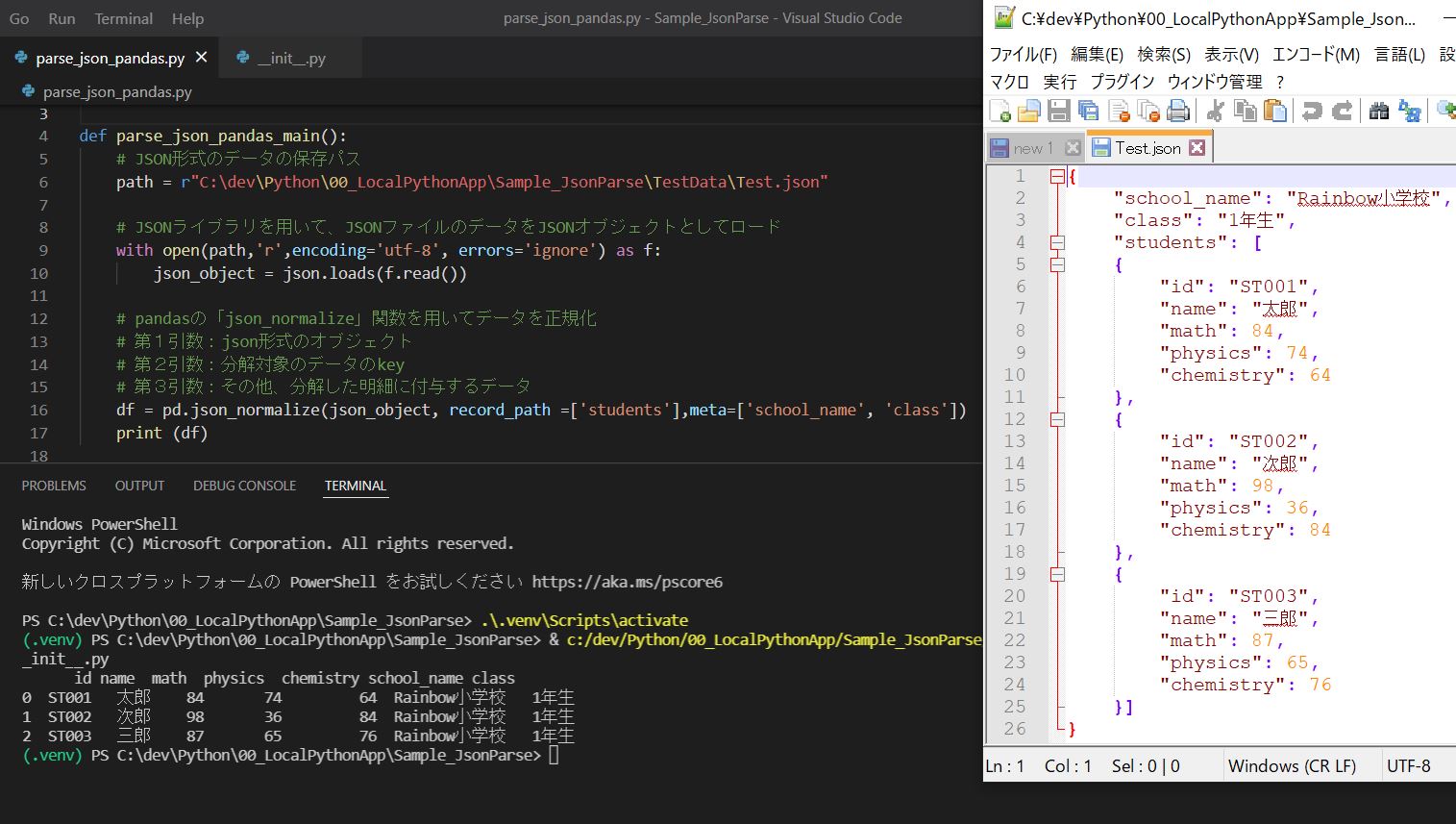
(実行結果)
id name math physics chemistry school_name class 0 ST001 太郎 84 74 64 Rainbow小学校 1年生 1 ST002 次郎 98 36 84 Rainbow小学校 1年生 2 ST003 三郎 87 65 76 Rainbow小学校 1年生
(1-3) サンプル③:APIコールのレスポンス結果(JSON)の値取得(Pandasなし)
こちらは郵便番号APIをコールした結果、返ってきたJSON形式のデータの値を取得しています。
(テストデータ)
{
"message": null,
"results": [
{
"address1": "神奈川県",
"address2": "横浜市神奈川区",
"address3": "羽沢南",
"kana1": "カナガワケン",
"kana2": "ヨコハマシカナガワク",
"kana3": "ハザワミナミ",
"prefcode": "14",
"zipcode": "2210866"
}
],
"status": 200
}
↓Beforeの図
(図120)JSON形式のままになっている
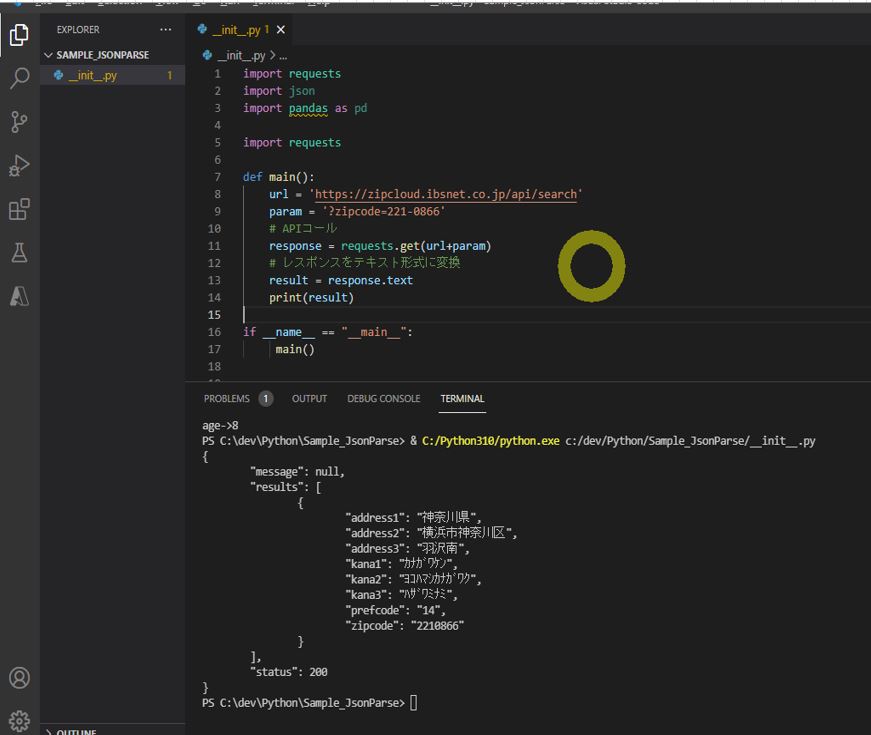
(図120)JSON形式のままになっている
(サンプルプログラム)
import requests
import json
import requests
def main():
url = 'https://zipcloud.ibsnet.co.jp/api/search'
param = '?zipcode=221-0866'
# APIコール
response = requests.get(url+param)
# レスポンスをテキスト形式に変換
result = response.text
# テキスト形式のデータを、JSONディクショナリーとして返却します。
json_object = json.loads(result)
# JSON取り出し関数の実行
padding_count = 0
parse_json(json_object,padding_count)
# JSON取り出し関数
def parse_json(json_object,padding_count):
padding_count += 1
# dict()型のkey/valueの組を順番にループ
for key,value in json_object.items():
# ネスト内部の要素がdict()の場合、再帰的呼び出し(もう一段内部を確認)
if type(value) == type(dict()):
parse_json(value,padding_count)
# ネスト内部の要素がlistの場合
elif type(value) == type(list()):
# list要素を順番にループ
padding_count += 1
for val in value:
# 文字列の場合は、そのkey/valueを出力
if type(val) == type(str()):
print (('[-]'*padding_count+':')+str(key)+'->'+str(val))
# list()型の場合は中身をループして、そのkey/valueを出力
# →listについては、これ以上のネストは追わない(2段階のみを想定)
elif type(val) == type(list()):
padding_count += 1
for i in val:
print (('[-]'*padding_count+':')+str(key)+'->'+str(i))
padding_count -= 1
# dict()の場合、再帰的呼び出し(もう一段内部を確認)
else:
parse_json(val,padding_count)
padding_count -= 1
# valueが更なるネストなく(dict()でもlist()でもない)単なる値の場合は、そのkey/valueを出力
else:
print (('[-]'*padding_count+':')+str(key)+'->'+str(value))
padding_count -= 1
if __name__ == "__main__":
main()
(実行結果)
[-]:message->None [-][-][-]:address1->神奈川県 [-][-][-]:address2->横浜市神奈川区 [-][-][-]:address3->羽沢南 [-][-][-]:kana1->カナガワケン [-][-][-]:kana2->ヨコハマシカナガワク [-][-][-]:kana3->ハザワミナミ [-][-][-]:prefcode->14 [-][-][-]:zipcode->2210866 [-]:status->200
↓Afterの図
(図121)階層を認識しつつ値を取得できている
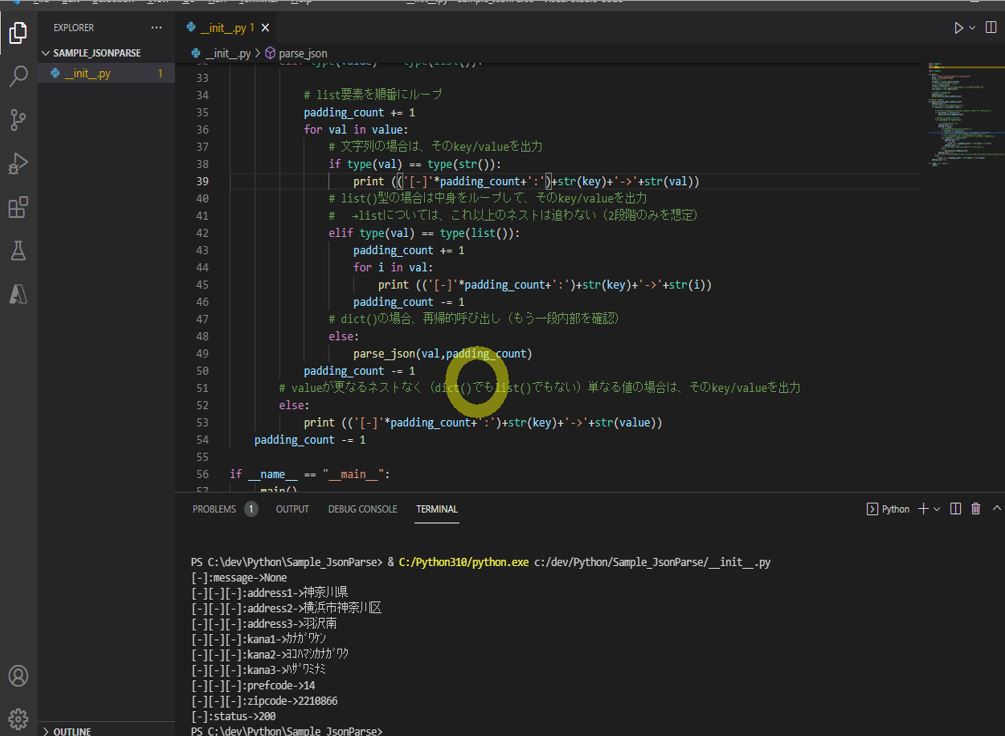
(図121)階層を認識しつつ値を取得できている
元データと比較するとこんな感じです
(図122)