(0)目次&概説
(1) エラー対応1:sqlalchemy.exc.ArgumentError
(1-1) 発生状況・エラーメッセージ
(1-1-1) エラーメッセージ
(1-1-2) エラーとなったソース
(1-2) 原因
(1-3) 対処方法
(2) エラー2:Could not reflect: requested table(s)
(2-1) 発生状況・エラーメッセージ
(2-1-1) エラーメッセージ
(2-1-2) エラーとなったソース
(2-2) 原因
(2-3) 対処方法
(1) エラー対応1:sqlalchemy.exc.ArgumentError
(1-1) 発生状況・エラーメッセージ
Web上で公開されているcsvデータのURLに対して「requests」パッケージの「get」関数を用いてデータを取得し、それをPandasの「read_csv」関数でDataframeに入れてから「to_sql」関数でOracleDBのテーブルにINSERTしようとした際にこのエラーに遭遇しました。
(1-1-1) エラーメッセージ
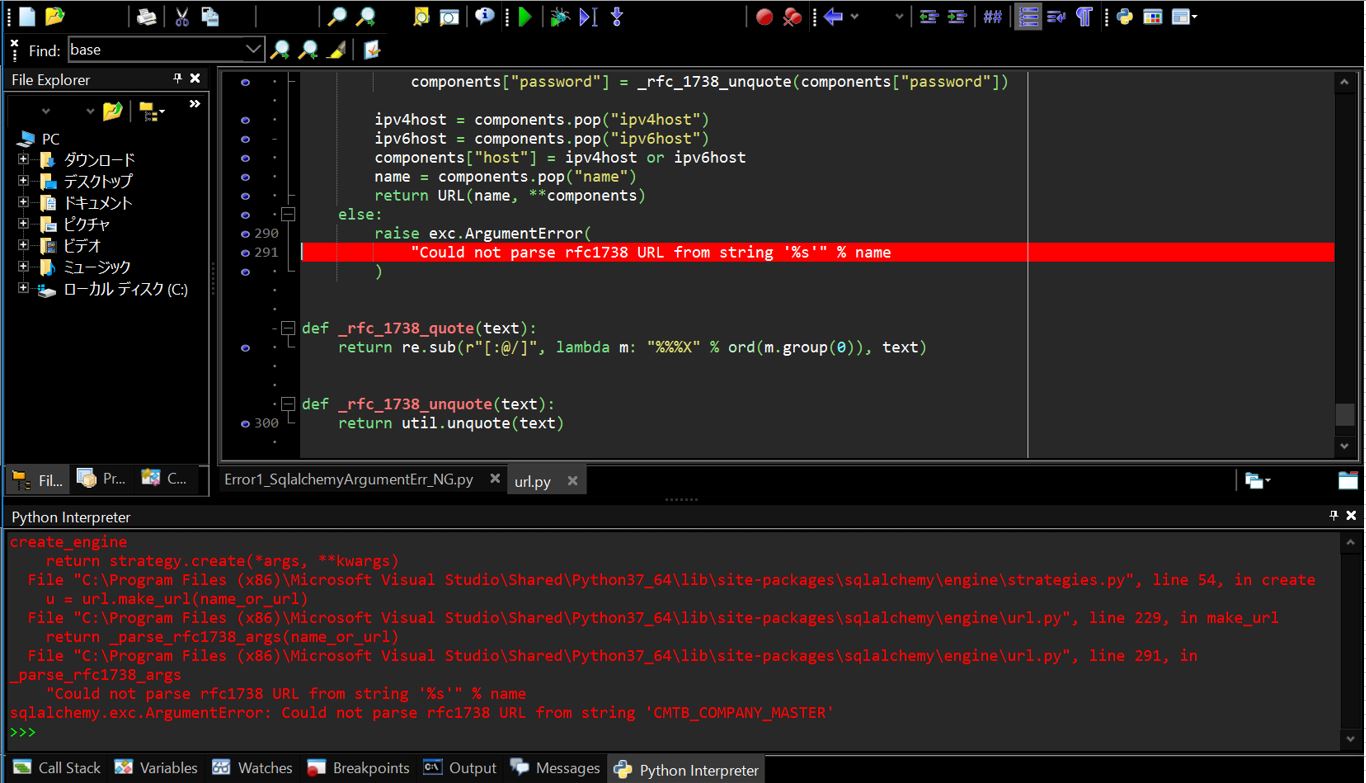
sqlalchemy.exc.ArgumentError: Could not parse rfc1738 URL from string '[Table name]'
(1-1-2) エラーとなったソース
import datapackage
import cx_Oracle
import sqlalchemy
import pandas as pd
import requests
from io import StringIO
def main():
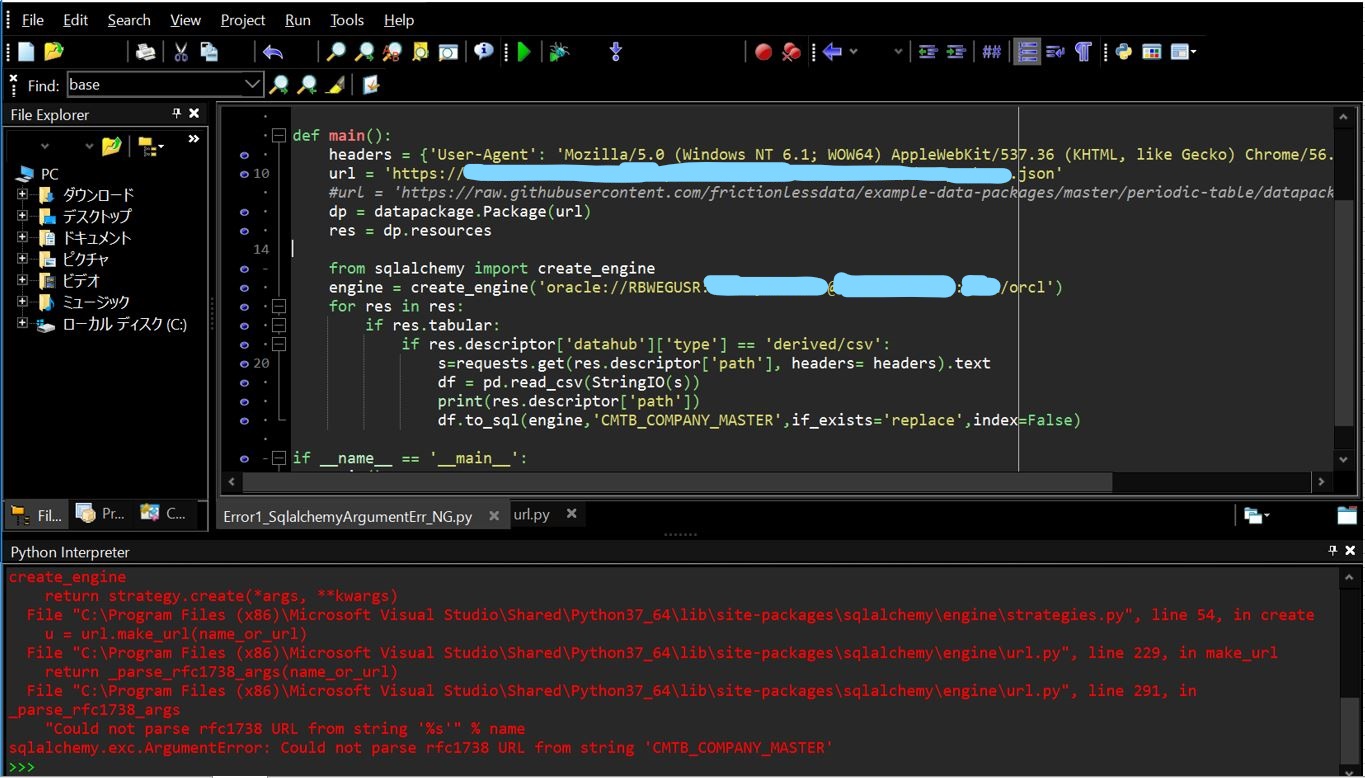
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.76 Safari/537.36'}
url = 'https://[your URL].json'
dp = datapackage.Package(url)
res = dp.resources
from sqlalchemy import create_engine
engine = create_engine('oracle://[your schema]:[your password]@[hostname]:[port]/[sid]')
for res in res:
if res.tabular:
if res.descriptor['datahub']['type'] == 'derived/csv':
s=requests.get(res.descriptor['path'], headers= headers).text
df = pd.read_csv(StringIO(s))
print(res.descriptor['path'])
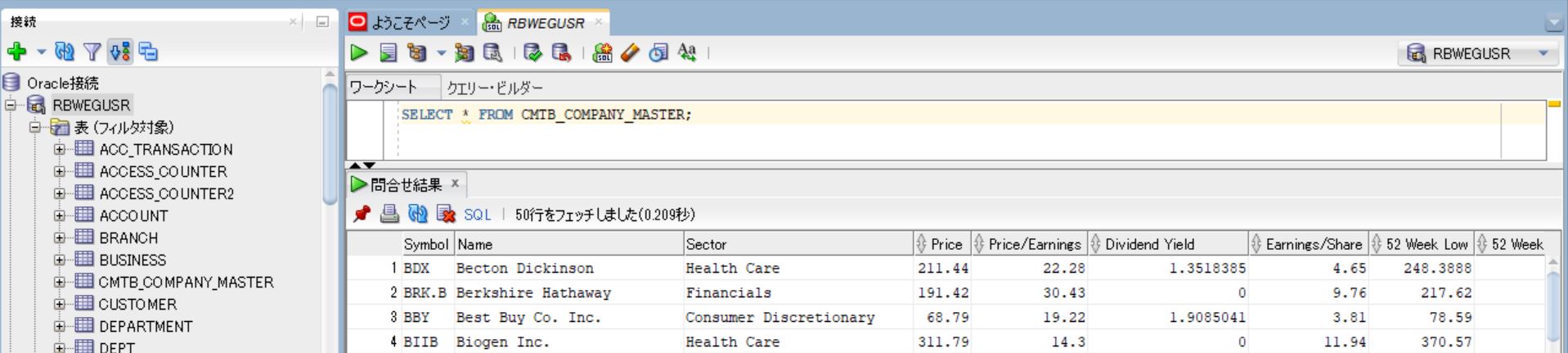
df.to_sql(engine,'CMTB_COMPANY_MASTER',if_exists='replace',index=False)
if __name__ == '__main__':
main()
(図101)
(1-2) 原因
引数の順番が正しく指定されていなかったためでした。「to_sql」関数は暗黙の「self」を除いた場合の第1引数は「SQLのテーブル名」で第2引数が”create_engine”関数の実行結果(sqlalchemy.engine.base.Engine)ですが、上記の例ではこれが逆になっているためにエラーとなっています。
(※本来はEngineインスタンス(「Engine(oracle://[your schema]:***@[hostname]:[port]/orcl)」のような文字列)を想定していた所、テーブル名を誤って引数として与えたため)
参考:Pandasの「to_sql」の説明
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_sql.html
(1-3) 対処方法
上記の第1引数”engine”と第2引数の”CMTB_COMPANY_MASTER”の順番を逆にしたら、当該エラーは起こらなくなりました。
(ただし、今度は後述の別のエラーに遭遇しますが・・)
df.to_sql('CMTB_COMPANY_MASTER',engine,if_exists='replace',index=False)
(2) エラー2:Could not reflect: requested table(s)
(2-1) 発生状況・エラーメッセージ
(2-1-1) エラーメッセージ
sqlalchemy.exc.InvalidRequestError: Could not reflect: requested table(s) not available in Engine(oracle://[your schema]:***@[hostname]:[port]/orcl): ([your table name])
(2-1-2) エラーとなったソース
前の章からの主な差分箇所は以下です。
①SQLAlchemyの”create_engine”でEngineオブジェクトを作りDB接続しています。
②上記のEngineオブジェクトを用いてPandasの「to_sql」でDBのテーブルにレコードをINSERTしています。
import datapackage
import cx_Oracle
import sqlalchemy
import pandas as pd
import requests
from io import StringIO
def main():
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.76 Safari/537.36'}
url = 'https://[your URL].json'
dp = datapackage.Package(url)
res = dp.resources
from sqlalchemy import create_engine
engine = create_engine('oracle://[your schema]:[password]@[hostname]:[port]/[sid]')
for res in res:
if res.tabular:
if res.descriptor['datahub']['type'] == 'derived/csv':
s=requests.get(res.descriptor['path'], headers= headers).text
df = pd.read_csv(StringIO(s))
print(res.descriptor['path'])
df.to_sql('CMTB_COMPANY_MASTER',engine,if_exists='replace',index=False)
if __name__ == '__main__':
main()
(図201)
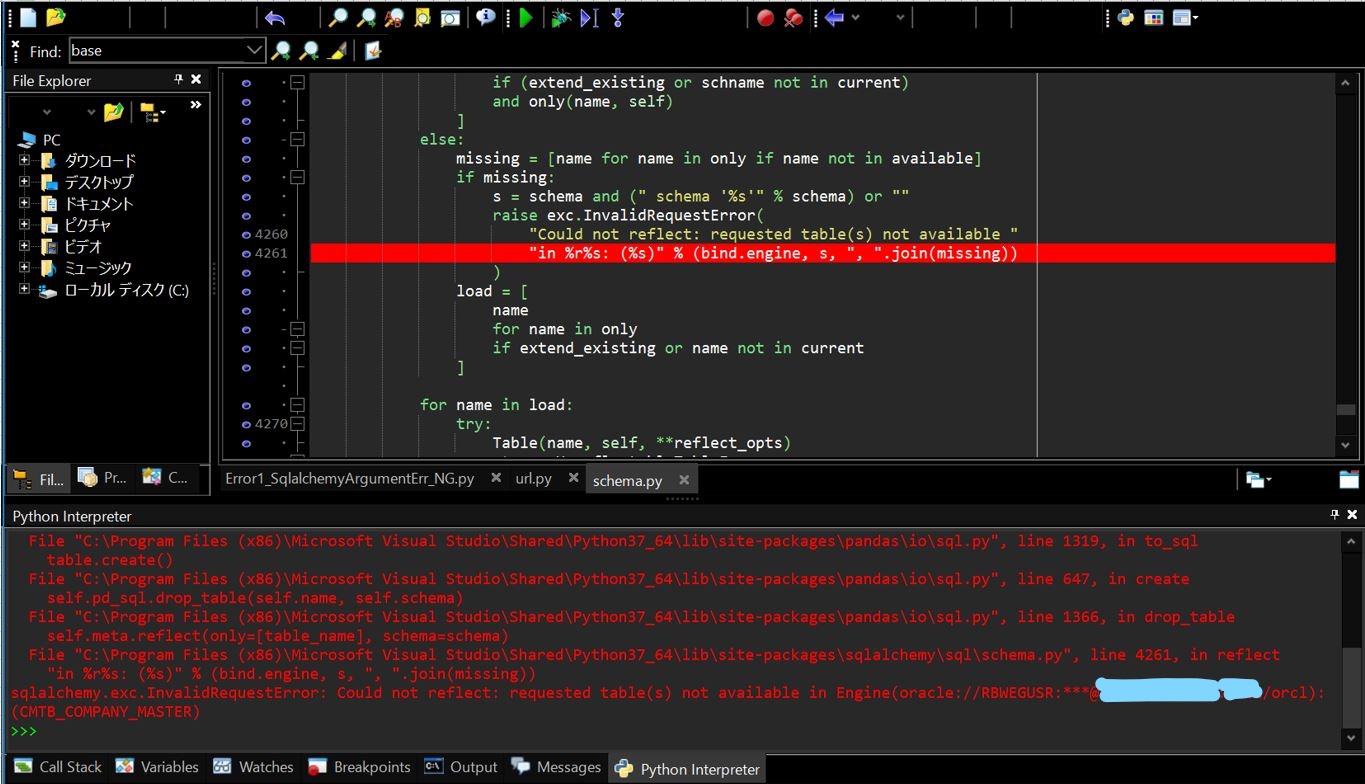
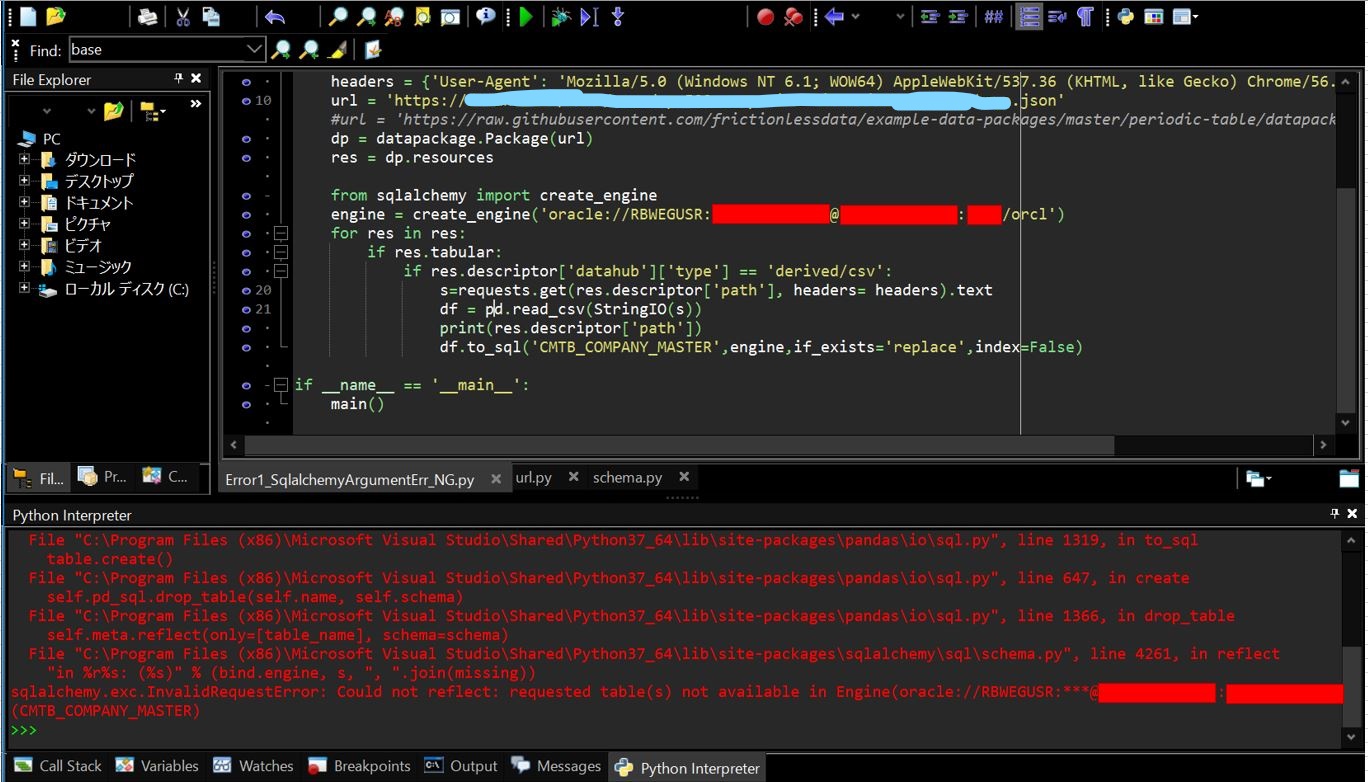
(2-2) 原因
「引数のテーブル名」と「DB側のテーブル名」がマッチしていない事が原因でした。どうやらDB側ではテーブル名を小文字に変換しているため、引数で大文字のテーブル名を与えると不一致でエラーとなるようです。実際に警告としてもその旨の文章が出ており「Consider using lower case table names」と小文字を推奨する記載も見受けられます。
C:\Program Files (x86)\Microsoft Visual Studio\Shared\Python37_64\lib\site-packages\pandas\io\sql.py:1336: UserWarning: The provided table name 'CMTB_COMPANY_MASTER' is not found exactly as such in the database after writing the table, possibly due to case sensitivity issues. Consider using lower case table names. warnings.warn(msg, UserWarning)
(2-3) 対処方法
テーブル名をstr型の変数に代入して「.lower()」メソッドで小文字変換することでミスマッチを防止できます。
■修正前:
df.to_sql('CMTB_COMPANY_MASTER',engine,if_exists='replace',index=False)
■修正後:
tab_name = 'CMTB_COMPANY_MASTER' df.to_sql(tab_name.lower(),engine,if_exists='replace',index=False)
(図202)
・エラーは解消
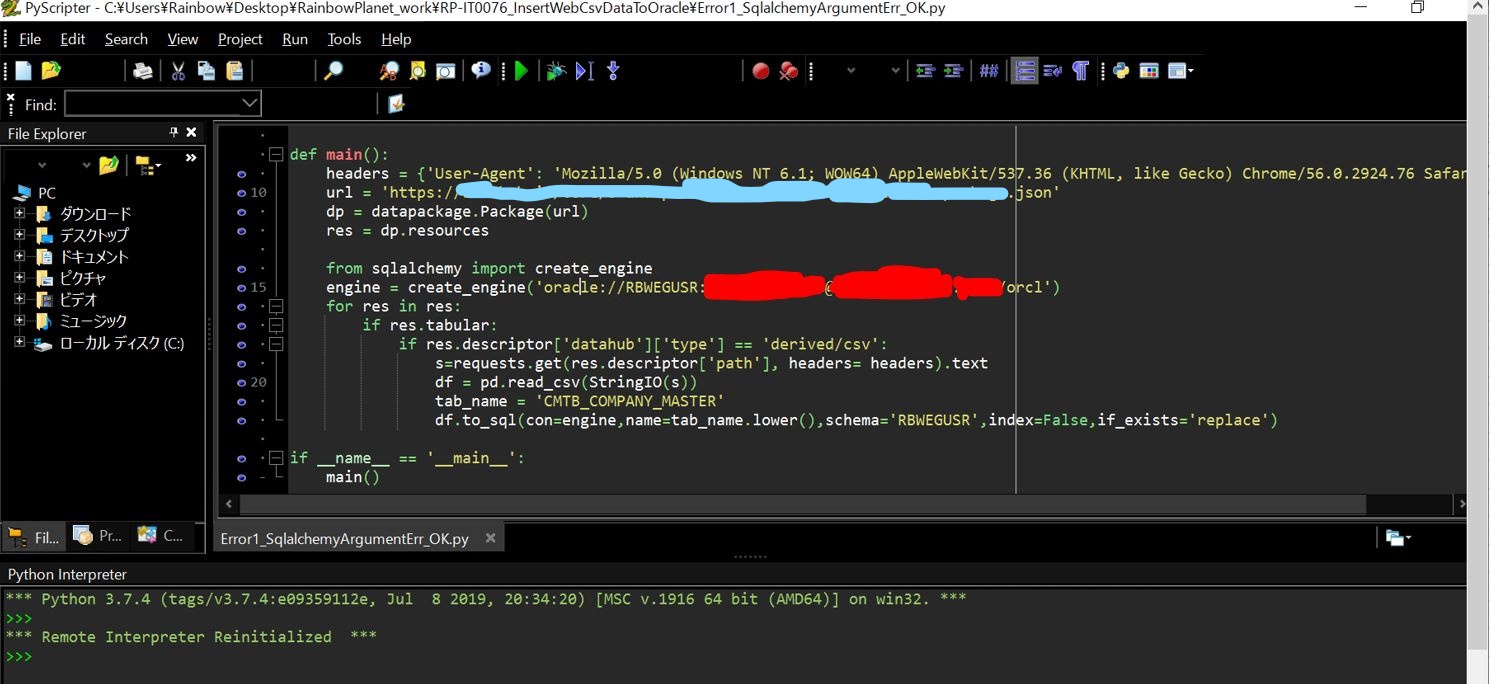
↓
・テーブルにも正常にレコードが格納されている