<目次>
Azure Cognitive Searchを行うPythonプログラム(ドキュメント検索)
STEP0:前提条件
STEP1:キーとURLの取得
STEP2:セマンティック検索の有効化
STEP3:サンプルプログラムの準備
STEP4:動かし方
Azure Cognitive Searchを行うPythonプログラム(ドキュメント検索)
やりたいこと
・Azure Cognitive Searchのセマンティック検索をPythonで行いたい
(備考)
通常の検索は下記を参照(セマンティック検索を使わない検索)
STEP0:前提条件
以下記事に沿って「セマンティック検索」の疎通が済んでいること
STEP1:キーとURLの取得
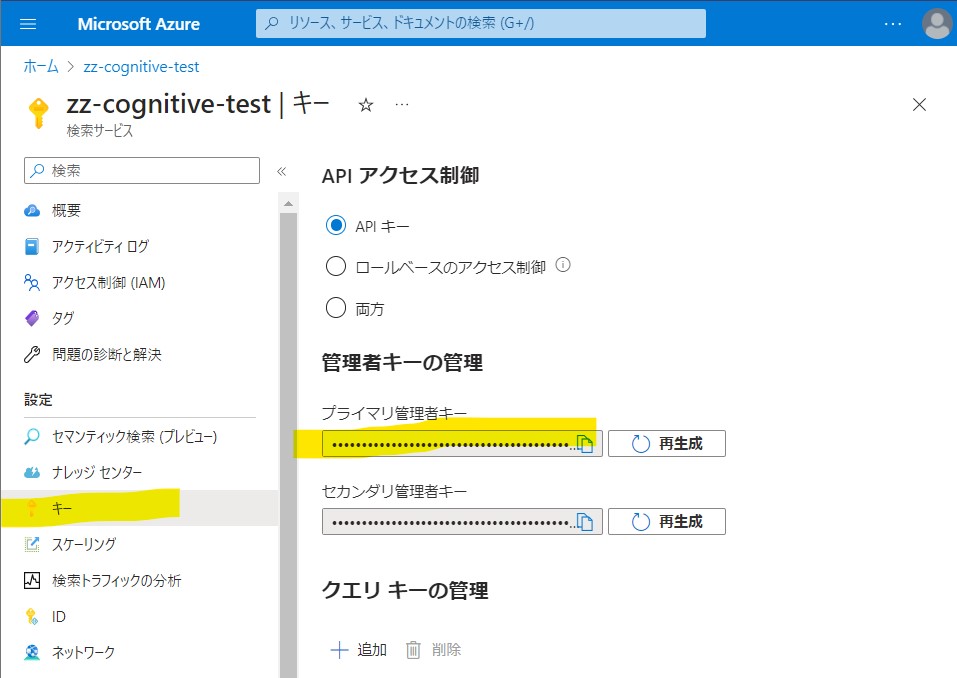
STEP2:セマンティック検索の有効化
(図211)

↓
(図212)

STEP3:サンプルプログラムの準備
特定のインデックスに対する検索クエリを実行する
(サンプルプログラム)
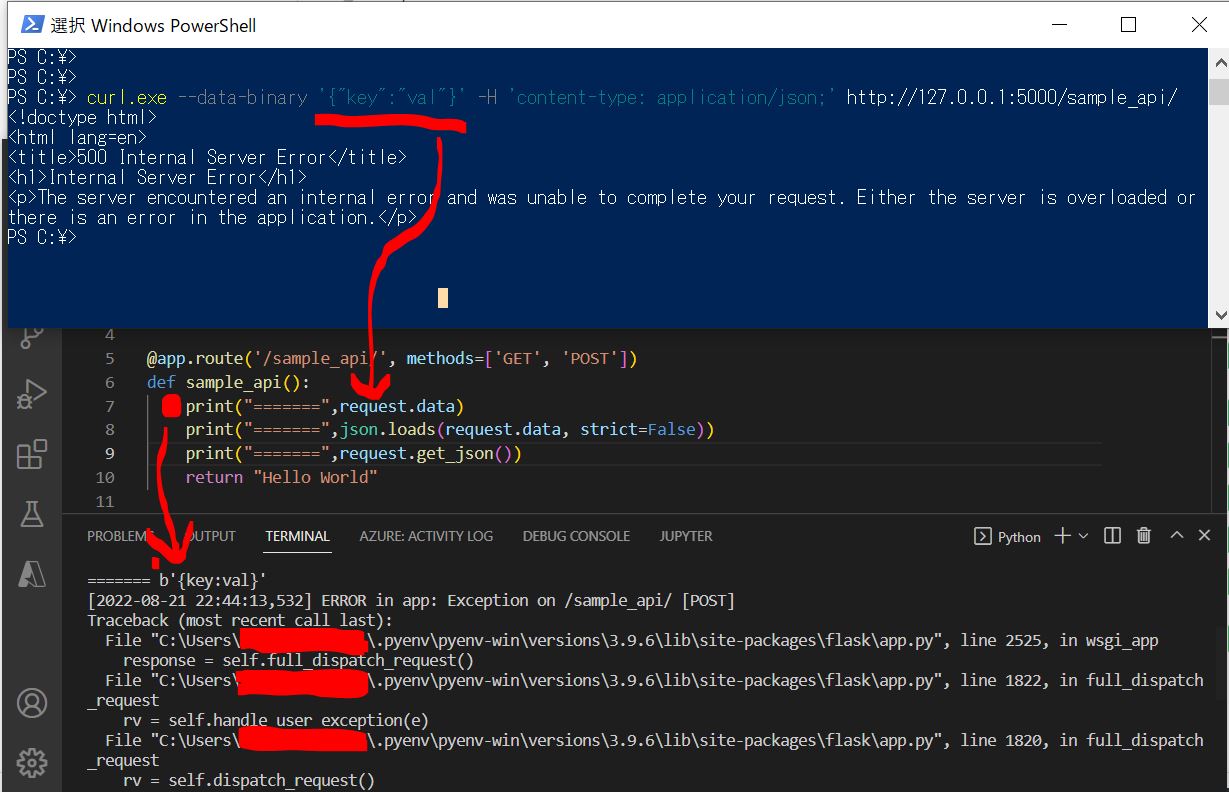
import json
import requests
import env
COG_SEARCH_URL = env.get_env_variable("COG_SEARCH_URL")
COG_SEARCH_KEY = env.get_env_variable("COG_SEARCH_KEY")
def search_data_from_azure_storage(param: str) -> dict:
"""
セマンティック機能を使用して、指定されたコンテナに格納されている情報を検索する
Args:
param (str): セマンティック検索で使用する検索パラメータ。日本語のテキストを指定することができます。
Returns:
dict: セマンティック検索結果の辞書。検索結果に関連する情報が含まれます。
"""
headers = {
"api-key": COG_SEARCH_KEY,
# "orderby": "@search.rerankerScore desc",
}
params = {
"api-version": "2021-04-30-Preview"
}
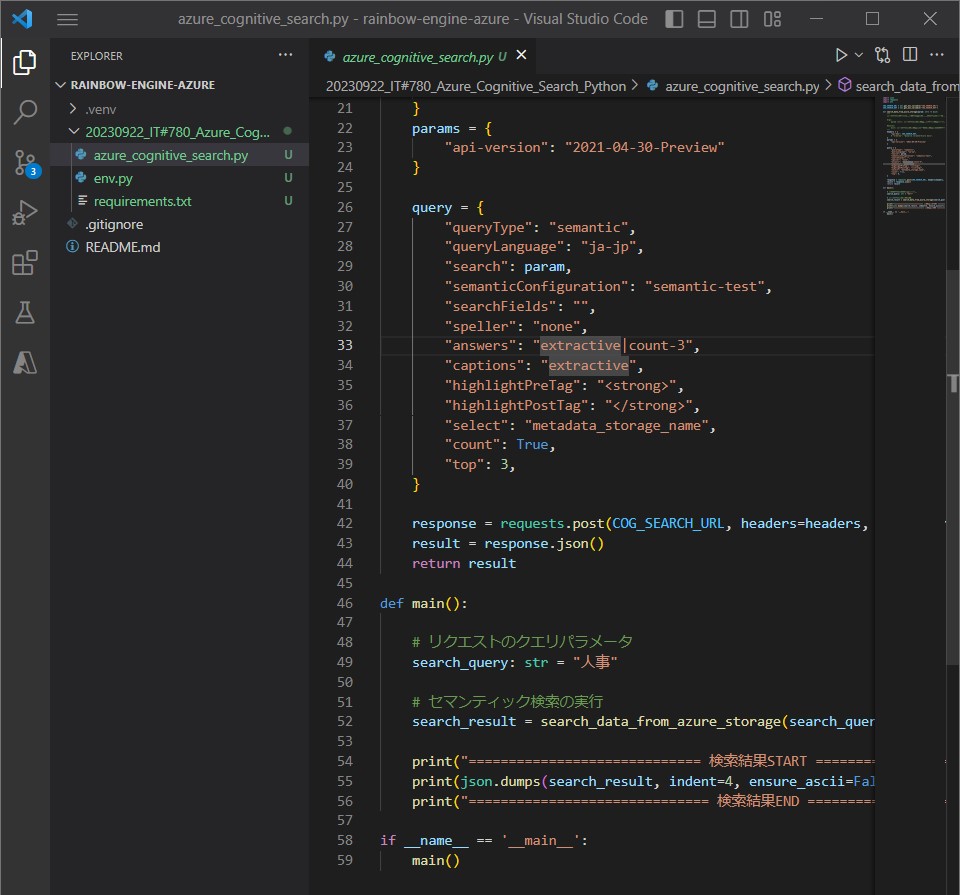
query = {
"queryType": "semantic", # クエリのタイプを指定(セマンティック検索を実行)
"queryLanguage": "ja-jp", # クエリの言語を指定(日本語で検索を行う)
"search": param, # 検索に使用するパラメータを指定(セマンティック検索のクエリテキスト)
"semanticConfiguration": "semantic-test", # 使用するセマンティック構成の名前を指定
"searchFields": "", # 検索対象のフィールドを指定するが、空の場合は全フィールドを対象とする
"speller": "none", # スペルチェックの設定を指定(noneならスペルチェックを行わない)
"answers": "extractive|count-3", # 抽出される回答(関連テキスト)の種類と数を指定
"captions": "extractive", # 抽出される回答の種類を指定(この場合は抽出のみ)
"highlightPreTag": "<strong>", # ハイライト表示のためのタグ(前側)を指定
"highlightPostTag": "</strong>", # ハイライト表示のためのタグ(後側)を指定
"select": "metadata_storage_name", # 検索結果に含めるフィールドを指定する
"count": True, # 検索結果の総数を取得するかどうかを指定(Trueなら取得する)
"top": 3, # 検索結果から上位何件を取得するかを指定する
}
response = requests.post(COG_SEARCH_URL, headers=headers, json=query, params=params)
result = response.json()
return result
def main():
# リクエストのクエリパラメータ
search_query: str = "人事"
# セマンティック検索の実行
search_result = search_data_from_azure_storage(search_query)
print("============================= 検索結果START =============================")
print(json.dumps(search_result, indent=4, ensure_ascii=False))
print("============================== 検索結果END ==============================")
if __name__ == '__main__':
main()
(図311)
STEP4:動かし方
以下記事を参照ください。
STEP4-1:実行結果(例)
(図411)実行結果

(例)
============================= 検索結果START =============================
{
"@odata.context": "https://zz-cognitive-test.search.windows.net/indexes('test-index')/$metadata#docs(*)",
"@odata.count": 3,
"@search.answers": [],
"value": [
{
"@search.score": 0.62060714,
"@search.rerankerScore": 0.9756317138671875,
"@search.captions": [
“text”: “ここに検索結果のテキストが入る",
"highlights": ""
}
],
"metadata_storage_name": "022-032.pdf"
},
{
"@search.score": 0.59651697,
"@search.rerankerScore": 0.7617244720458984,
"@search.captions": [
{
"text": "ここに検索結果のテキストが入る",
"highlights": ""
}
],
"metadata_storage_name": "142_107_114.pdf"
},
{
"@search.score": 0.3894356,
"@search.rerankerScore": 0.47032928466796875,
"@search.captions": [
{
"text": "ここに検索結果のテキストが入る",
"highlights": ""
}
],
"metadata_storage_name": "014-023.pdf"
}
]
}
============================== 検索結果END ==============================
STEP4-2:実行結果の解釈方法
(表)
| @search.score | ・検索クエリと各ドキュメントがどれほどマッチしているかを示すスコアです。 ・検索アルゴリズムによって計算され、高い値ほどクエリとのマッチ度が高い ・検索結果のランキング(並び順)に使用されます。 |
| @search.rerankerScore | ・セマンティック検索のリランカー(再ランキング機能)によって計算されるスコア ・リランカーは、元の検索スコアに基づいてドキュメントのランキングを調整します ・検索結果の再ランキングに使用されます。 |
| @search.captions | ・セマンティック検索のキャプション抽出機能によって生成される要約です。 ・キャプションは、ドキュメントの内容を短く要約したものです。 ・検索結果の表示に役立てることができます。 |