<目次>
LangChainでConflueneceの内容を読み込む方法
やりたいこと
STEP0:前提条件
STEP1:事前準備
STEP2:Conflueneceページの読み込み
エラー対応
LangChainでConflueneceの内容を読み込む方法
やりたいこと
・LangChainライブラリを使って、Confluenceの記事を読込みたい
→指定したスペースのConfluence記事に対して、コンテンツ(page_content)とメタデータ(metadata)を取得する。これをページごとにlistに格納して返却する。
STEP0:前提条件
・Windows OSで試す
STEP1:事前準備
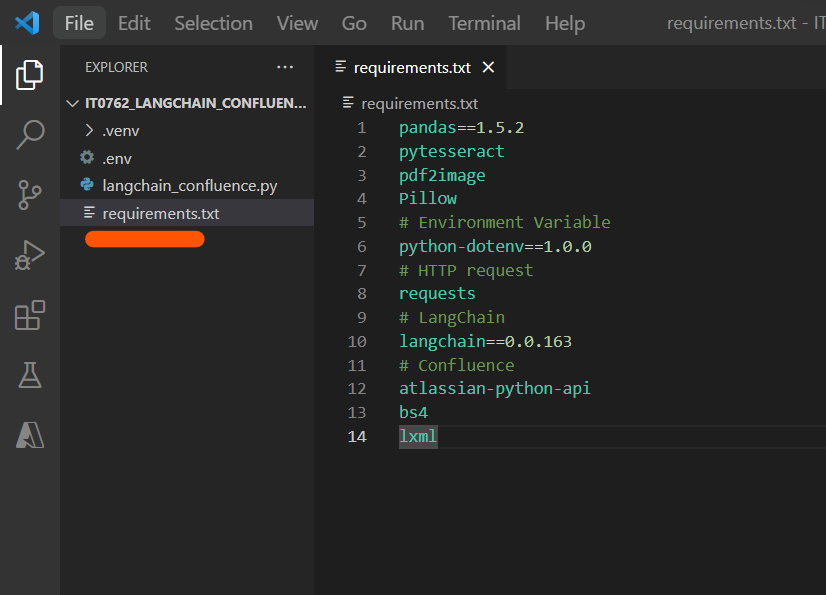
・①requrements.txt
作業フォルダの配下に「requrements.txt」を作成します。
pandas==1.5.2 # Environment Variable python-dotenv==1.0.0 # HTTP request requests # LangChain langchain==0.0.163 # Confluence atlassian-python-api bs4 pytesseract pdf2image Pillow lxml
(図111)
・②パッケージのインストール
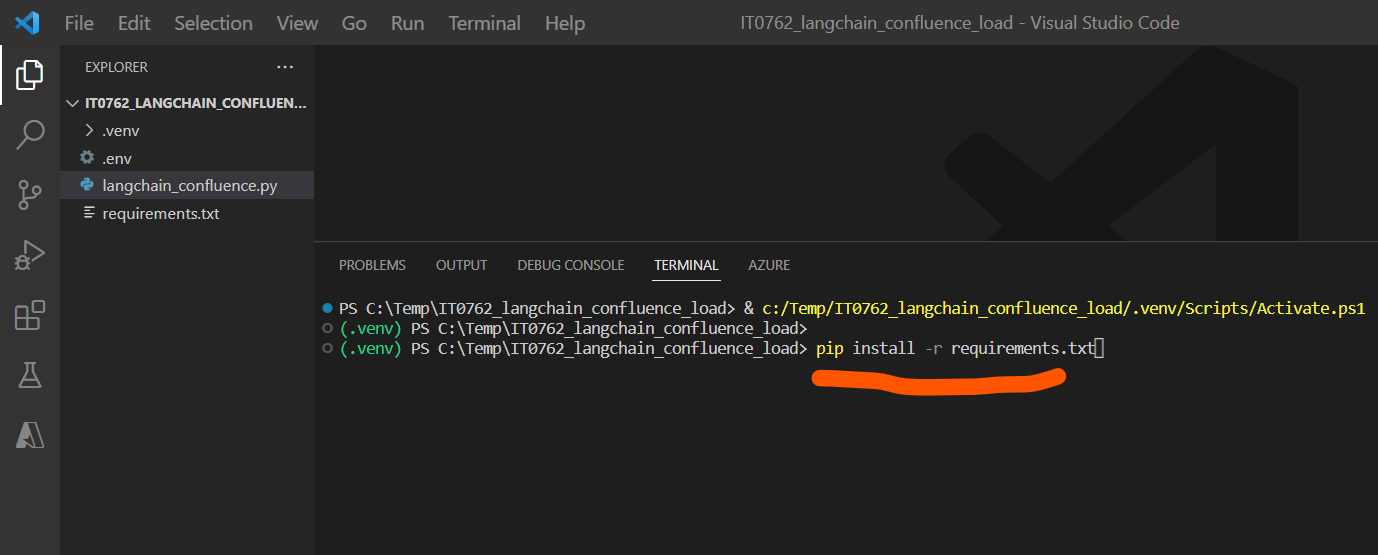
ターミナルを開き、先ほど作成した「requrements.txt」に記載したパッケージをインストールするコマンドを実行します。
> pip install -r requirements.txt
STEP2:Conflueneceページの読み込み
STEP2-1:サンプルプログラムの用意
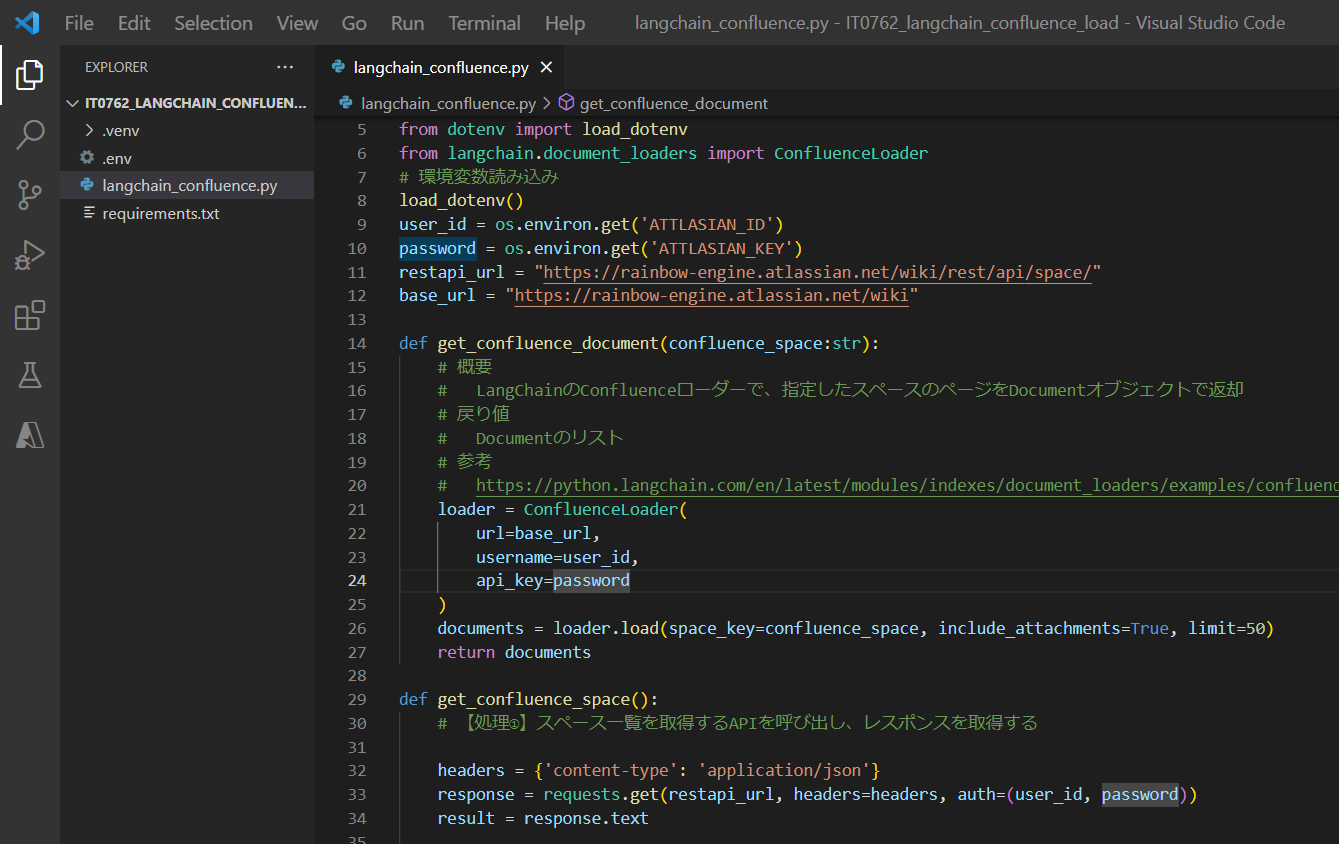
(サンプルプログラム)langchain_confluence.py
import requests
import pandas as pd
import json
import os
from dotenv import load_dotenv
from langchain.document_loaders import ConfluenceLoader
# 環境変数読み込み
load_dotenv()
user_id = os.environ.get('ATTLASIAN_ID')
password = os.environ.get('ATTLASIAN_KEY')
restapi_url = "https://rainbow-engine.atlassian.net/wiki/rest/api/space/"
base_url = "https://rainbow-engine.atlassian.net/wiki"
def get_confluence_document(confluence_space:str):
# 概要
# LangChainのConfluenceローダーで、指定したスペースのページをDocumentオブジェクトで返却
# 戻り値
# Documentのリスト
# 参考
# https://python.langchain.com/en/latest/modules/indexes/document_loaders/examples/confluence.html
loader = ConfluenceLoader(
url=base_url,
username=user_id,
api_key=password
)
documents = loader.load(space_key=confluence_space, include_attachments=True, limit=50)
return documents
def get_confluence_space():
# 【処理①】スペース一覧を取得するAPIを呼び出し、レスポンスを取得する
headers = {'content-type': 'application/json'}
response = requests.get(restapi_url, headers=headers, auth=(user_id, password))
result = response.text
# 【処理②】レスポンスのJSONを表形式データ(DataFrame)に変形する
json_object = json.loads(result)
df = pd.json_normalize(json_object, record_path =['results'])
# 【処理③】表形式データ(DataFrame)をtxt出力する
df['key'].to_csv('./space_list.txt', sep=',', encoding='utf-8', header=False, index=False)
# 【処理④】txt出力した内容を読み込み、listで返却
target = None
with open("space_list.txt", mode="r", encoding="utf-8") as f:
target = f.read().splitlines()
return target
def main():
confluence_spaces = get_confluence_space()
for space in confluence_spaces:
documents = get_confluence_document(space)
print(documents)
if __name__ == "__main__":
main()
(図211)
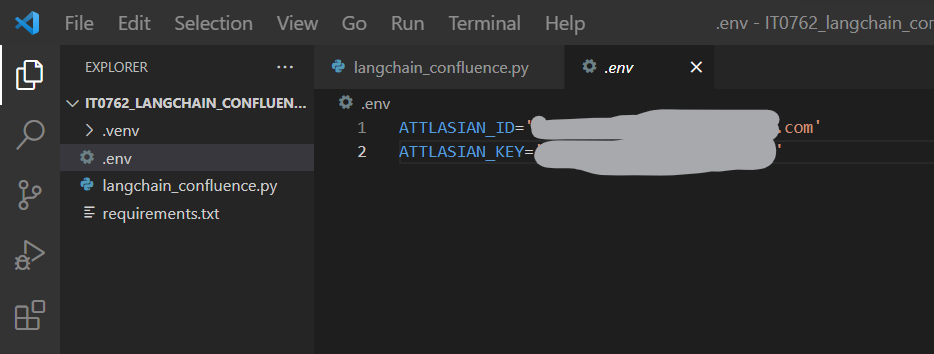
(サンプルプログラム).env
・ATTLASIAN_IDはConfluenceのログインID
・ATTLASIAN_KEYはConfluenceのAPIキーをセット
ATTLASIAN_ID='xxxxx.com' ATTLASIAN_KEY='xxxx'
(図212)
STEP2-2:サンプルプログラムの実行
(図213①)
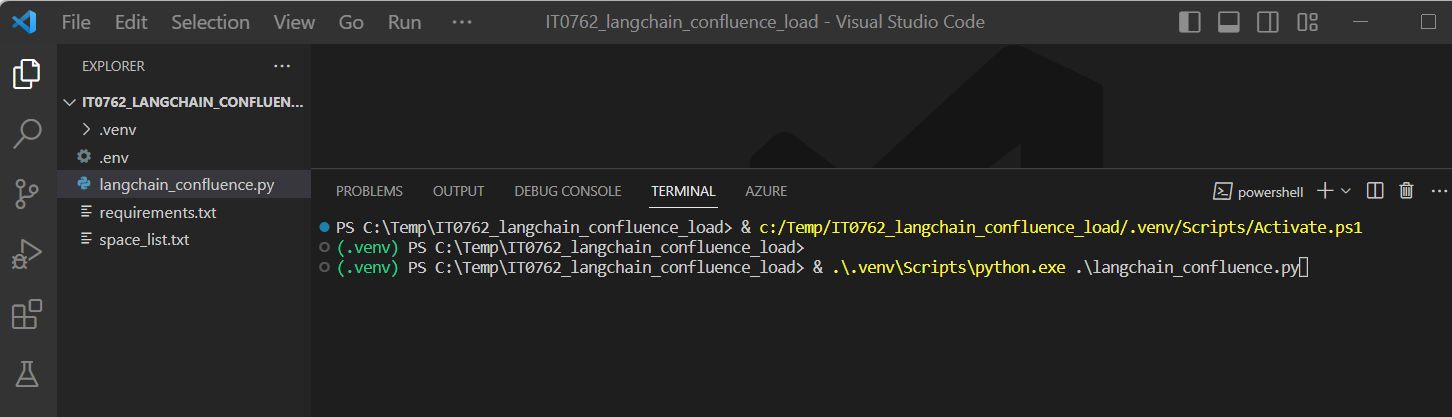
↓
(図213②)
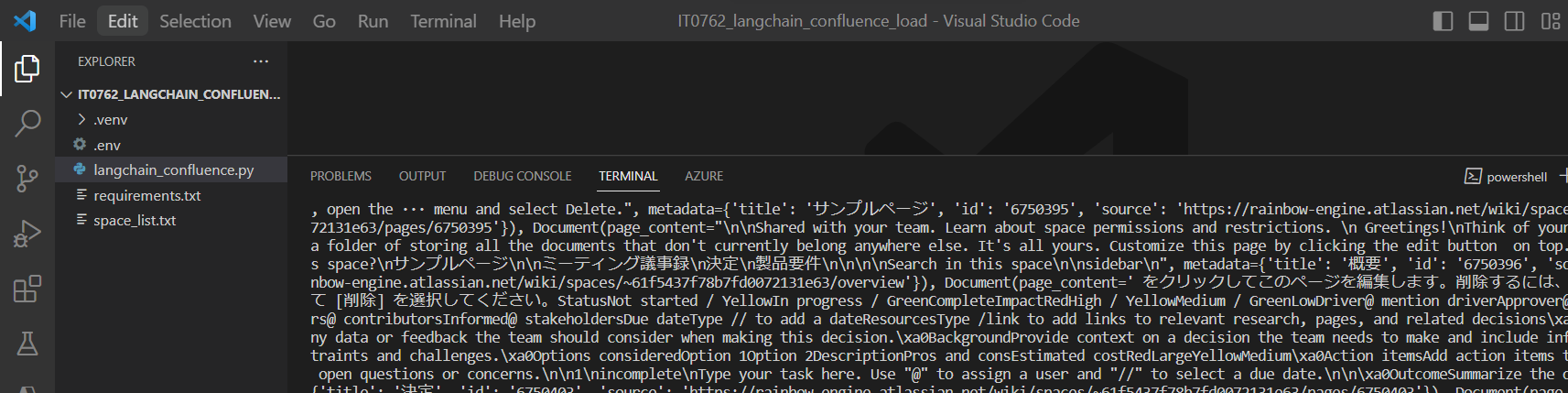
↓
(図213②)
(実行結果例)
→Confluence記事に対して、コンテンツ(page_content)とメタデータ(metadata)を取得する。これをページごとにlistに格納して返却する。
[
Document(
page_content="xxxx",
metadata={'title': '[記事タイトル]', 'id': '[記事ID]', 'source': '[記事URL]'}
),
~中略(以降、繰り返し)~
]
エラー対応
備忘メモ。
事象
プログラムの実行時に以下のエラーが出た。
(エラーメッセージ)
bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: lxml. Do you need to install a parser library?
(図411)
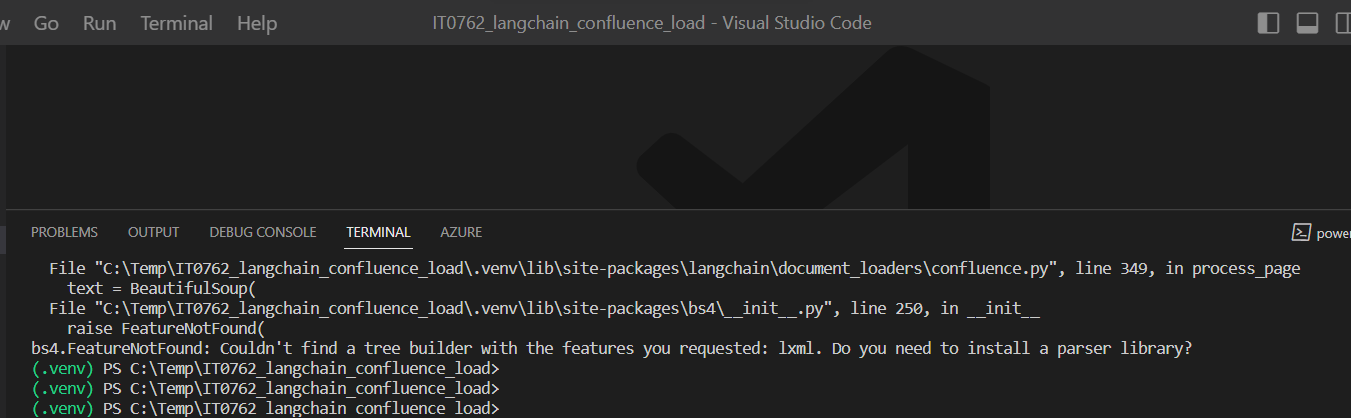
原因
lxmlパッケージがインストールされていないため。
対処
requirements.txtにlxmlも追加する