Linuxのテキスト入力等で日本語が文字化けした時の対処方法を紹介します。
(0)目次&概説
(1) 障害・不具合の概要
(2) 文字化けの対処法
(3) 解説(文字コードについて)
(1) 障害・不具合の概要
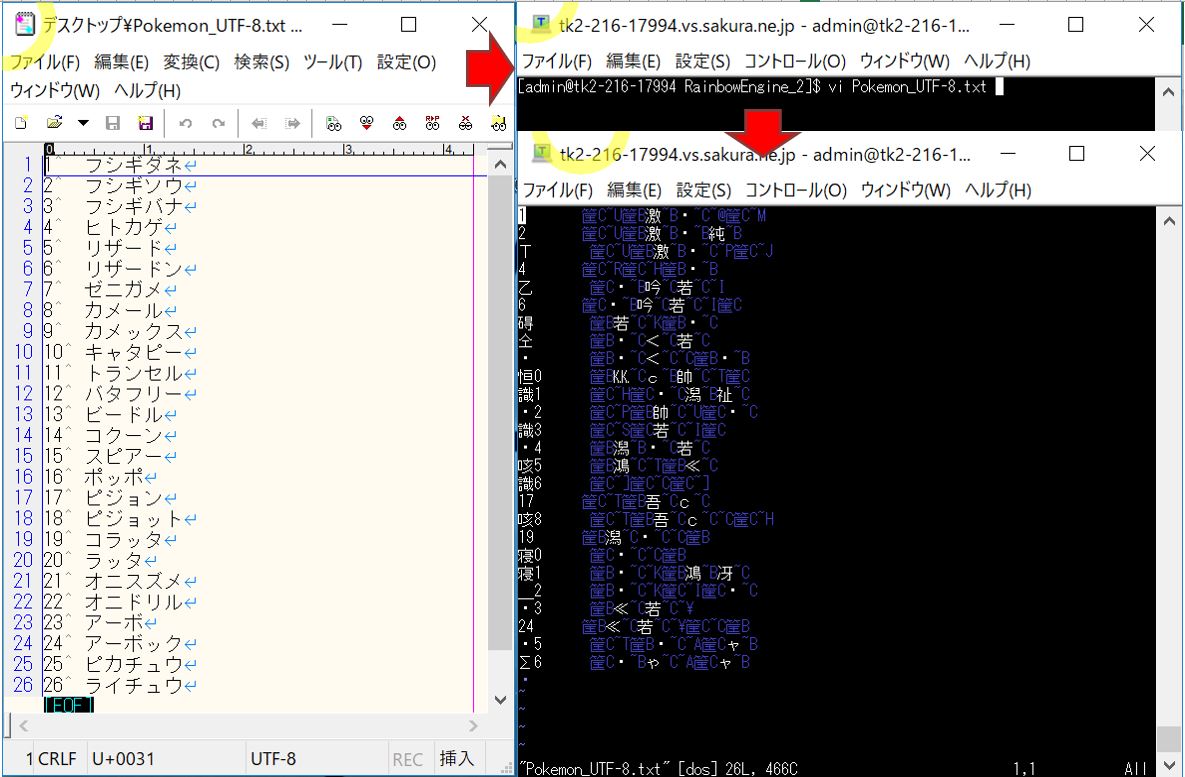
Linuxのviエディタで日本語のテキストを表示した際、下図のように文字化けが発生しています。今回はエンコード方法の一つである「UTF-8」の例を示します。
>目次にもどる
(2) 文字化けの対処法
解決策として以下のロケール設定ファイルの修正手順を実施します。「ロケール」とは各国や言語の地域情報の事です。ロケールファイルの中で使用するエンコード方式(「Shift_JIS」「UTF-8」「EUC-JP」など)を設定することができます。
(2-1) viエディタでロケールファイルの編集
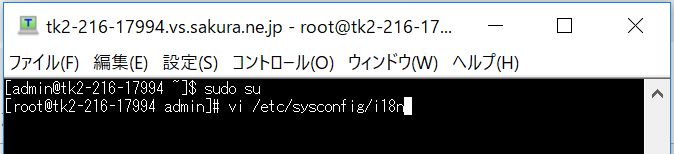
サーバにTeraTermでログインし、rootにスイッチします(編集したいファイルの権限の関係で)。次に下記コマンドでロケールファイルをviエディタで開きます。
/* ①viエディタでロケールファイルを編集 */ vi /etc/sysconfig/i18n
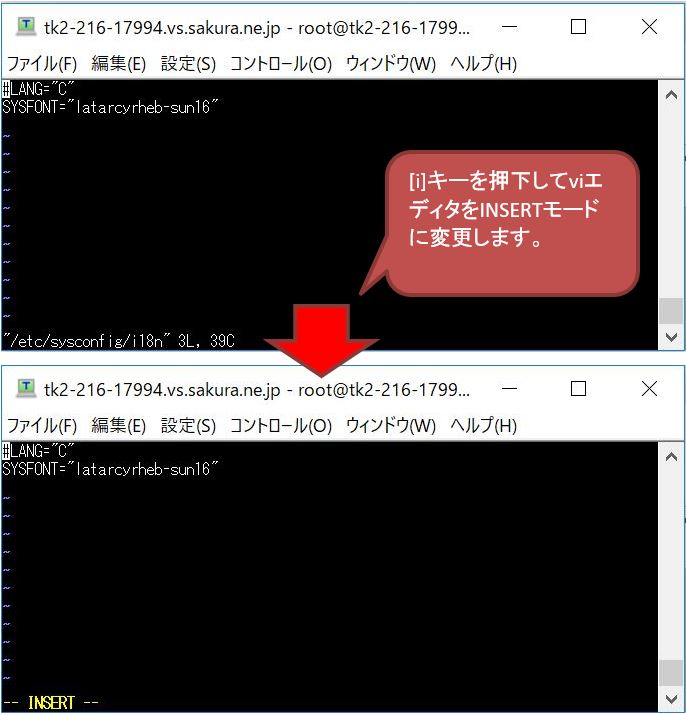
(2-2) INSERTモードに変更
[i]キーを押下してviエディタをINSERTモードに変更します。画面下部に黄色い文字で「– INSERT –」と出たら変更完了です。
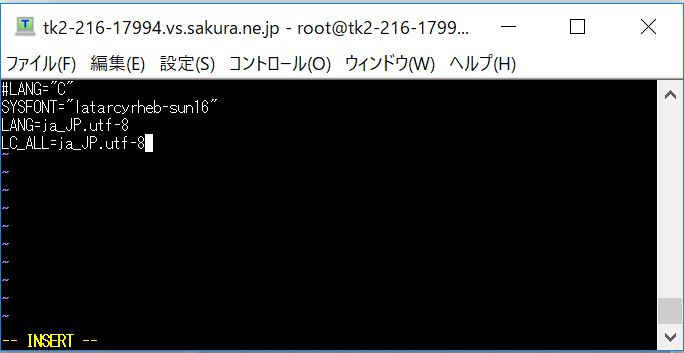
(2-3) 指定文言の追加
下記の文言を追加します。もし変数「LANG」や「LC_ALL」が既に存在する場合は値のみを指定値に書き換えます。
/* ③下記の文言を追加(変数が既にある場合は値のみ更新)*/ LANG=ja_JP.utf-8 LC_ALL=ja_JP.utf-8
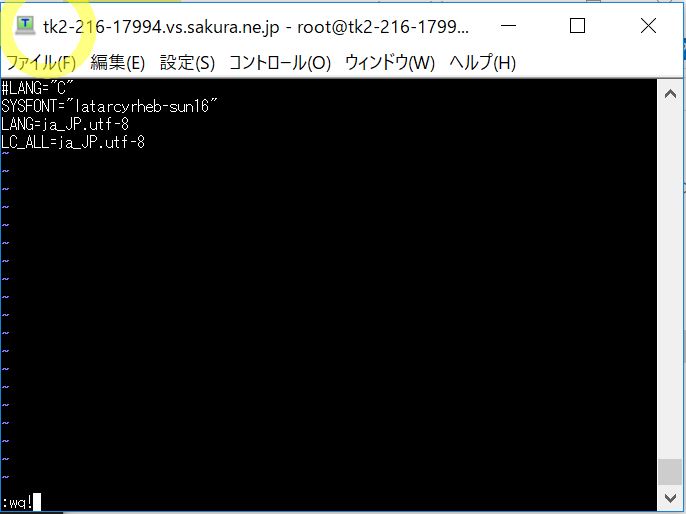
(2-4) viエディタでロケールファイルを保存
編集内容を保存します。保存する時は一旦「Esc」キーで「編集モード」から「コマンドモード」に戻します。そして「保存して終了」のコマンドである「:wq」で保存と終了をします(画像では更に「!」を付けて強制的に操作をしています)。
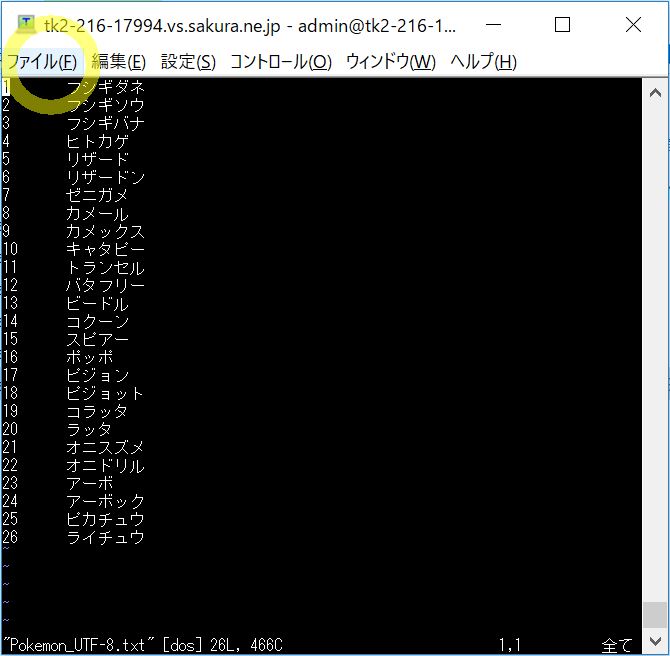
(2-5) TeraTermを再起動して反映確認
TeraTermを再起動して反映確認します。うまく行けばテキストファイルの文字化けは下図の様に解消しているはずです。
>目次にもどる
(3) 解説(文字コードについて)
普段使っている「文字コード」という言葉は、正確には①「符号化文字集合」と②「文字符号化方式」という概念に分解できます。
①「符号化文字集合」は文字集合の各文字に対して1対1に対応する「ビット組み合わせ」を割り当てた「文字の集合体」の事です。代表的な例としては「Unicode」や「JIS X 0208」や「JIS X 0201」などがあります。
②「文字符号化方式」は上記の文字に割り当てられたビット組み合わせを、運用に即した別のビット組み合わせに変換するための変換運用ルールの事です。1つの「符号化文字集合」を扱うならば問題ありませんが、複数の「符号化文字集合」を組み合わせて利用する場合や、「JIS X 0208」の様に文字とビット組み合わせを直接定義していない符号化文字集合を扱う場合などは、こうした変換ルールが必要となってきます。代表的な例としては「UTF-8」「Shift_JIS」「EUC-JP」「ISO-2022-JP(電子メール)」などがあります。
表でまとめると、およそ下記の様になります。
| 文字符号化方式 (変換ルール) |
変換対象の 符号化文字集合 (文字集合) |
備考 |
| UTF-8 | ASCII Unicode |
・現代では最も主流 ・Unicodeは世界各国の文字を扱える(多言語対応) ・最初の128文字を変換した結果がASCIIと完全一致する |
| Shift_JIS | ASCII JIS X 0208 JIS X 0201 |
・日本語Windows等で使用されている →メモ帳のデフォルト →厳密にはShift_JISを拡張したMS932を使用 |
| EUC-JP | ASCII JIS X 0208 JIS X 0201 JIS X 0212 |
・日本語UNIX等で使用されている →近年はUTF-8も使われる |
>目次にもどる
以上です。