<目次>
(1) PDFをテキスト化する方法(Azure Cognitive Service)
やりたいこと
概要
STEP0:前提条件
STEP1:Azureのリソース作成
STEP2:必要なパッケージのインストール
STEP3:サンプルプログラムの実行
(1) PDFをテキスト化する方法(Azure Cognitive Service)
やりたいこと
・PDFファイルをテキスト化する
概要
・Azure Form Recognizerを使用してPDFからテキストを抽出
STEP0:前提条件
(前提)
STEP1:Azureのリソース作成
Cognitive Services または Form Recognizer リソースを作成する必要あり(以下の例はCognitive Service)
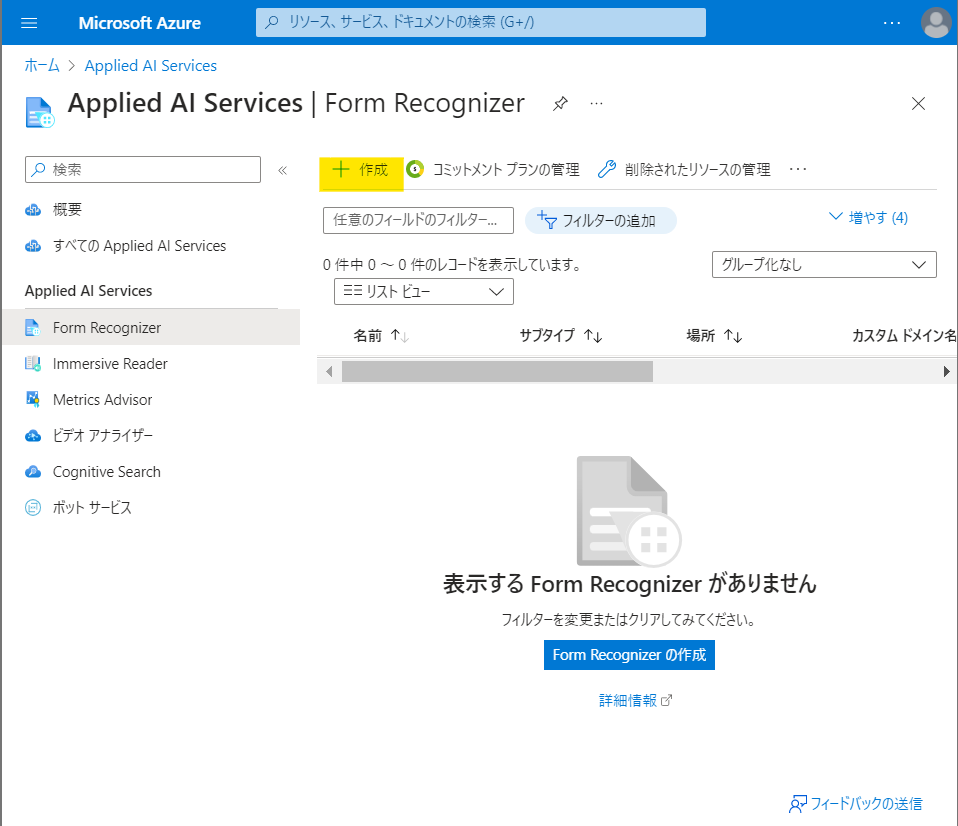
・①「Form Recognizer」を「+作成」
(図110)
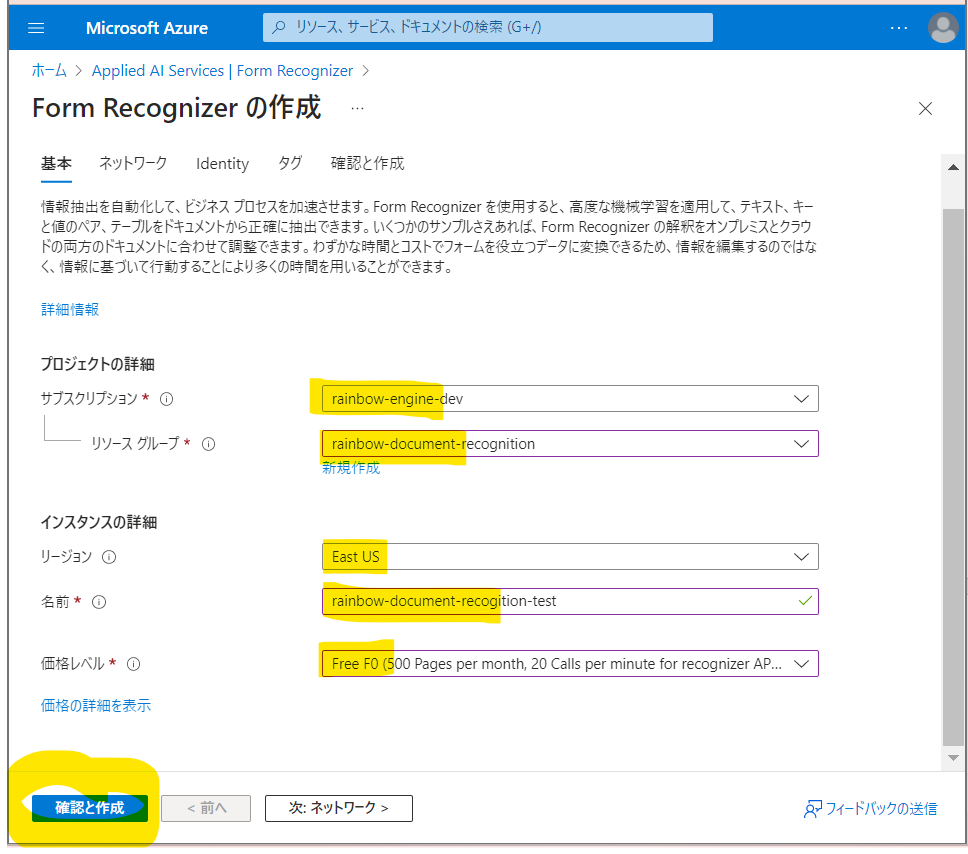
・②必要情報を入力して「確認と作成」→「作成」
(図111)
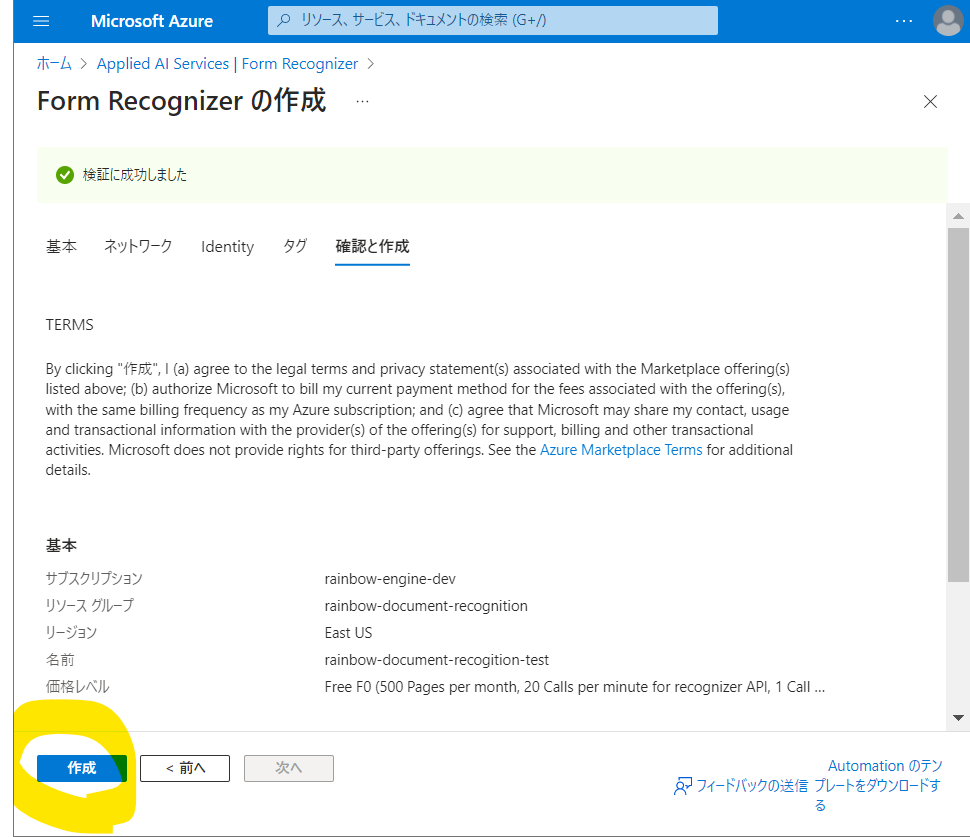
↓
(図112)
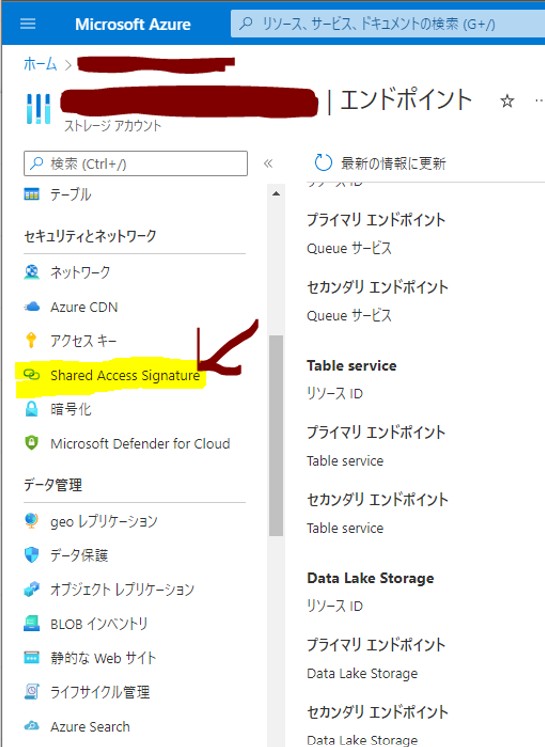
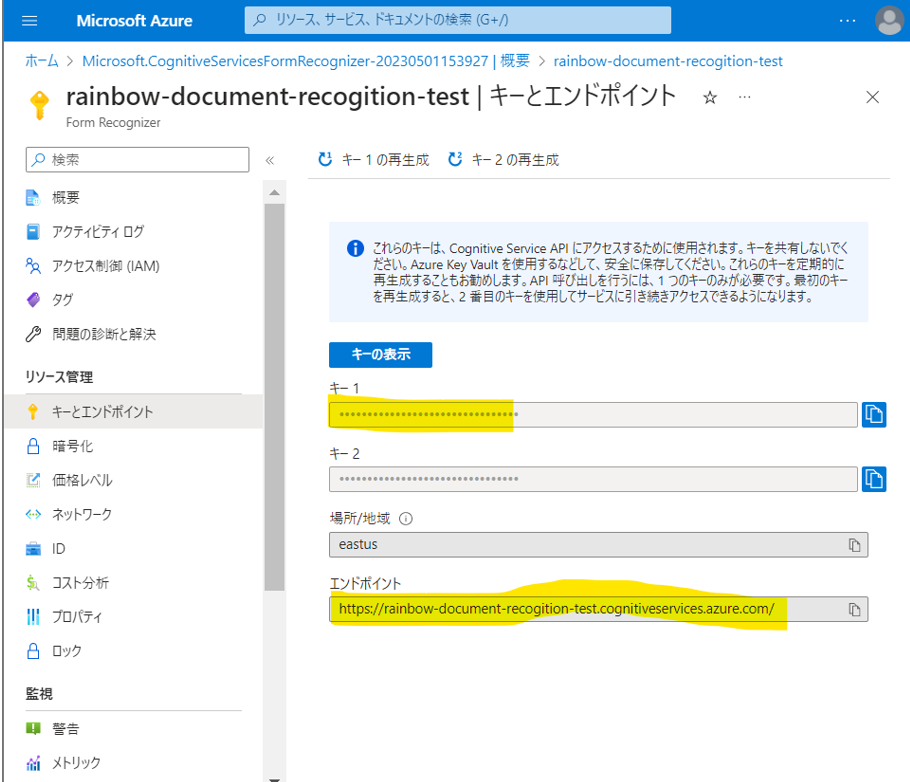
・③「キー」と「エンドポイント」を控える
(図113)
STEP2:必要なパッケージのインストール
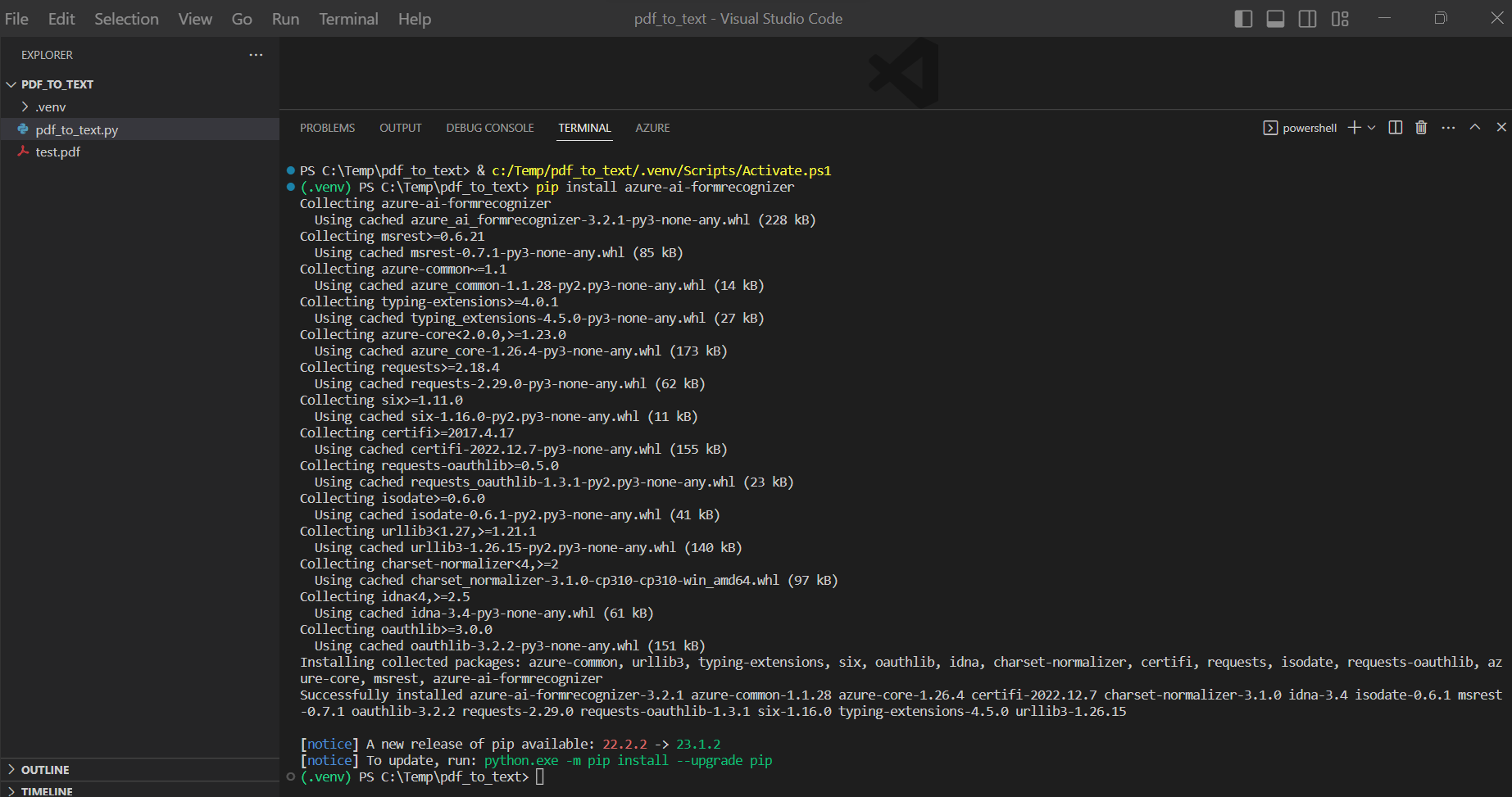
・①Visual Studio Codeのターミナルから、以下のコマンドを実行してパッケージをインストール。
> pip install azure-ai-formrecognizer > pip install azure-core
(図211)
(図212)
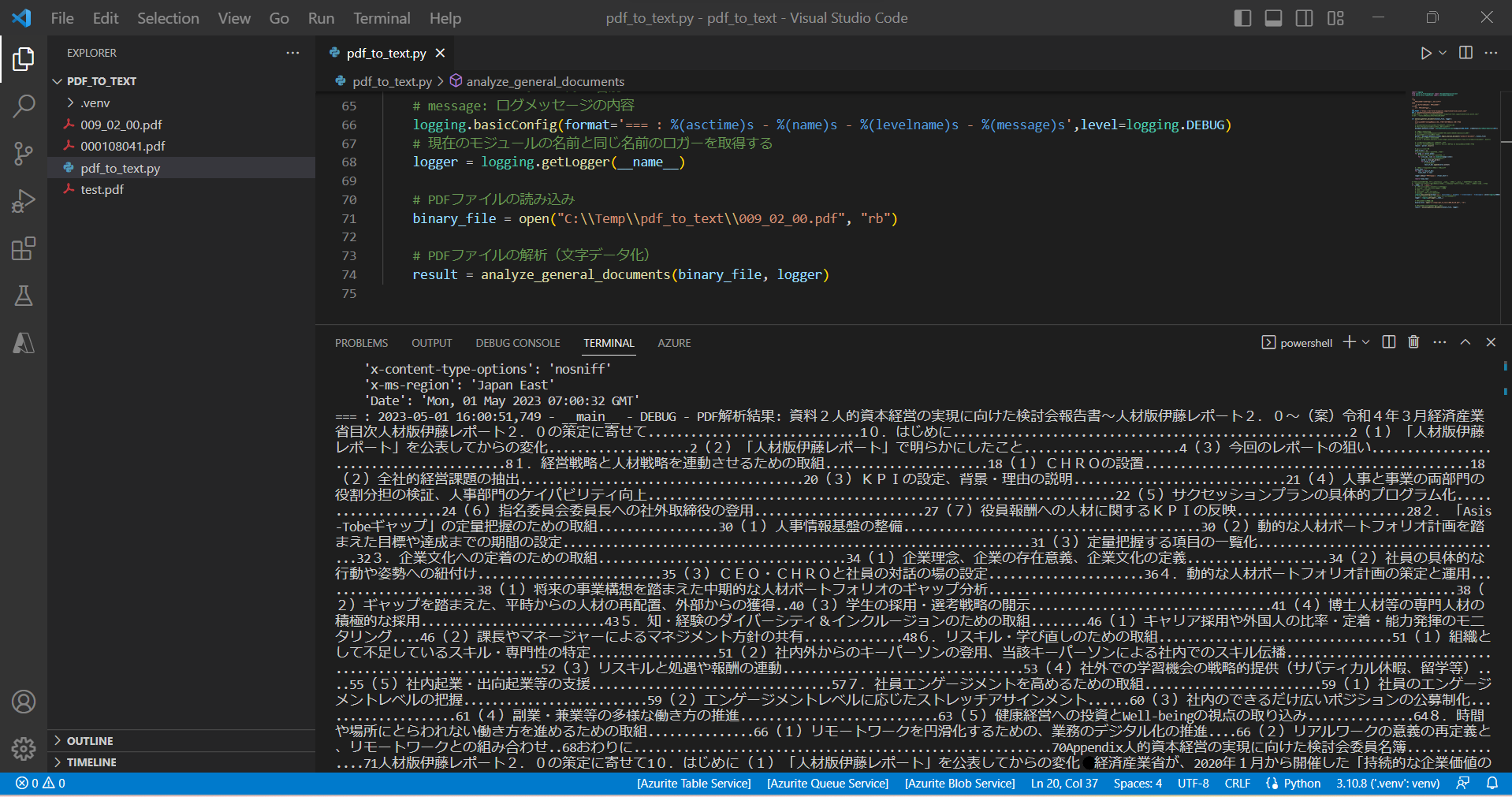
STEP3:サンプルプログラムの実行
(サンプルプログラム)
import logging
from azure.ai.formrecognizer import DocumentAnalysisClient
from azure.core.credentials import AzureKeyCredential
"""
概要
PDFファイルを文字データに変換する
引数
_io.BufferedReader: PDFファイル
戻り値
str: PDFの文字データ
"""
END_POINT = "https://xxxxxxxxxxxx.cognitiveservices.azure.com/"
KEY = "xxxxxxxxxxxxxxxxxxxxxxxxxx"
def analyze_general_documents(binary_file, logger):
"""
binaryファイルを解析し、記載されている文字列を抽出します。
"""
# DocumentAnalysisClientクラスのインスタンスを作成
# →Form Recognizerのサービスを使える様にする
document_analysis_client = DocumentAnalysisClient(endpoint=END_POINT, credential=AzureKeyCredential(KEY))
# ドキュメントの解析
# →ドキュメントの取得方法は「ファイルから」と「URLから」の2通りがある
# (1)ファイル形式のドキュメント
poller = document_analysis_client.begin_analyze_document("prebuilt-document", binary_file)
# (2)URLからドキュメントを取得
# poller = document_analysis_client.begin_analyze_document_from_url("prebuilt-document", docUrl)
# 戻り値:AsyncLROPoller のインスタンス
# →poller オブジェクトで result() を呼び出して、 を AnalyzeResult返します。
result = poller.result()
# 結果格納用の配列
text_of_doc = []
# 結果は「ページ単位」に分かれている
for page in result.pages:
# 更にその中で「行単位」に分かれる
for line_idx, line in enumerate(page.lines):
# 行単位に「単語」の情報を抽出
words = line.get_words()
for word in words:
# リストに追加
text_of_doc.append(word.content)
# 配列の中身を、1つの変数に格納しなおす
final_text = ""
for text in text_of_doc:
final_text += text
logger.debug(f"PDF解析結果: {final_text}")
return final_text
# スクリプトとして実行する際、Pythonは __name__ 変数に "__main__" という値を設定します。
# 一方で、他のモジュールからインポートされた場合は、モジュール名が __name__ 変数に設定されます。
if __name__ == "__main__":
# ログメッセージの出力フォーマットを指定
# asctime: ログレコードが作成された日時
# name: ロガーの名前
# levelname: ログレベルの名前
# message: ログメッセージの内容
logging.basicConfig(format='=== : %(asctime)s - %(name)s - %(levelname)s - %(message)s',level=logging.DEBUG)
# 現在のモジュールの名前と同じ名前のロガーを取得する
logger = logging.getLogger(__name__)
# PDFファイルの読み込み
binary_file = open("[ファイルパス].pdf", "rb")
# PDFファイルの解析(文字データ化)
result = analyze_general_documents(binary_file, logger)
・テストデータイメージ(※冒頭の2ページのみ)
(図312)
・実行結果
(図313)
(図311)ドキュメントの取得方法は「ファイルから」と「URLから」の2通りある

(参考)