<目次>
(1) Pythonでcsvを読み込んでデータベース化する方法
(1-1) 構文(to_sql)
(1-2) 構文(to_sql)の引数
(1-3) サンプルプログラム
(1) Pythonでcsvを読み込んでデータベース化する方法
(1-1) 構文(to_sql)
(構文)
import pandas as pd
df = pd.read_csv('[csvのパス]',encoding = 'utf-8')
df.to_sql(con=[create_engineの結果],name='[テーブル名]',schema='[スキーマ名]')
①1行目でpandasライブラリを「pd」という名前(任意)でインポートしています。
②2行目でpandasのread_csvメソッドでcsvを読み込みます(⇒read_csvの詳細はコチラでご紹介)
③3行目でto_sqlでread_csvの結果を指定したテーブルにINSERTします。引数については次の節でご紹介します。
(1-2) 構文(to_sql)の引数
構文で出たto_sqlの引数についてご紹介します。
(表)to_sql引数
| オプション | 説明 |
| con=[エンジン] | sqlalchemyパッケージ(PythonのObject Relational Mapper)のcreate_engineファンクションの実行結果(エンジン)を指定します。エンジンはDB接続の起点となるオブジェクトです。 |
| name=[テーブル名] | INSERTを行う対象のテーブルを文字列か変数で指定します。 |
| schema=[スキーマ名] | INSERTを行う対象のスキーマを文字列か変数で指定します。 |
| index=[True/False] | データフレームが保持するインデックス情報を、INSERT時に1つのカラムとして追加するかどうか。指定なしの場合は「True」の扱いになります。 |
| if_exists=[‘fail’/’replace’/’append’] | もしテーブルが存在した場合の対応を記載します。 ‘fail’⇒エラーを挙げる ‘replace’⇒既存テーブルをDROPして、新規に作成 ‘append’⇒新しい値(差分)のみをINSERT |
| dtype=[dictionaryまたはスカラー] | カラムのデータ型を指定します。引数はdictionary(キーと値のセットを持つ配列の一種)またはスカラーで指定します(スカラー指定の場合は全カラムに適用) |
(1-3) サンプルプログラム
(サンプルプログラム)
import os
import cx_Oracle
import pandas as pd
def main():
##### (1)csvの読み込み
# 第一引数=csvファイルのパス
# 第二引数=encoding=エンコーディング方式
url = r'C:\Users\Rainbow\Desktop\RP-IT0183_Test\match_stats_2017_unindexed_csv_mini.csv'
df = pd.read_csv(url,encoding = 'utf-8')
##### (2)DB接続のためのエンジン生成
# 引数 max_identifier_length : テーブルの名前の限界値を指定。
# (バージョン12.1以下のDBだと30が限界なので30で指定)
from sqlalchemy import create_engine
engine = create_engine('oracle://[SchemaName]:[Password]@[Host/IPaddress]:[port]/[SID]',encoding='utf-8',max_identifier_length=30)
##### (3)DBへのINSERT準備
# テーブル名を定義
tbl_name='match_stats_2017'
#カラム名も略語に置き換え
df.columns = [col.replace('winner','win') for col in df.columns]
df.columns = [col.replace('loser','lose') for col in df.columns]
df.columns = [col.replace('serves','sv') for col in df.columns]
##### (4)DBへのINSERT処理
# 引数con : engineを指定します
# 引数name : テーブル名を指定します
# 引数schema : スキーマ名を指定します
df.to_sql(con=engine,name=tbl_name,schema='TENNISDBUSR2')
if __name__ == '__main__':
main()
(サンプルプログラム実行イメージ)
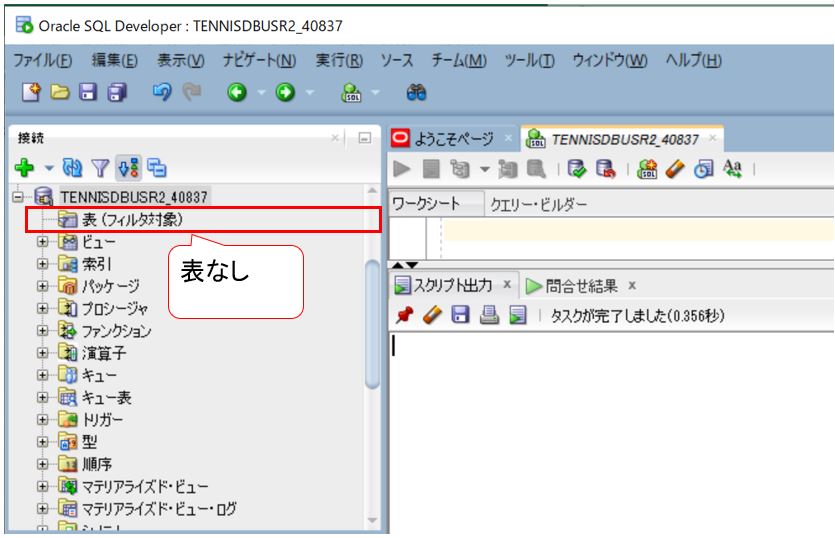
①DBの初期状態チェック
現在はスキーマに対してテーブルが存在しない状態です(Before)。
(図131)
↓
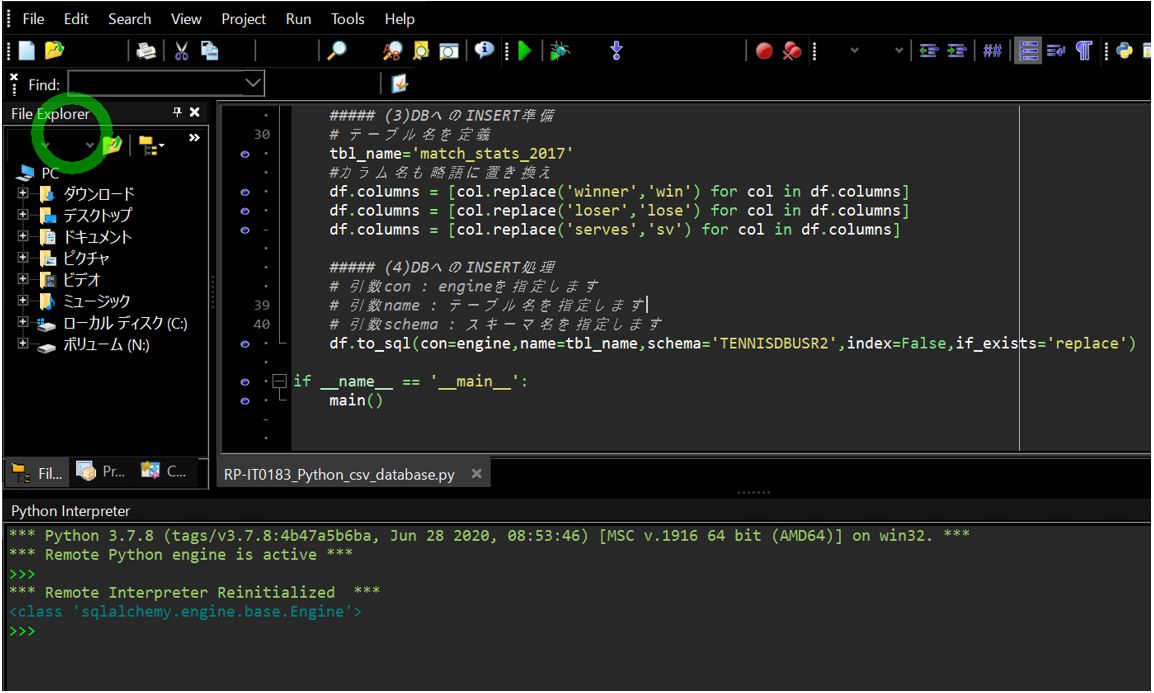
②Pythonプログラムの実行
上記のPythonのサンプルプログラムを実行します。正常に完了すればテーブルが生成されます。
(図132)
↓
③DBの状態チェック
プログラム実行完了後のDBを見ると、Pythonで作成した「match_stats_2017」というテーブルが作成されている事が確認できます。またSELECTするとレコードも挿入されている事が確認できます。
(操作動画)
上記の流れを操作した動画もご紹介します。
①DB初期状態チェック
②INSERT予定のcsvファイルのチェック
③Pythonプログラムの実行
④DBの状態チェック
(動画)