(1) PythonでPandasライブラリを用いてcsvファイルを読み込む方法
(1-1) 構文
(1-2) サンプルプログラム
(1-3) read_csvの主要なオプションご紹介
(1-4) 読み込んだcsvのカラム名やレコードを取得する方法
(1) PythonでPandasライブラリを用いてcsvファイルを読み込む方法
(1-1) 構文
1行目でpandasのライブラリをインポートし、2行目の「pd.read_csv()」でcsvを読み込んでいます。
read_csvの第一引数は読み込むcsvのパス([FilePath])を指定します。第二引数以降はオプションの指定をカンマ区切りで行います。
import pandas as pd df = pd.read_csv([FilePath],[Option1],[Option2],[Option3],...)
(1-2) サンプルプログラム
実際に上記の構文を用いたサンプルプログラムをご紹介します。
(読み込むcsv)
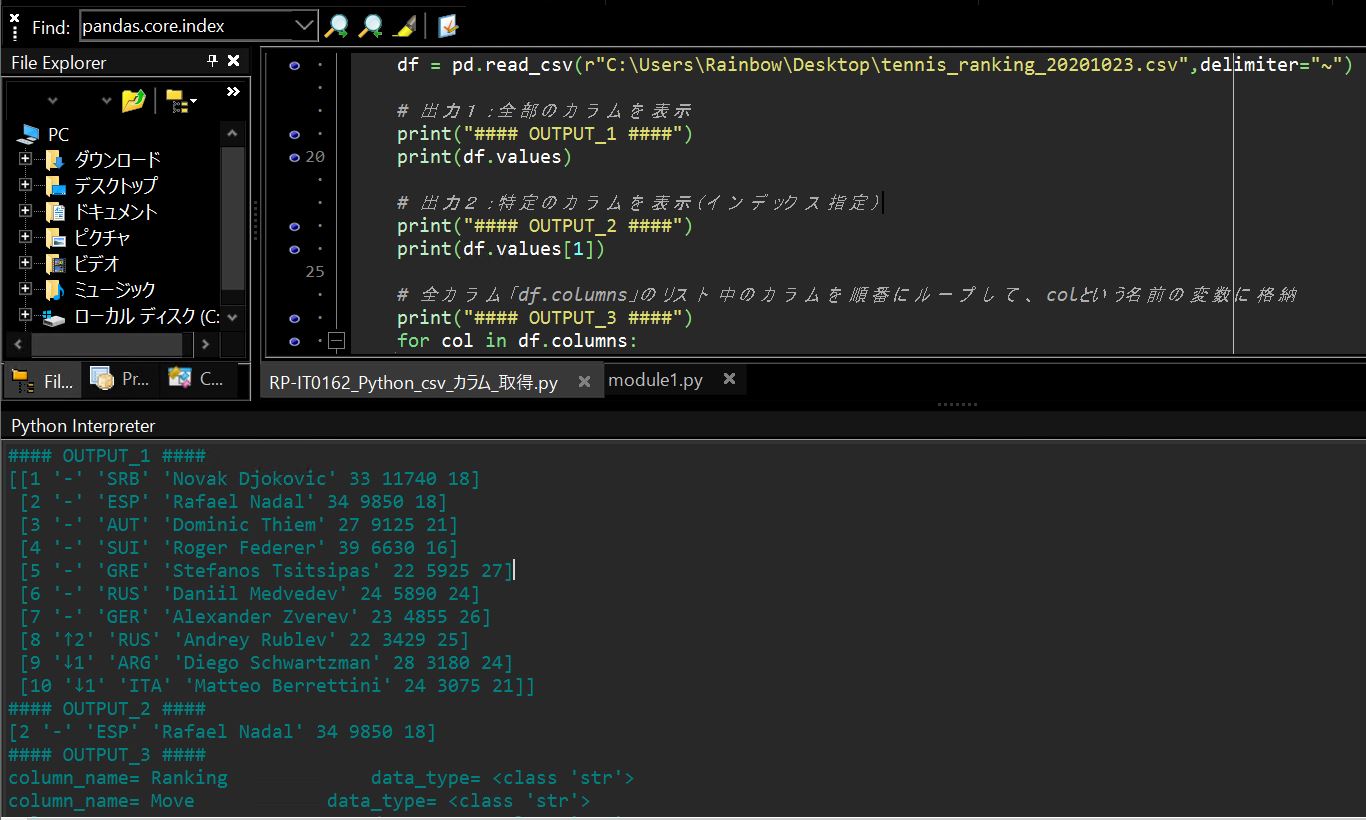
↓このデータは2020年10月23時点での男子テニスシングルスの世界ランキングTop10位までの情報です。今回のデータは読み込み対象のデータがチルダ「~」を区切り文字にしています。
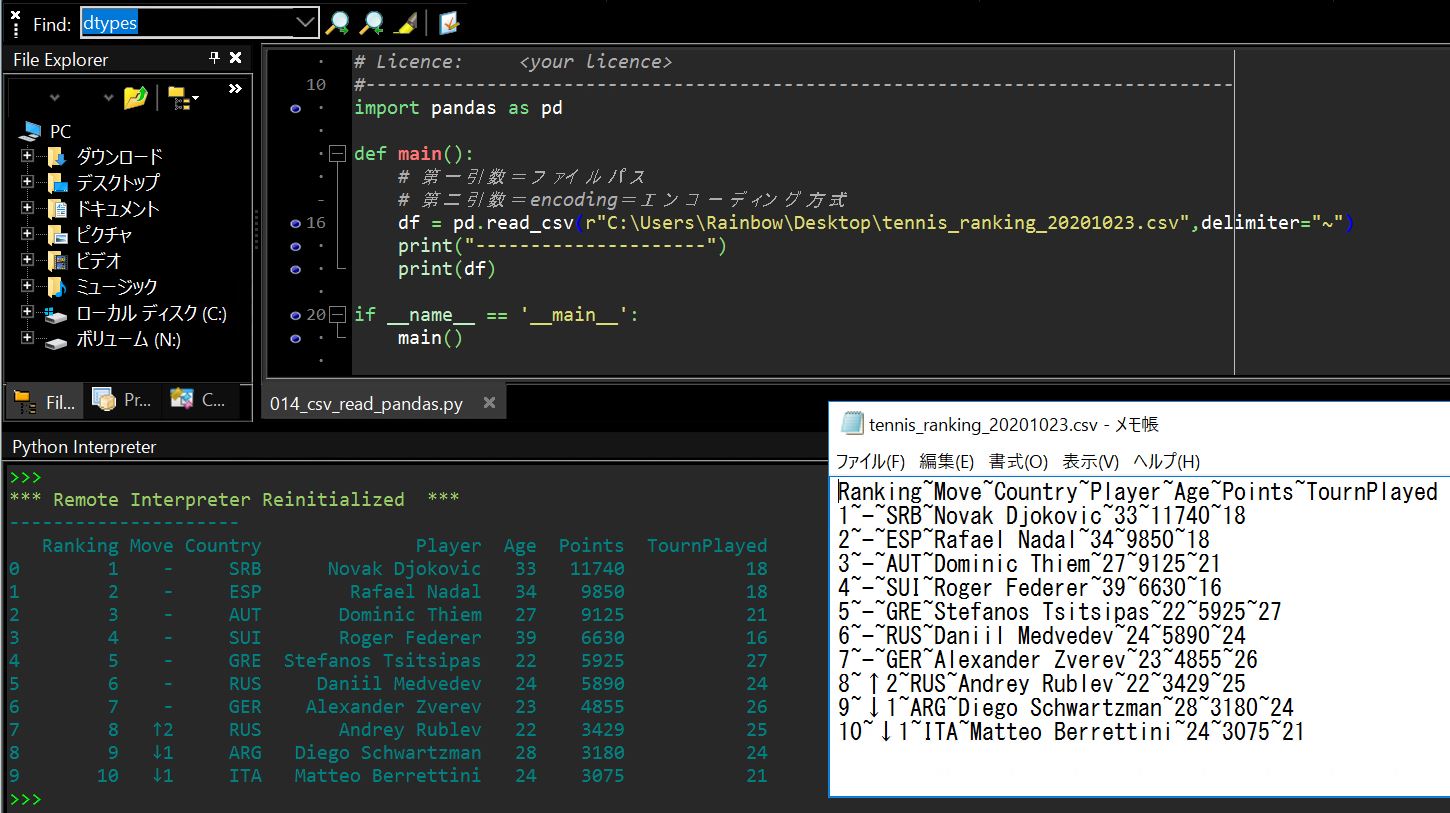
Ranking~Move~Country~Player~Age~Points~TournPlayed 1~-~SRB~Novak Djokovic~33~11740~18 2~-~ESP~Rafael Nadal~34~9850~18 3~-~AUT~Dominic Thiem~27~9125~21 4~-~SUI~Roger Federer~39~6630~16 5~-~GRE~Stefanos Tsitsipas~22~5925~27 6~-~RUS~Daniil Medvedev~24~5890~24 7~-~GER~Alexander Zverev~23~4855~26 8~↑2~RUS~Andrey Rublev~22~3429~25 9~↓1~ARG~Diego Schwartzman~28~3180~24 10~↓1~ITA~Matteo Berrettini~24~3075~21
(サンプルプログラム)
上記のcsvを読み込むサンプルプログラムです。
import pandas as pd
def main():
# 第一引数=ファイルパス
# 第二引数=delimiter=区切り文字はチルダ「~」を指定
df = pd.read_csv(r"C:\Users\Rainbow\Desktop\tennis_ranking_20201023.csv",delimiter="~")
print(df)
if __name__ == '__main__':
main()
(図121)プログラム実行結果(例)
(1-3) read_csvの主要なオプションご紹介
(1-3-1) 主要オプションの概要
read_csvで頻繁に使用する代表的なオプションについて表にまとめました。一部のオプションに関しては(1-3-2)以降で実機の確認画像を貼っているので、必要に応じてご覧頂けたらと思います
(表)
| オプション (=以降はデフォルト値) |
型 | 備考 |
| sep=’,’ | str | ・「区切り文字」の指定 ・デフォルトはカンマ「,」 |
| encoding | str | ・エンコーディング方式を指定します。 (例) encoding = ‘utf-8’ |
| delimiter=None | str | ・sepの別名 |
| header=’infer’ | int list of int |
・カラム名として利用する行の番号(一つor複数) ・デフォルトでは推測(infer)します。 ・複数行あるケースは配列で指定も可能(例:[0,1,3])。 |
| names | array-like | ・使用するカラム名を明示的に宣言する場合に使います。 ・この場合は「header」と競合しないよう「header=0」を記載する必要があります。 |
| index_col | int, str sequence of int / str |
・行ラベルとして使用する列を指定します。 ・複数列を指定したら、マルチインデックスになります。 |
| skiprows | int 範囲指定(rangeなど) |
・読み込みをSkipする行を指定します。 ①特定行の例 skiprows=1 ②範囲指定の例: skiprows=range(1,2000000) |
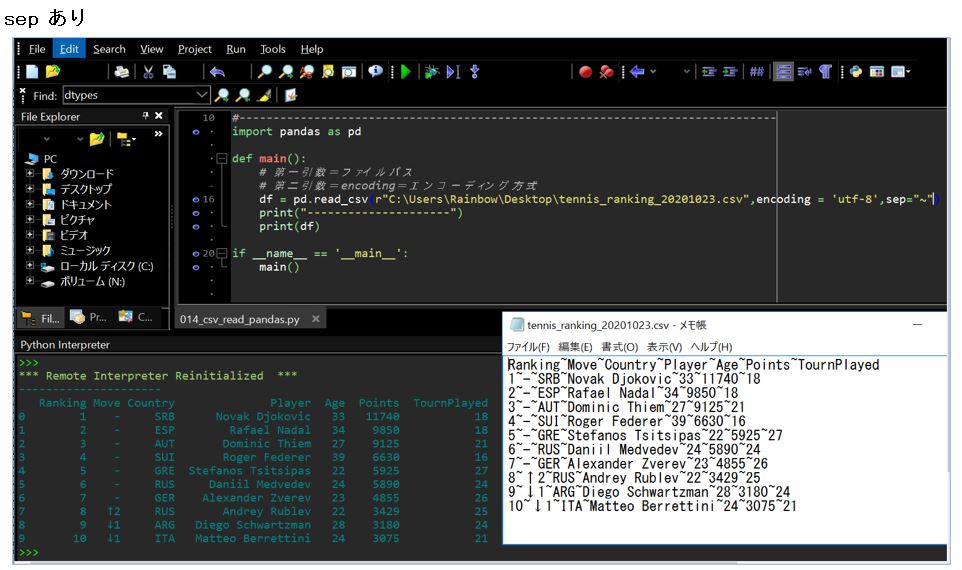
(1-3-2) オプション「sep」の効果が分かる実例
(図132)sep=”~”によってチルダで区切って表示されています。
(1-3-3) オプション「delimiter」の効果が分かる実例
(図133)delimiter=”~”もsepと同様にチルダで区切った結果を表示しています。

(1-3-4) オプション「header」の効果が分かる実例
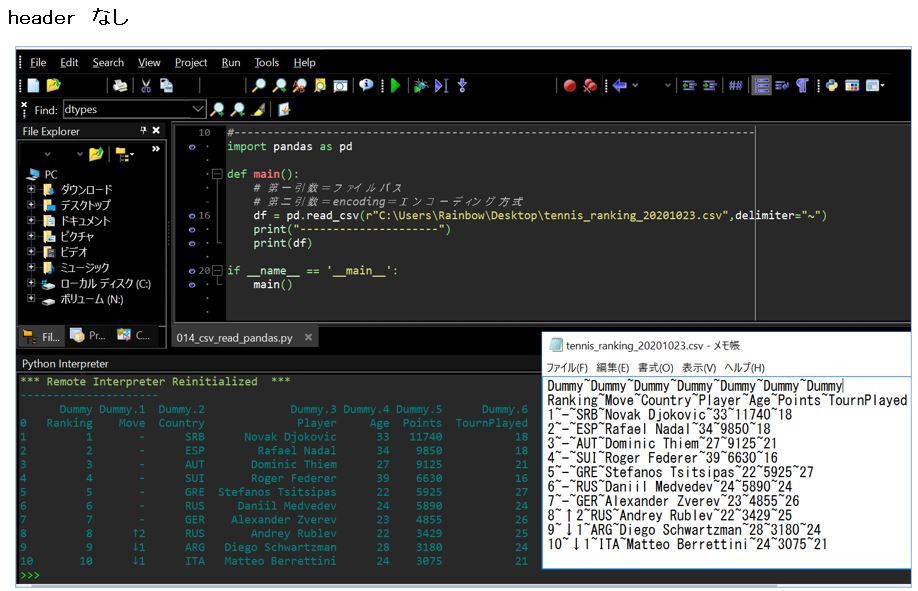
(図134)①header「なし」のパターン
1行目にダミーのヘッダー行(Dummy~Dummy~・・・)を差し込んだ場合、header指定なしで読み込むと、当然ながらDummyの1行目がheaderとして表示され、本当のヘッダーである2行目は普通の行データとして表示されている。
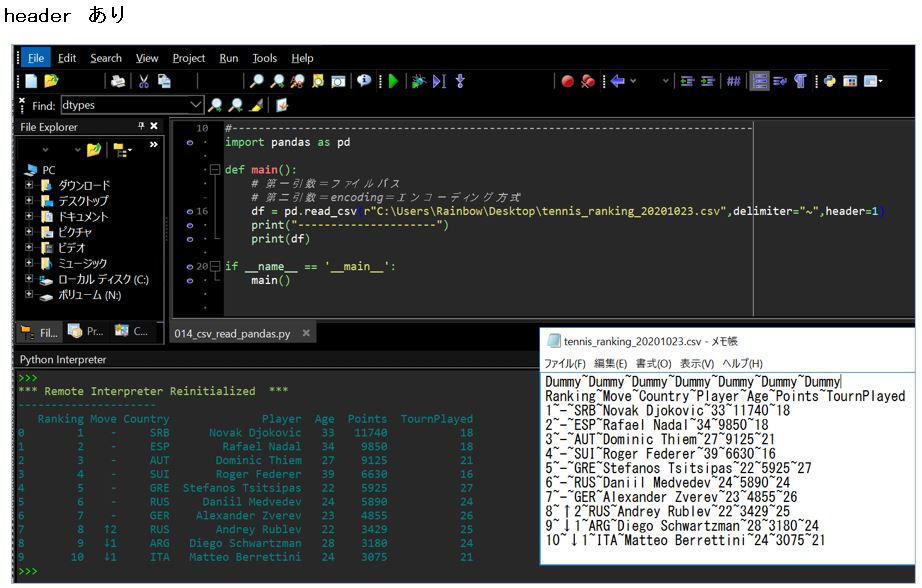
(図134)②header「あり」のパターン
header=1(つまり2行目)を指定する事で、Dummyの行を飛ばして2行目をヘッダーとして読み込んでいます。
(1-3-5) オプション「index_col」の効果が分かる実例
(図135)index_col=2(つまり3列目)を指定したので国名が左端にインデックスとして表示されています。

(1-4) 読み込んだcsvのカラム名やレコードを取得する方法
読み込んだcsvのカラム名やレコードを取得する方法についても、下記の記事で解説しています。
https://rainbow-engine.com/python-csv-fetch-column/