(0)目次&概説
(1) エラー1:sqlalchemy.exc.ArgumentError
(1-1) 発生状況・エラーメッセージ
(1-1-1) エラーメッセージ
(1-1-2) エラーとなったソース
(1-2) 原因
(1-3) 対処方法
(1-3-1) OracleDBのバージョンが12.2以上の場合
(1-3-2) OracleDBのバージョンが12.1以下の場合
(2) 警告1:DtypeWarning: Columns (4) have mixed types.
(2-1) 発生状況・エラーメッセージ
(2-1-1) エラーメッセージ
(2-1-2) エラーとなったソース
(2-2) 原因
(2-3) 対処方法
(1) エラー1:sqlalchemy.exc.IdentifierError
(1-1) 発生状況・エラーメッセージ
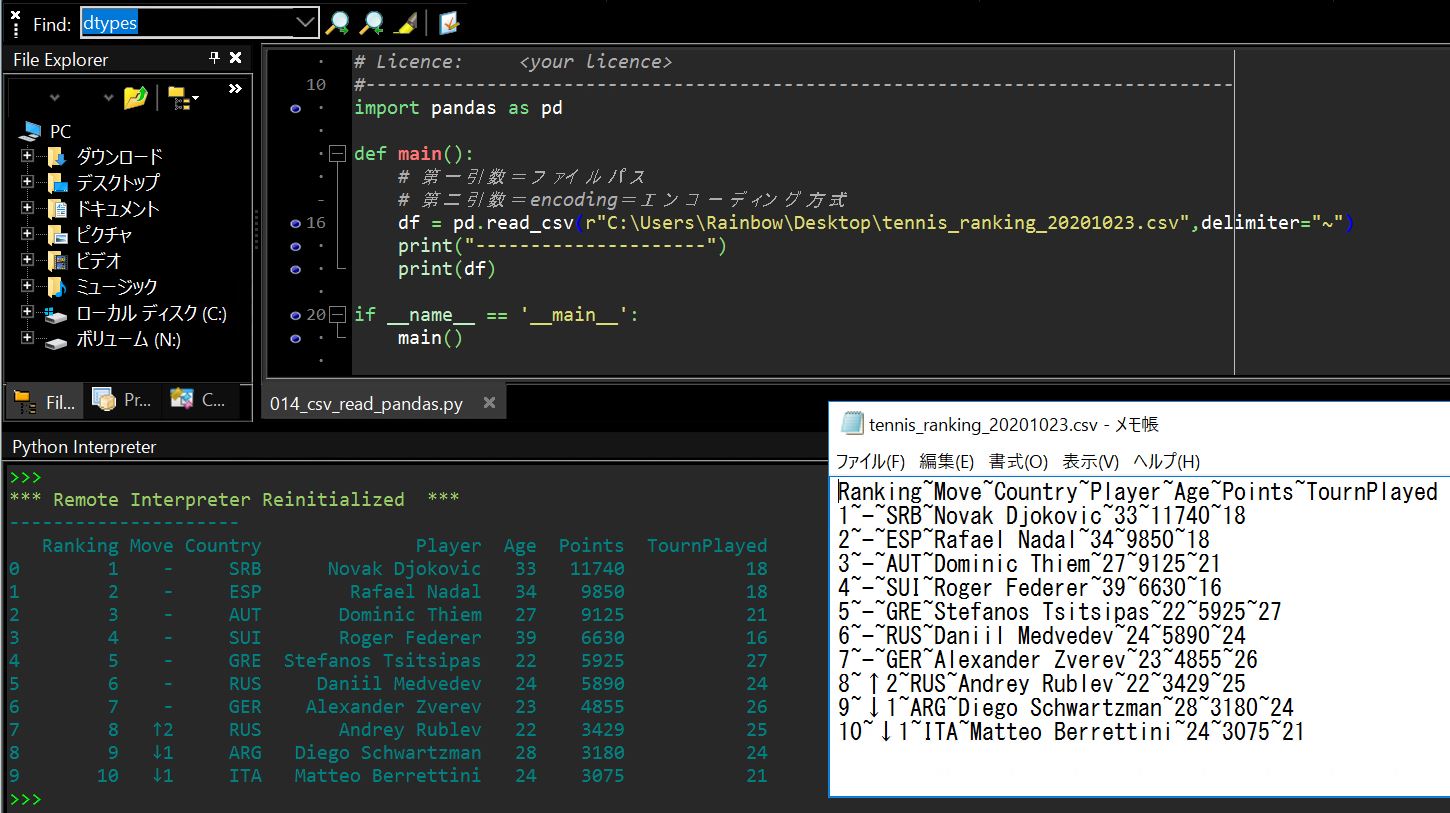
Web上にあるcsvデータを”datapackage”パッケージを用いて変数にロードし、それをPandasの”read_csv”関数でDataframeに取り込み、最後にPandasの”to_sql”関数でDBにINSERTしようとした際に発生しました(EngineはSQLAlchemyの”create_engine”で作成)。
(1-1-1) エラーメッセージ(抜粋)
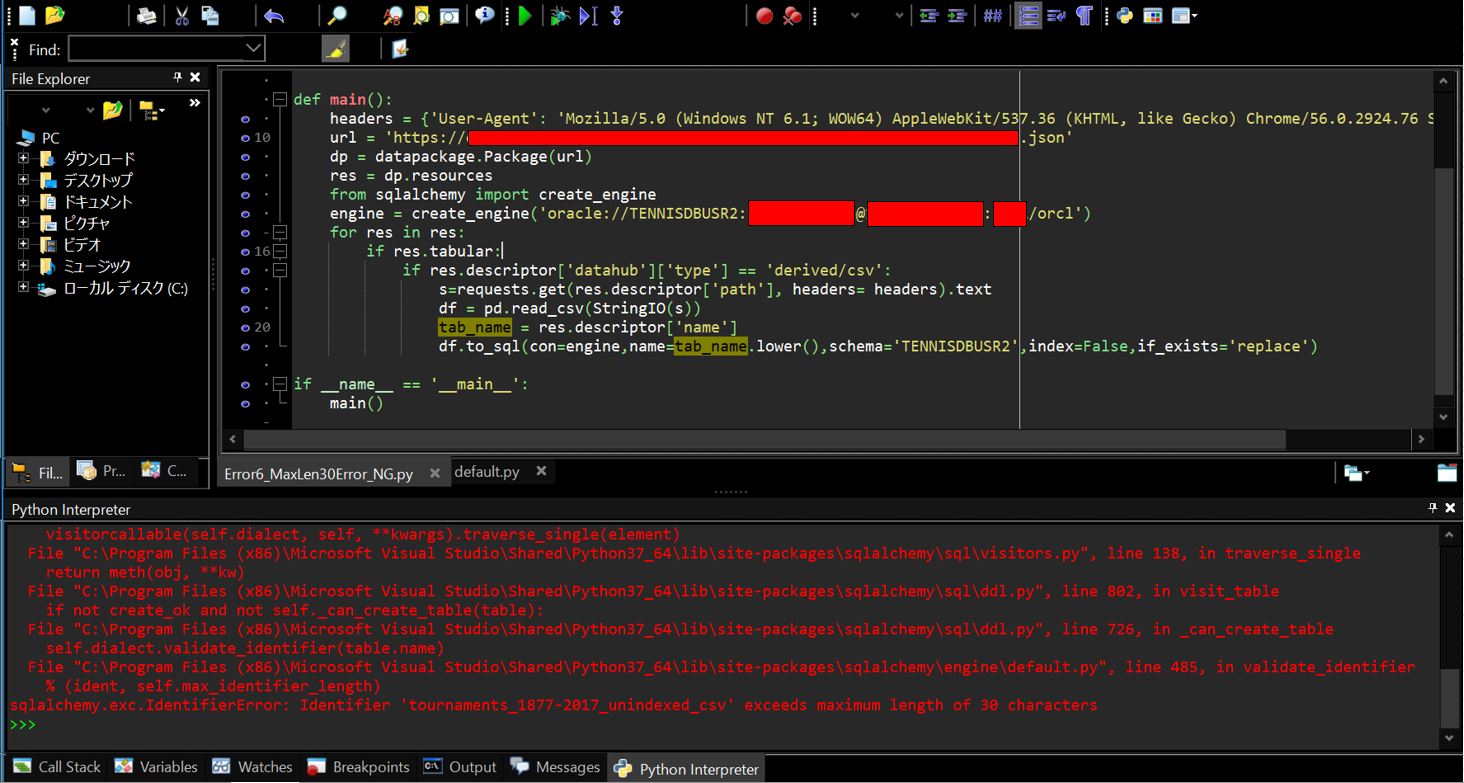
sqlalchemy.exc.IdentifierError: Identifier 'tournaments_1877-2017_unindexed_csv' exceeds maximum length of 30 characters
(1-1-2) エラーとなったソース
import datapackage
import cx_Oracle
import sqlalchemy
import pandas as pd
import requests
from io import StringIO
def main():
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.76 Safari/537.36'}
url = 'https://[your URL].json'
dp = datapackage.Package(url)
res = dp.resources
from sqlalchemy import create_engine
engine = create_engine('oracle://[your schema]:[your password]@[hostname]:[port]/[sid]')
for res in res:
if res.tabular:
if res.descriptor['datahub']['type'] == 'derived/csv':
s=requests.get(res.descriptor['path'], headers= headers).text
df = pd.read_csv(StringIO(s))
tab_name = res.descriptor['name']
df.to_sql(con=engine,name=tab_name.lower(),schema='[your schema]',index=False,if_exists='replace')
if __name__ == '__main__':
main()
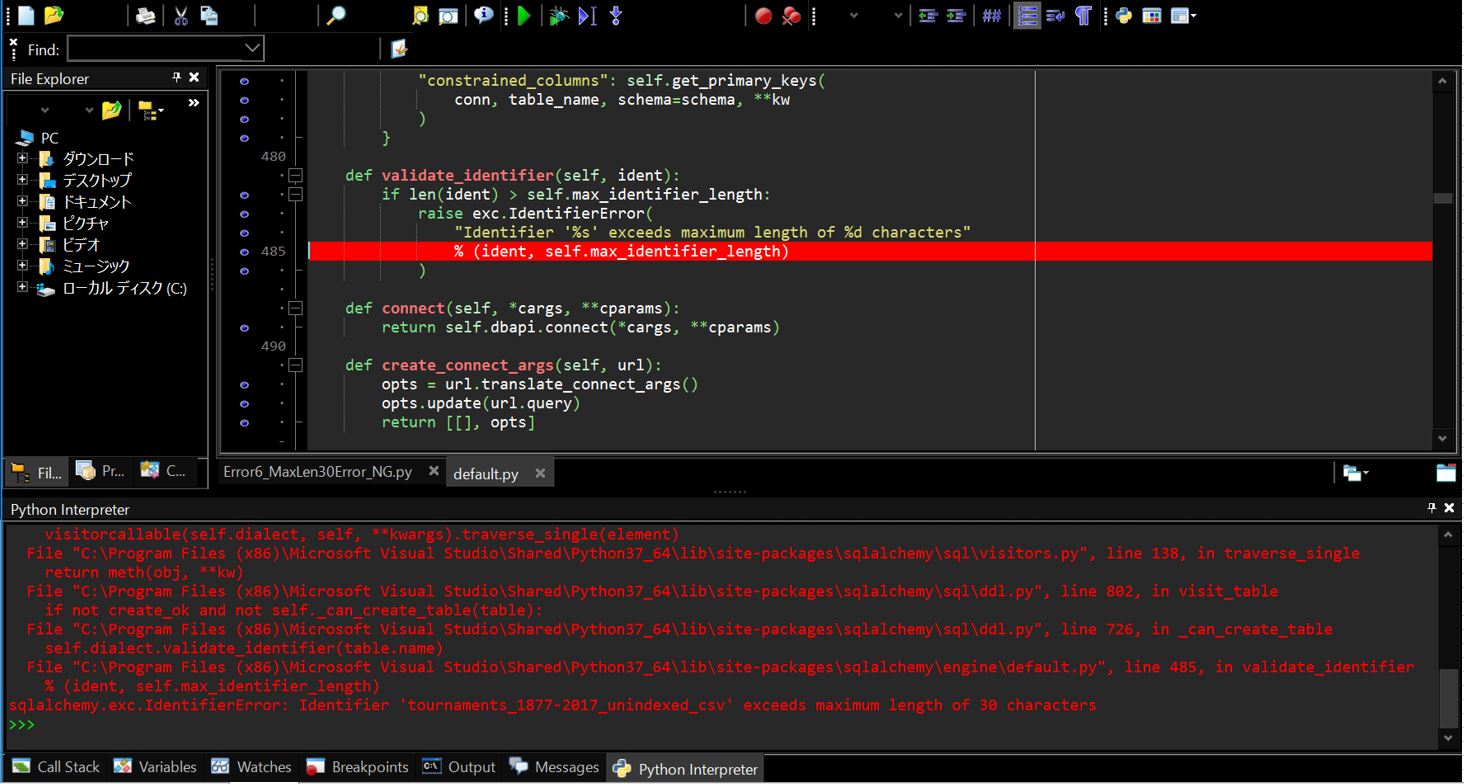
(図101)
エラー画面のキャプチャ
(1-2) 原因
Oracleが許容するテーブルの最大文字数(30バイト)を超えたテーブル名を登録しようとしたためエラーとなっています(※正確にはOracleの12.2=12c Release2以降ではこの上限が128バイトに緩和されているため、12.1以前のバージョンを使用している場合のみ30バイトの上限制約があります)。今回の私の環境は11gなので、この30バイト制限に引っかかってしまいました・・。
(1-3) 対処方法
(1-3-1) OracleDBのバージョンが12.2以上の場合
上限が128バイトのため、SQLAlchemy側でもその上限値を利用できるように”create_engine”ファンクションの引数に「max_identifier_length=128」を指定します。
engine = create_engine('oracle://[your schema]:[your password]@[hostname]:[port]/[sid]',max_identifier_length=128)
このオプションですが、12.1以下のDBで実行しても結局は以下のエラーになり駄目でした(当然ですが・・)
sqlalchemy.exc.DatabaseError: (cx_Oracle.DatabaseError) ORA-00972: identifier is too long
(1-3-2) OracleDBのバージョンが12.1以下の場合
残念ながら30バイト以下になるように調整を行うしか無さそうです・・(他に回避策があれば是非教えてください!)。私の場合は「str型」オブジェクトのreplaceメソッドを用いて文字列を短くしていきました・・。
(例)
テーブル名を”tmp_name”に格納して、strオブジェクトの”replace”メソッドを使って”_csv”といったような余分な文言を空白に置換して30バイト以下になるように調整をかけています。また下記の「res」はdatapackageの「Resouce」型オブジェクトで、「res.descriptor[‘name’]」でcsvファイルの名前を取得しています。
(※datapackageパッケージ⇒packageモジュール⇒Packageクラス⇒resourcesメソッド(Resoucesオブジェクトを返却))
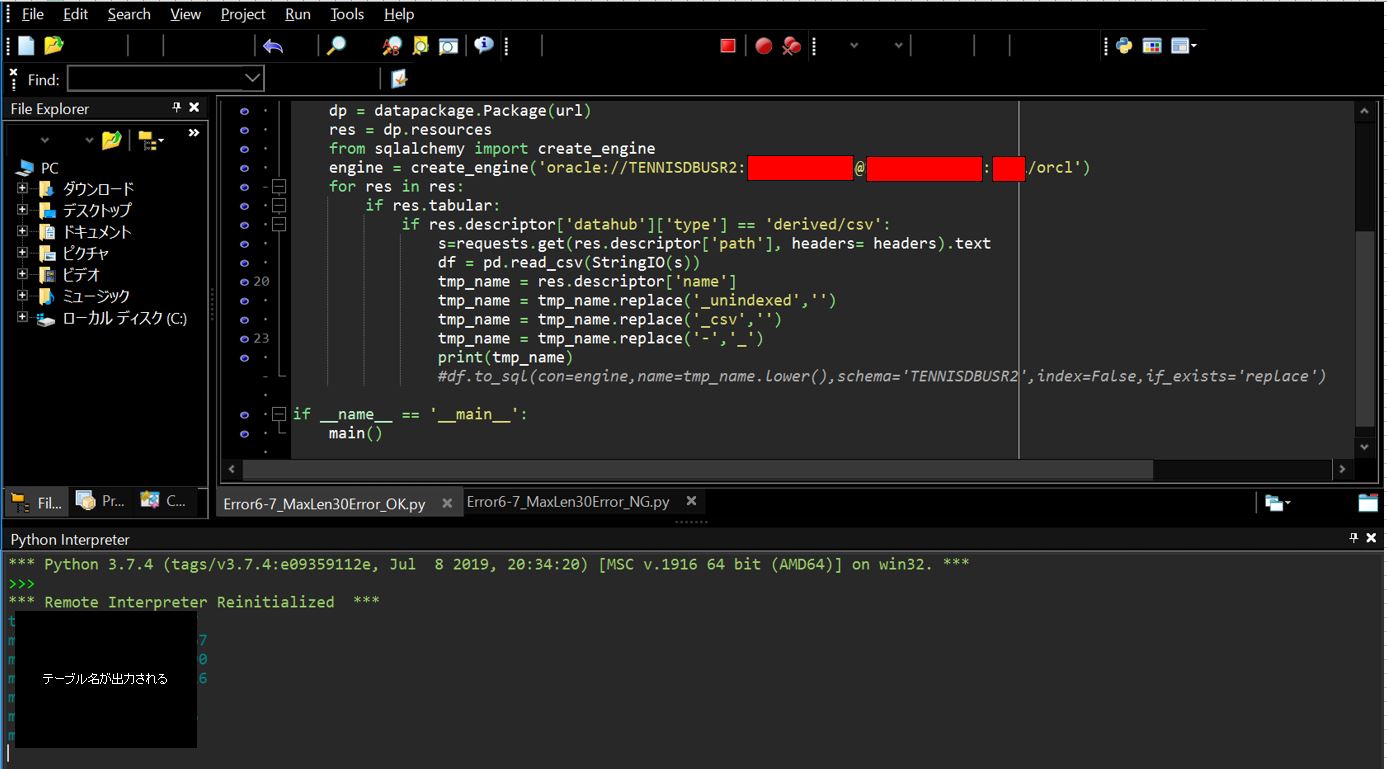
tmp_name = res.descriptor['name']
tmp_name = tmp_name.replace('_unindexed','')
tmp_name = tmp_name.replace('_csv','')
tmp_name = tmp_name.replace('-','_')
(図102)
テーブル名を30バイト以下にするとエラーが消える
(2) 警告1:DtypeWarning: Columns (4) have mixed types.
(2-1) 発生状況・エラーメッセージ
(2-1-1) 警告メッセージ
“Columns”の後ろの(4)はカラムの番号を意味しており、(4)だとテーブルの左から4つ目のカラムになります。
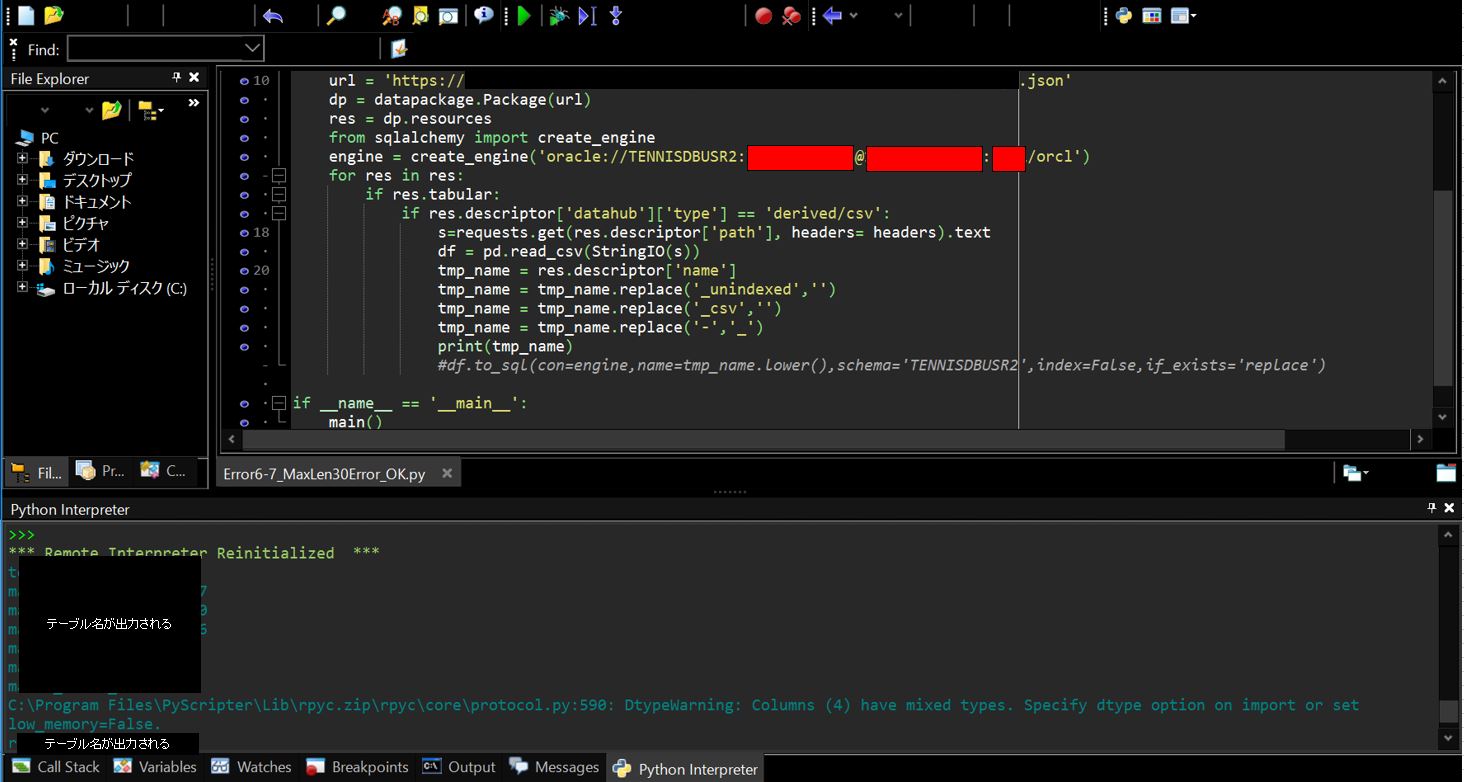
C:\Program Files\PyScripter\Lib\rpyc.zip\rpyc\core\protocol.py:590: DtypeWarning: Columns (4) have mixed types. Specify dtype option on import or set low_memory=False.
(2-1-2) 警告が出たソース
import datapackage
import cx_Oracle
import sqlalchemy
import pandas as pd
import requests
from io import StringIO
def main():
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.76 Safari/537.36'}
url = 'https://[your URL].json'
dp = datapackage.Package(url)
res = dp.resources
from sqlalchemy import create_engine
engine = create_engine('oracle://[your schema]:[your password]@[hostname]:[port]/[sid]')
for res in res:
if res.tabular:
if res.descriptor['datahub']['type'] == 'derived/csv':
s=requests.get(res.descriptor['path'], headers= headers).text
df = pd.read_csv(StringIO(s))
tmp_name = res.descriptor['name']
tmp_name = tmp_name.replace('_unindexed','')
tmp_name = tmp_name.replace('_csv','')
tmp_name = tmp_name.replace('-','_')
print(tmp_name)
#df.to_sql(con=engine,name=tmp_name.lower(),schema='TENNISDBUSR2',index=False,if_exists='replace')
if __name__ == '__main__':
main()
(図201)
コンソールに「DtypeWarning」が表示されている
(2-2) 原因
一つのカラムに複数のデータ型の値が入り混じっている事が原因です。Pandasの”read_csv”関数はデータを読み込む際、csvの全てのデータを読み込んだ上で各カラム毎に何のデータ型かを推測しています。この処理はメモリを多く消費するのですが、low_memory=Trueのオプションで実行するとメモリの消費を抑えるためにデータ型の推測をしないため、そのような警告文が出ています。
しかし、この対処自体では問題が解決するわけではないため、後述の「dtype指定」を行っていくのが現実的となります。
(2-3) 対処方法
もし警告が出ているカラムのデータ型が予め特定できる場合は、「dtype指定」を行うのが良いとされています。
「dtype指定」は例えば「dtype={‘week_year’:’int16′,’week_month’:’int16′}」のようにカラム毎に読み込む際のデータ型を事前に指定して、それを”read_csv”関数の引数として与える事で、データ型を特定するためのメモリ消費を削減できます。
今回は対象の列が「datetype」型のため、dtypeにて指定する事はできません(csv自体がinteger型、string型、float型のみを保持できるため)。そのためWorkaroundとして”read_csv”関数の引数にて「parse_dates=[列名list]」のオプションを指定して明示的にdatetype型としてデータを抽出させる事で対応します。
■修正前
df = pd.read_csv(StringIO(s))
■修正後
df = pd.read_csv(StringIO(s),parse_dates=['match_time'])
(図202)
parse_datesで”match_date”カラムを明示的にdatetime型で読み込み