今回PythonのPandasライブラリを用いてcsvファイルを読み込み、カラム名やテーブルのレコードを取得する方法をご紹介します。
<目次>
(1) Pythonでcsvのカラム名・テーブルのレコードを取得する方法
(1-1) 構文
(1-2) サンプルプログラム
(1-3) 参考「’pandas.core.frame.DataFrame’」型で使える属性値について
(1) Pythonでcsvのカラム名・テーブルのレコードを取得する方法
(1-1) 構文
(構文)
# 準備:pandasのライブラリをインポート import pandas as pd # read_csvメソッドで指定したcsvファイルパスにあるcsvファイルを読み込み df = pd.read_csv(r"[csvファイルパス]") # カラムを表示(全部) print(df.values) # カラムを表示(インデックス指定) print(df.values[1]) # 「for [ループ変数] in [リスト]:」の構文を使って、Dataframe(df変数)の # カラムリスト(columns属性)のカラムを順番にループしていき # その結果をcolという名前の変数に格納します。 for col in df.columns: print(col)
(1-2) サンプルプログラム
上記の構文にmainメソッド等を付けて実行可能な形にしたサンプルプログラムをご紹介します。
(サンプルプログラム)
import pandas as pd
def get_data():
# 第一引数=ファイルパス
# 第二引数=encoding=エンコーディング方式
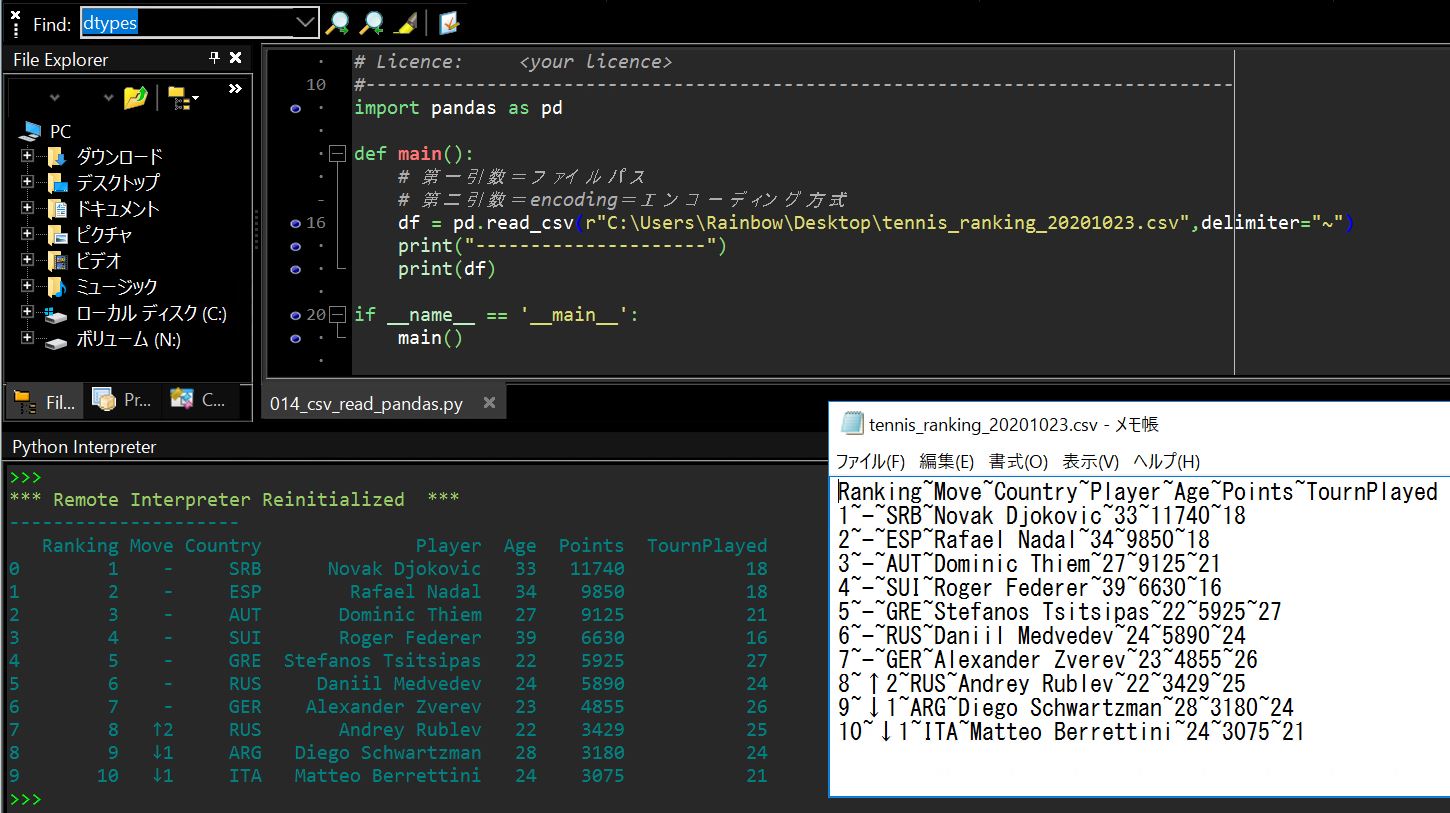
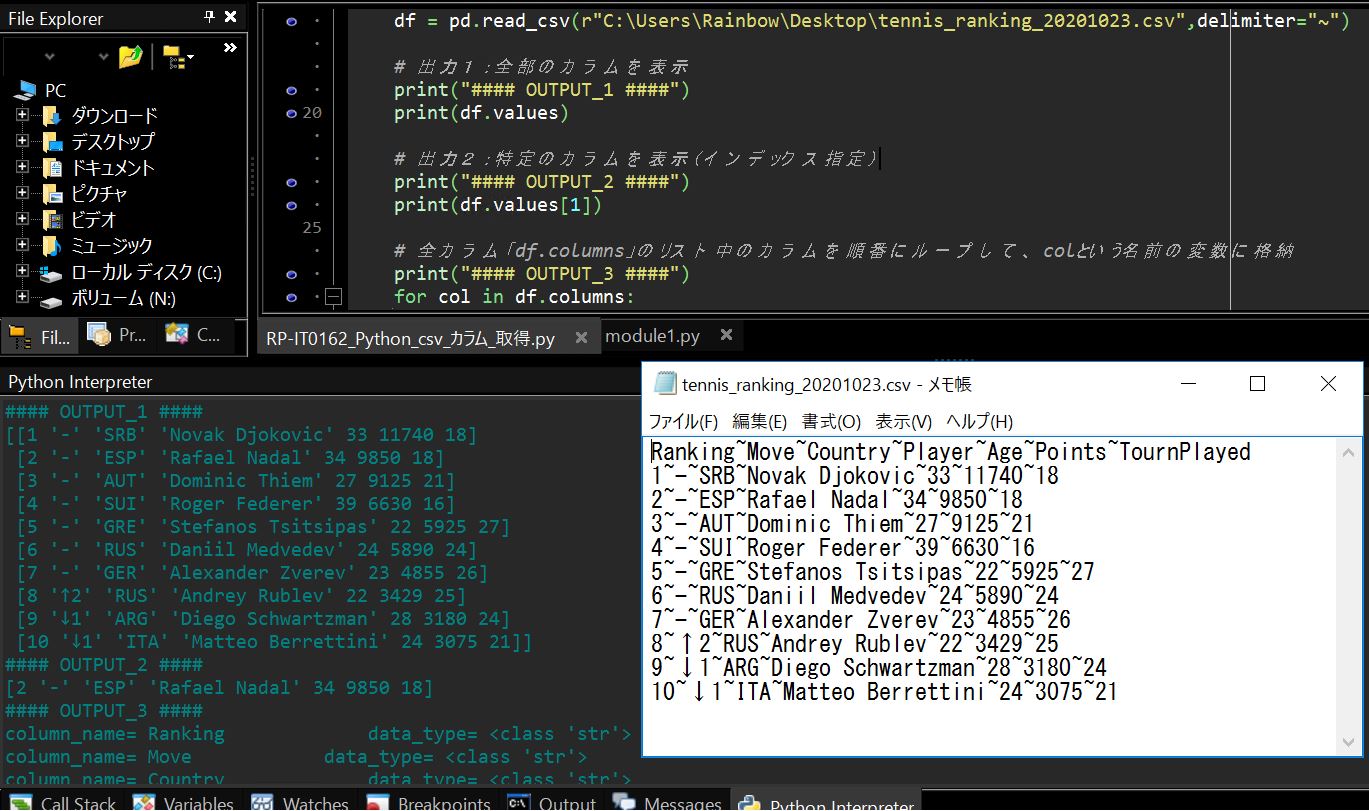
df = pd.read_csv(r"C:\Users\Rainbow\Desktop\tennis_ranking_20201023.csv",delimiter="~")
# 出力1:カラムを表示(全部)全部のカラムを表示
print("#### OUTPUT_1 ####")
print(df.values)
# 出力2:特定のカラムを表示(インデックス指定)
print("#### OUTPUT_2 ####")
print(df.values[1])
# 全カラム「df.columns」のリスト中のカラムを順番にループして、colという名前の変数に格納
print("#### OUTPUT_3 ####")
for col in df.columns:
# 出力3:カラムの値を表示
print("column_name= "+str(col)+"\t\t\t data_type= "+str(type(col)))
def main():
get_data()
if __name__ == '__main__':
main()
(図121)実行結果サンプル
(1-3) 参考「’pandas.core.frame.DataFrame’」型で使える属性値について
上記例で「pd.read_csv()」の結果を「df」という変数に格納していますが、そのdf変数のインスタンスオブジェクト型が「’pandas.core.frame.DataFrame’」になっております。
(図131)
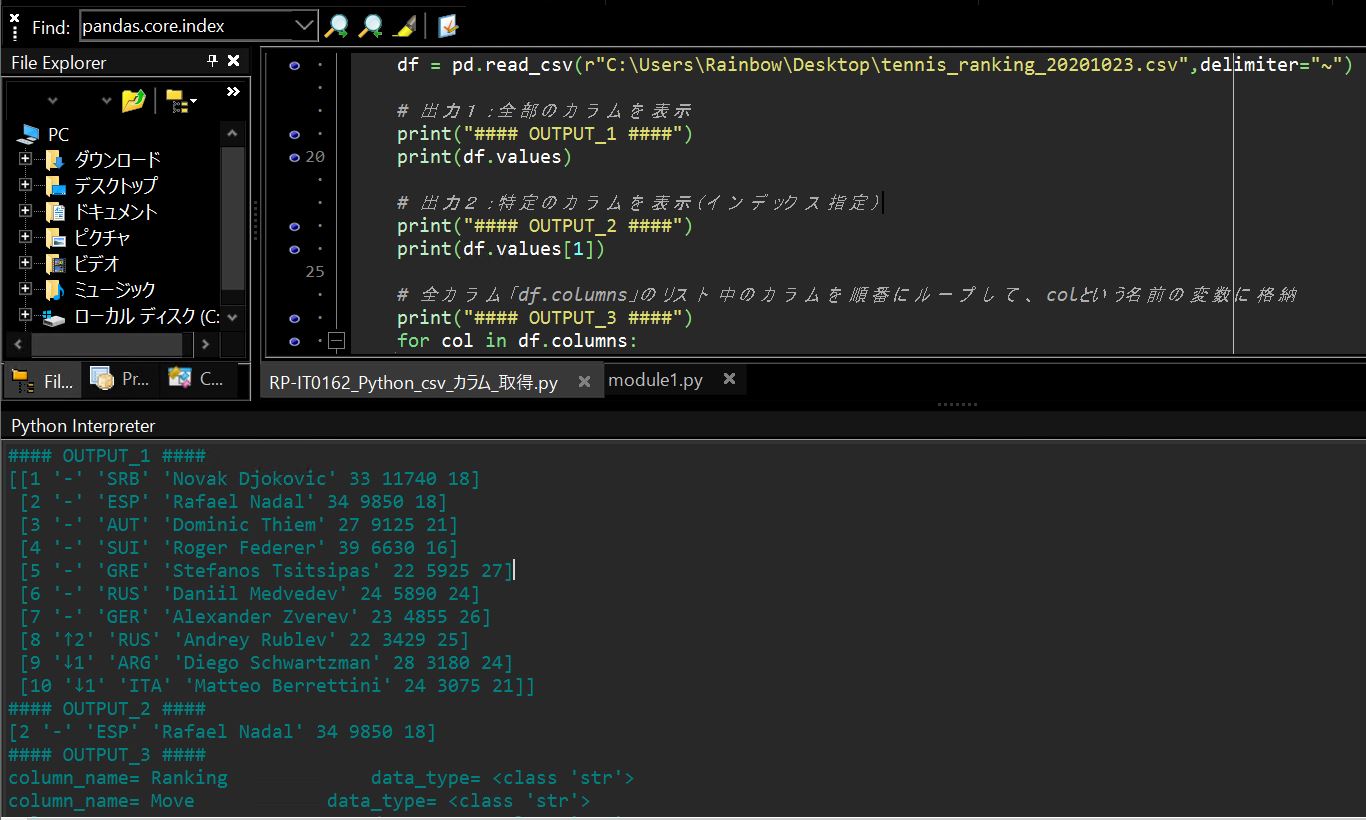
そのDataFrame型で使える属性が以下のPandasのページで紹介されています。上記の「df.columns」もその属性の一つで、Dataframeのカラムのリストを取得する事ができます。
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html