(0)目次&概説
(1) 記事の目的
(2) エラー1:AttributeError: ‘generator’ object has no attribute ‘next’
(2-1) エラー概要
(2-2) 原因
(2-3) 対処法
(3) エラー2:StopIteration
(3-1) エラー概要
(3-2) 原因
(3-3) 対処法
(1) 記事の目的
この記事ではdatapackageの学習中に直面したエラーとその解決策を備忘として記録します。
>目次にもどる
(2) エラー1:AttributeError: ‘generator’ object has no attribute ‘next’
(2-1) エラー概要
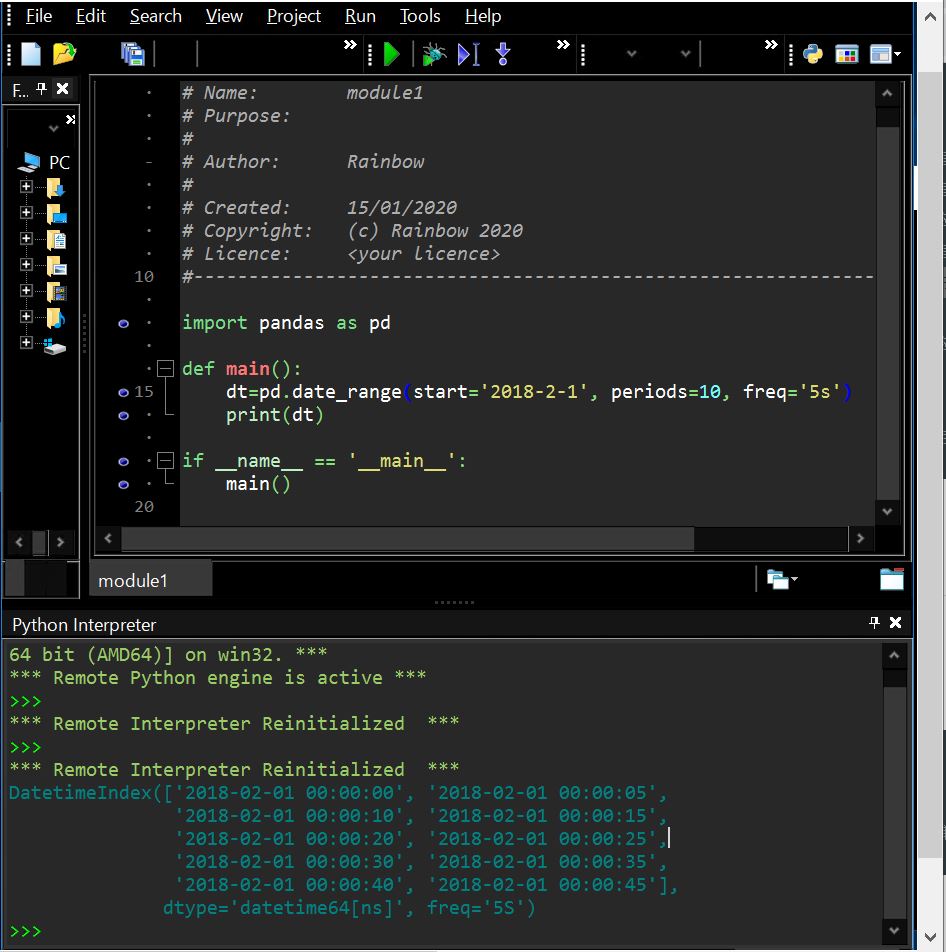
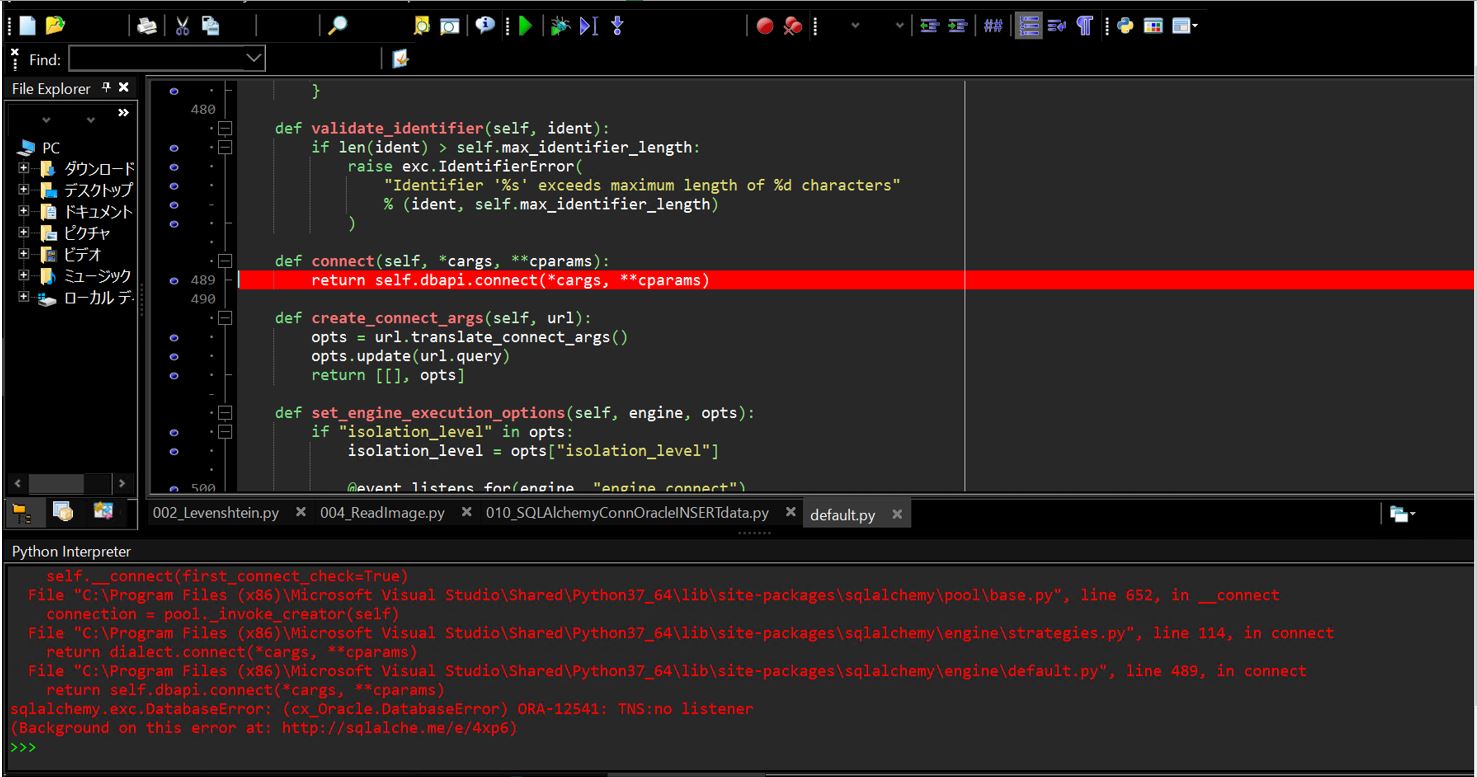
このエラーはdatapackageのPackageクラスを使ってcsvデータをロードして、iter()メソッドを使ってイテレータ(リストと似てるが取り出すと空になる)を作り、次の要素を取り出そうとして「next()」メソッドを呼び出した時に発生しました。
(図211)
■エラーしたプログラム
(エラー発生行は16行目)
import datapackage
def count(iter):
try:
return len(iter)
except TypeError:
return sum(1 for _ in iter)
def main():
url = 'https://raw.githubusercontent.com/frictionlessdata/example-data-packages/master/periodic-table/datapackage.json'
dp = datapackage.Package(url)
print([e['name'] for e in dp.resources[0].read(keyed=True) if int(e['atomic number']) < 10])
rows = datapackage.Package(url).resources[0].iter()
print(rows.next())
if __name__ == '__main__':
main()
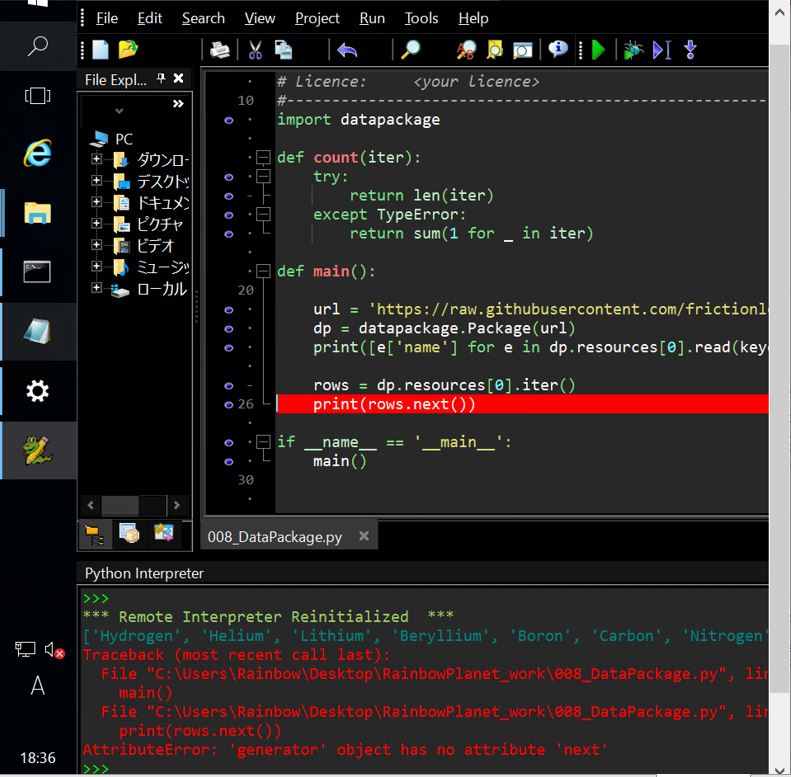
(2-2) 原因
結論としては「next()」メソッドではなく「__next__()」メソッドが正しいです。今回の例ではイテレータ(Generatorクラス)に「next」属性が無い事がエラーメッセージから分かります。実際に関数の型を「type()」で調べると「<class ‘generator’>」となっており、
(図221)
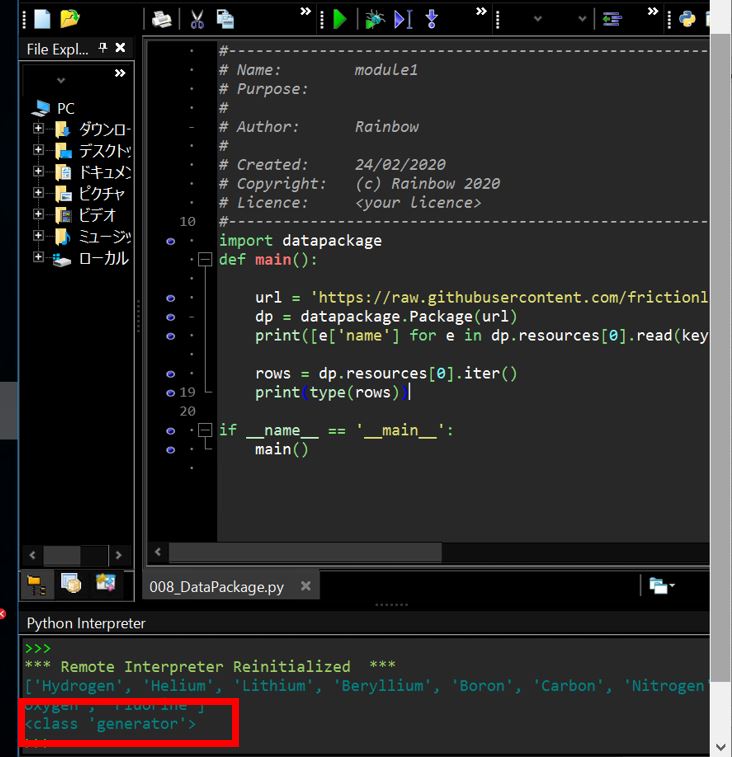
Pythonのドキュメントの「ジェネレータ-イテレータメソッド」を見ると、Python3では「__next__()」である事が分かります(しかし「next()」はforループで回せないので用途は少ないかも)。
https://docs.python.org/ja/3/reference/expressions.html?highlight=generator#generator.__next__
(2-3) 対処法
上記の通り「__next()__」を使うと正しく次の値を取得できました。
(図231)
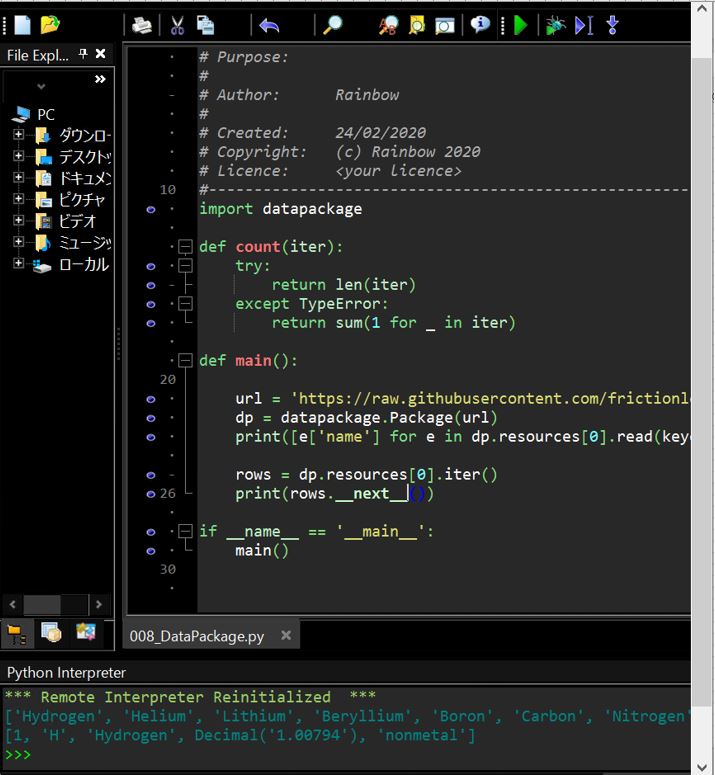
■改善後のプログラム
(差分は16行目の「print(rows.next())」→「print(rows.__next__())」)
import datapackage
def count(iter):
try:
return len(iter)
except TypeError:
return sum(1 for _ in iter)
def main():
url = 'https://raw.githubusercontent.com/frictionlessdata/example-data-packages/master/periodic-table/datapackage.json'
dp = datapackage.Package(url)
print([e['name'] for e in dp.resources[0].read(keyed=True) if int(e['atomic number']) < 10])
rows = datapackage.Package(url).resources[0].iter()
print(rows.__next__())
if __name__ == '__main__':
main()
(3) エラー2:StopIteration
(3-1) エラー概要
これはエラーと言うよりは単にIteratorに対する私の理解不足だっただけですが、イテレータの要素数をcountしてからループ処理で要素を取りだそうとしたら「StopIteration」のエラーが出ました。
(図311)
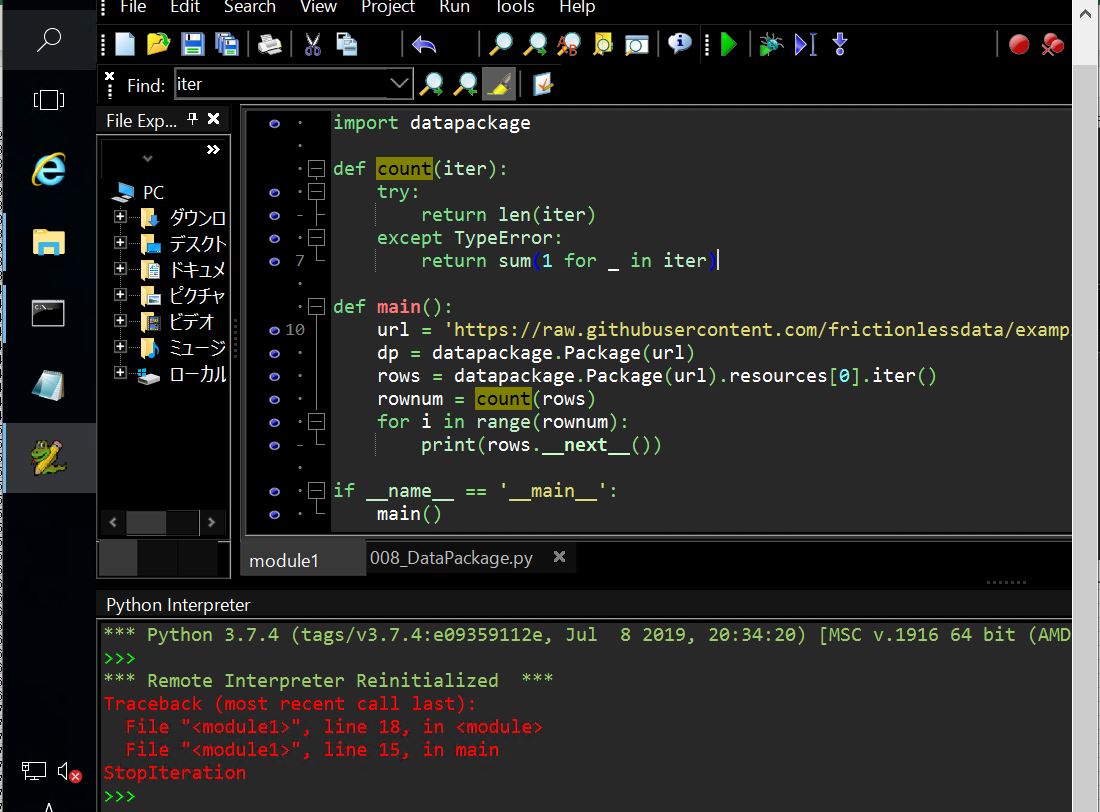
■エラーしたプログラム
(エラー発生行は18行目の「print(rows.__next__())」)
import datapackage
def count(iter):
try:
return len(iter)
except TypeError:
return sum(1 for _ in iter)
def main():
url = 'https://raw.githubusercontent.com/frictionlessdata/example-data-packages/master/periodic-table/datapackage.json'
dp = datapackage.Package(url)
print([e['name'] for e in dp.resources[0].read(keyed=True) if int(e['atomic number']) < 10])
rows = dp.resources[0].iter()
print(count(rows))
for i in range(2):
print(rows.__next__())
if __name__ == '__main__':
main()
(3-2) 原因
原因はその直前のcount関数の内部でlen()関数を呼んでおり、そのタイミングでイテレータの末尾まで到達してしまったために、要素を取りだそうとした瞬間に次の要素は無く「StopIter」となってしまったと推定します。
(3-3) 対処法
対処方法としてはcount関数を使わずに、次の構文でイテレータの内容を順番に取り出します。
for i in rows:
print(i)
(図331)
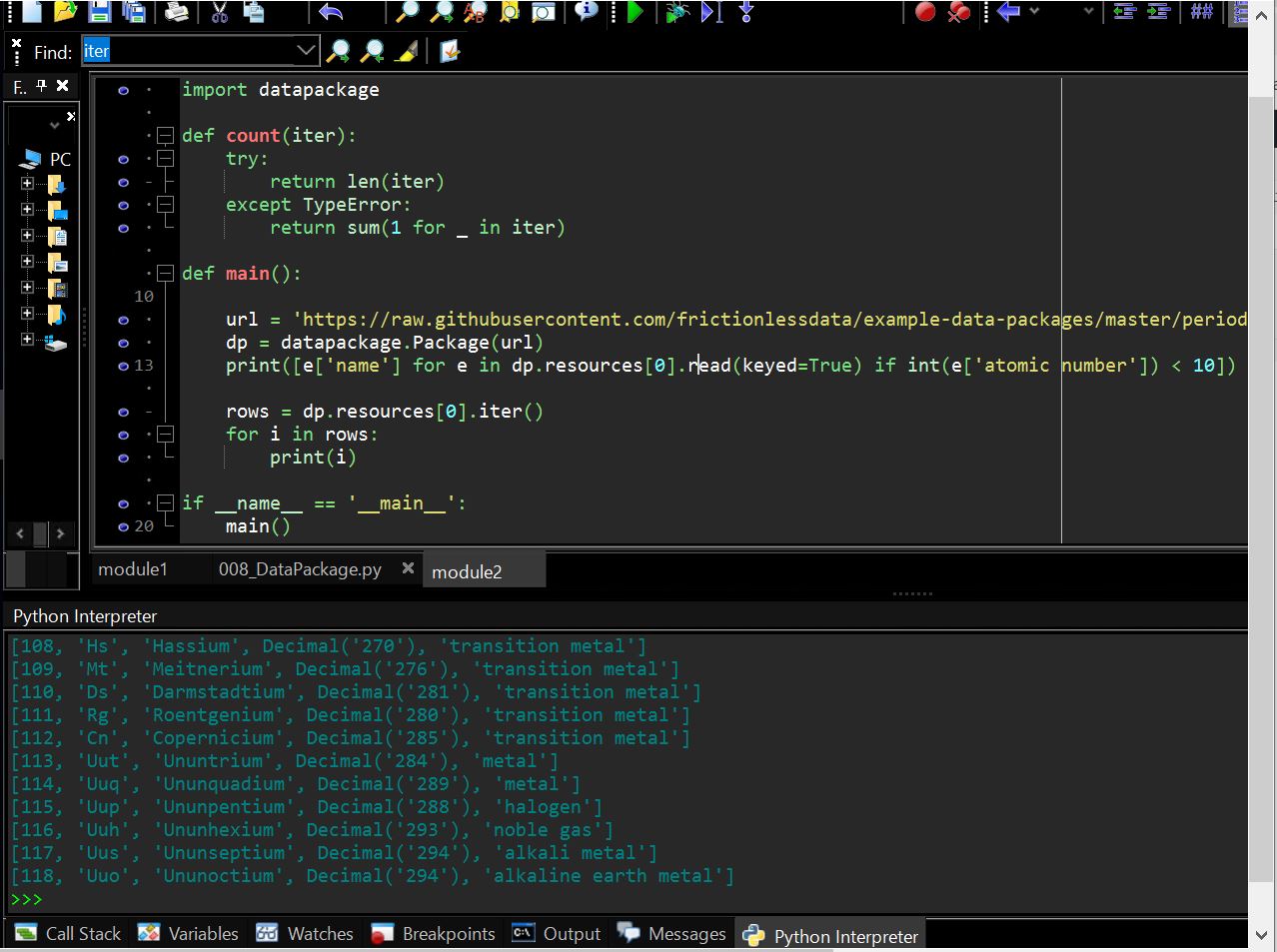
■改善後のプログラム
(16~17行目のforループの書き方を修正)
import datapackage
def count(iter):
try:
return len(iter)
except TypeError:
return sum(1 for _ in iter)
def main():
url = 'https://raw.githubusercontent.com/frictionlessdata/example-data-packages/master/periodic-table/datapackage.json'
dp = datapackage.Package(url)
print([e['name'] for e in dp.resources[0].read(keyed=True) if int(e['atomic number']) < 10])
rows = dp.resources[0].iter()
for i in rows:
print(i)
if __name__ == '__main__':
main()