<目次>
(1) OpenAIのEmbeddingの使い方
(1-1) やりたいこと
(1-2) 概要:OpenAIのEmbeddingとは?
(1-3) STEP1:サンプルコードを動かしてみる(Hello World)
(1-4) STEP2:(ユースケース例)テキストの類似度の検証
(1) OpenAIのEmbeddingの使い方
(1-1) やりたいこと
・OpenAIのEmbeddingとは?を理解する
・実際のサンプルコードを動かしてみる
・実用例として「テキストの類似度」を算出してみる
(1-2) 概要:OpenAIのEmbeddingとは?
・自然言語処理において、単語や文章を「数値化する技術」
・単語や文章をベクトル表現できる(ベクトル空間にマッピングする)
→類似するものは近くに配置され、異なるものは離れた位置に配置される
・EmbeddingにはGPT3モデルが使用されている
・「text-embedding-ada-002」モデルの入力トークンの上限は「8191」
・ただし、Azure Open AIの場合は入力トークンの上限は「2048」(2023年3月時点)
・「text-embedding-ada-002」モデルのベクトルは1536次元である
(参考)
(1-3) STEP1:サンプルコードを動かしてみる(Hello World)
(前提)
・Open AIのAPIが疎通している(★)
(サンプルプログラム)
import openai
import pandas as pd
# OpenAI APIキーをセット
openai.api_key = "xxxxxxxxxxxxxxxxxxxxx"
# Modelの指定
model = 'text-embedding-ada-002'
def get_embedding(text, model=model):
text = text.replace("\n", " ")
result = openai.Embedding.create(
engine=model,
input = [text]
)
return result['data'][0]['embedding']
def main():
# 入力(prompt)のデータ(PandasのDataFrame)の生成
df = pd.DataFrame({'value': ['apple', 'banana', 'orange', 'melon']},index=['1', '2', '3', '4'])
# APIコール
df["embedding_vector"] = df["value"].apply(lambda x : get_embedding(x))
# csv出力
df.to_csv('./embedded_output.csv', index=False)
if __name__ == "__main__":
main()
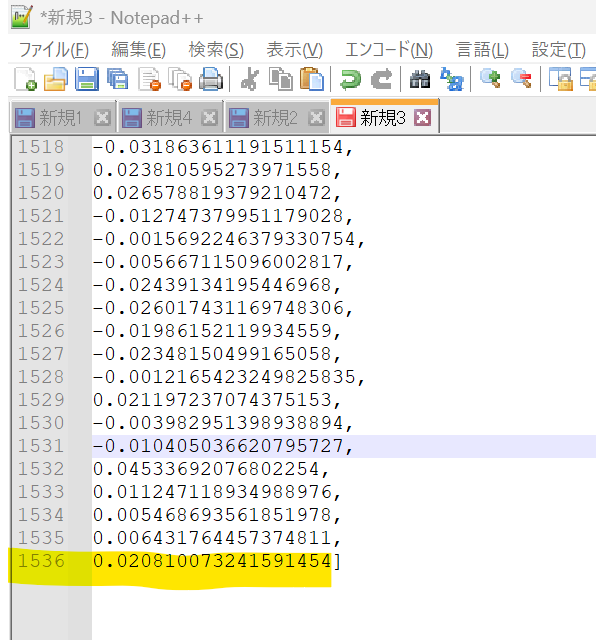
出力されたcsvは下記のようになっております。中略していますが、各行1536次元のListになっています。
(出力結果)
value,embedding_vector apple,"[0.0077999732457101345, -0.02301608957350254, ..(中略).. , -0.015654779970645905, 0.006107009015977383]" banana,"[-0.013975119218230247, -0.03290277719497681, ..(中略).. , -0.017215345054864883, 0.0018967173527926207]" orange,"[0.0045590330846607685, -0.03615625947713852, ..(中略).. , 0.00458207493647933, -0.001618703594431281]" melon,"[-0.003729138756170869, -0.02945852279663086, ..(中略).. , -0.015612214803695679, -0.023585548624396324]"
(図111)
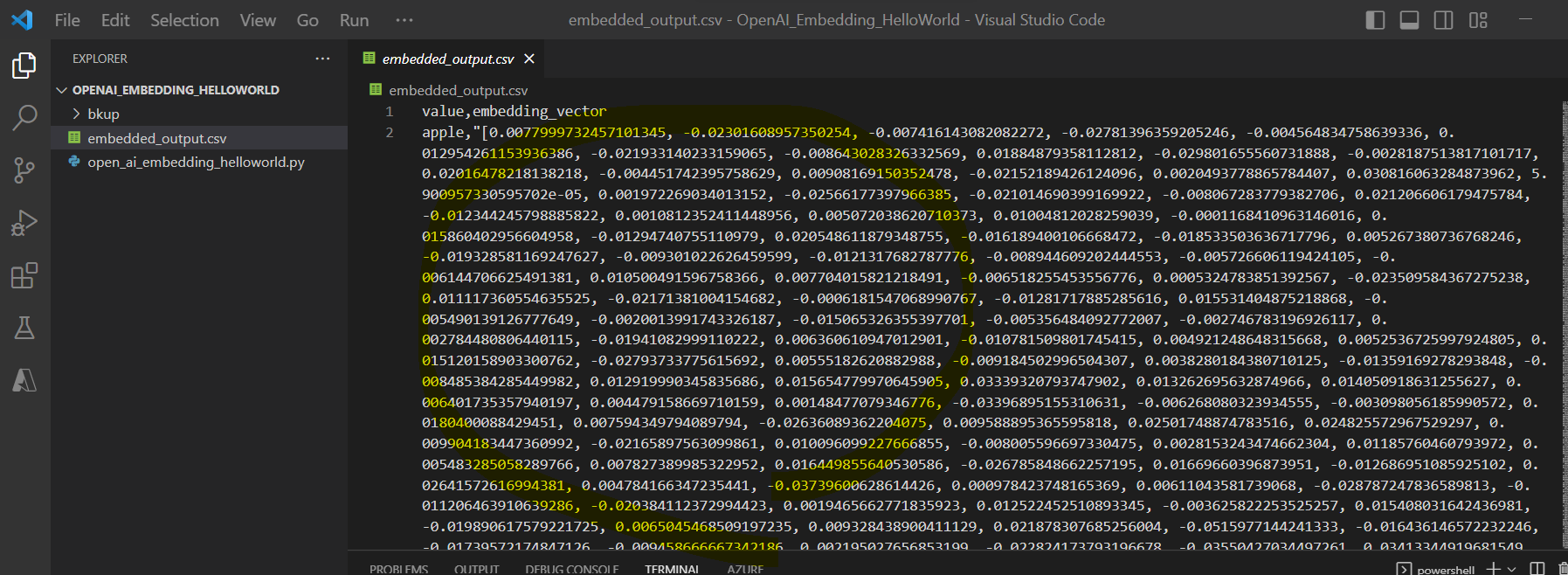
・ベクトルは1536次元
(図211)
(図212)公式ドキュメントにも記載あり

(1-4) STEP2:(ユースケース例)テキストの類似度の検証
・Embeddingsでテキストをベクトル化すると様々な事が出来ますが、その1つが「類似度の算出」です。
・類似度が算出できると、例えばDBからQuestionに類似するAnswerを抽出する等が行えます。
・以下の2つのQAデータの類似度を確認します。
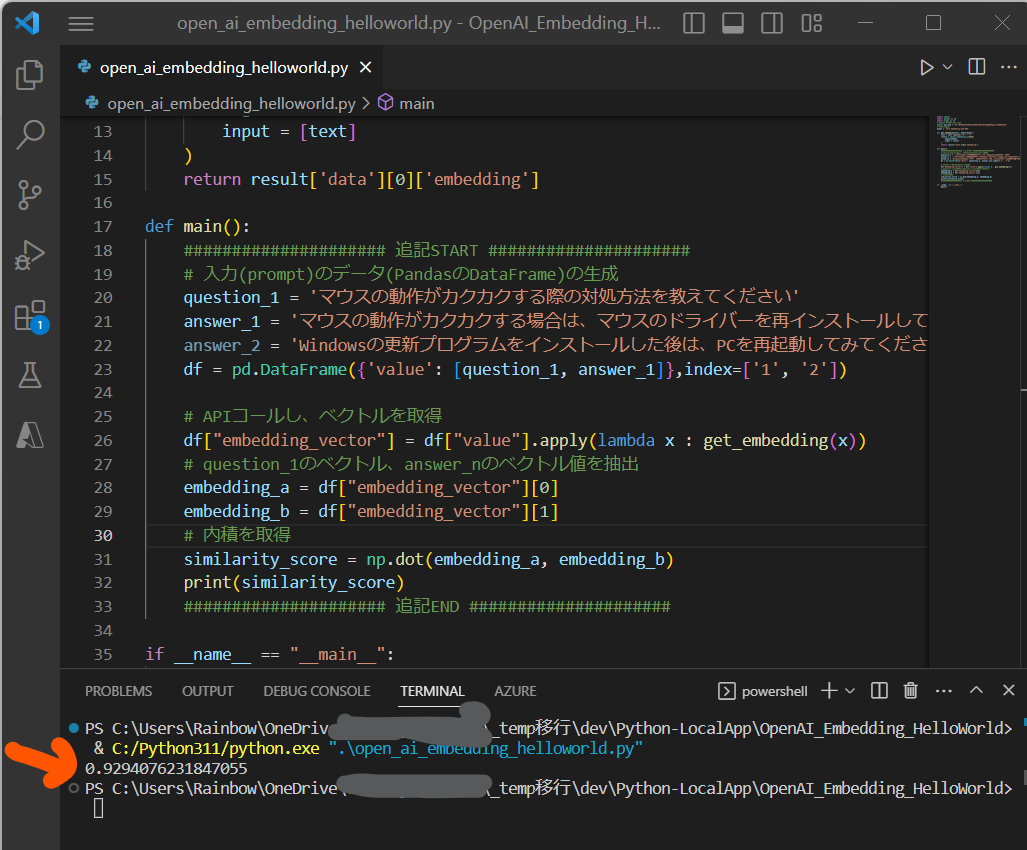
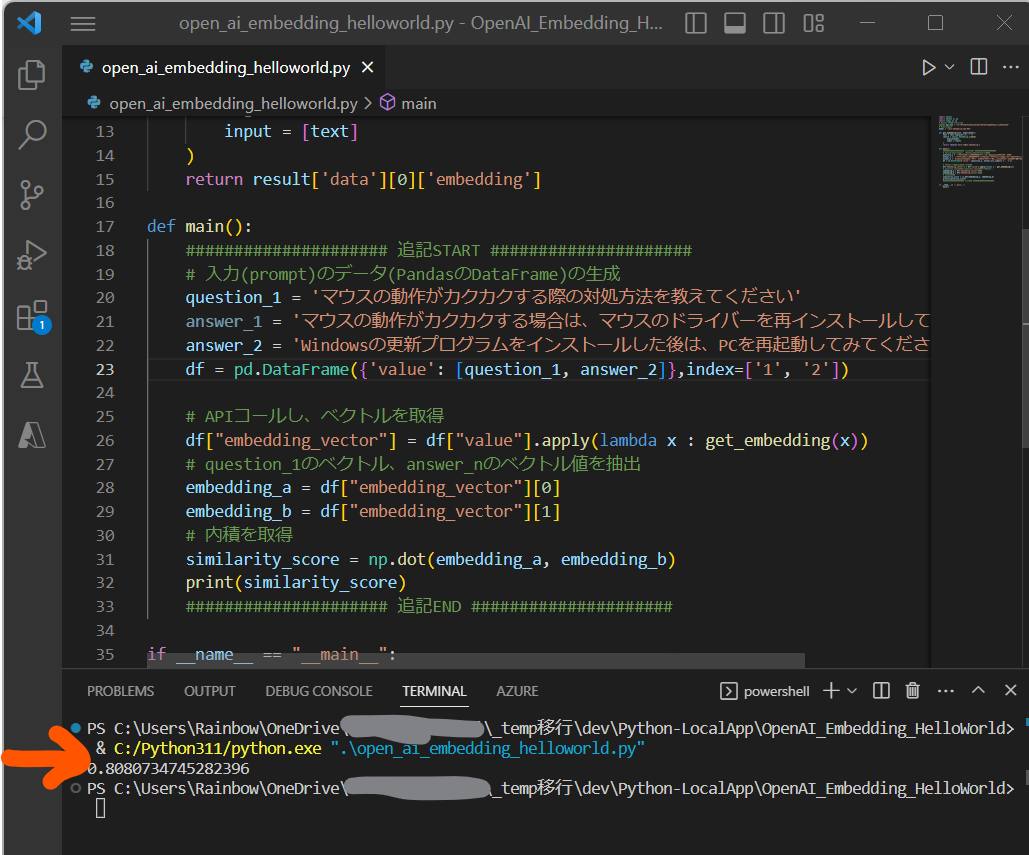
・テストデータ1のペアの方が類似度が高いため、内積のより大きな値になる想定です。
(テストデータ1)
question_1 = 'マウスの動作がカクカクする際の対処方法を教えてください'
answer_1 = 'マウスの動作がカクカクする場合は、マウスのドライバーを再インストールしてみてください'
(テストデータ2)
question_1 = 'マウスの動作がカクカクする際の対処方法を教えてください'
answer_2 = 'Windowsの更新プログラムをインストールした後は、PCを再起動してみてください'
(サンプルプログラム)
import openai
import pandas as pd
import numpy as np
# OpenAI APIキーをセット
openai.api_key = "xxxxxxxxxxxxxxxxxxxxx"
# Modelの指定
model = 'text-embedding-ada-002'
def get_embedding(text, model=model):
text = text.replace("\n", " ")
result = openai.Embedding.create(
engine=model,
input = [text]
)
return result['data'][0]['embedding']
def main():
##################### 追記START #####################
# 入力(prompt)のデータ(PandasのDataFrame)の生成
question_1 = 'マウスの動作がカクカクする際の対処方法を教えてください'
answer_1 = 'マウスの動作がカクカクする場合は、マウスのドライバーを再インストールしてみてください'
answer_2 = 'Windowsの更新プログラムをインストールした後は、PCを再起動してみてください'
df = pd.DataFrame({'value': [question_1, answer_1]},index=['1', '2'])
# APIコールし、ベクトルを取得
df["embedding_vector"] = df["value"].apply(lambda x : get_embedding(x))
# question_1のベクトル、answer_nのベクトル値を抽出
embedding_a = df["embedding_vector"][0]
embedding_b = df["embedding_vector"][1]
# 内積を取得
similarity_score = np.dot(embedding_a, embedding_b)
print(similarity_score)
##################### 追記END #####################
if __name__ == "__main__":
main()
(図221)question_1とanswer_1の類似度:0.9292676375112325
(図222)question_1とanswer_2の類似度:0.8080734745282396
(参考)