(0)目次&概説
(1) 記事の目的
(1-1) 目的
(1-2) 前提条件
(2) 事前準備
(2-1) 準備1(cx_oracleパッケージの導入)
(2-1-1) インストール資源の入手
(2-1-2) インストール
(2-2) 準備2(Oracle Instant Clientの導入)
(2-2-1) Oracle Instant Clientの導入
(2-2-2) Visual Studio再頒布可能パッケージ
(3) サンプルプログラム
(3-1) サンプルプログラムの紹介
(3-2) サンプルプログラムの補足説明
(1) 記事の目的
(1-1) 目的
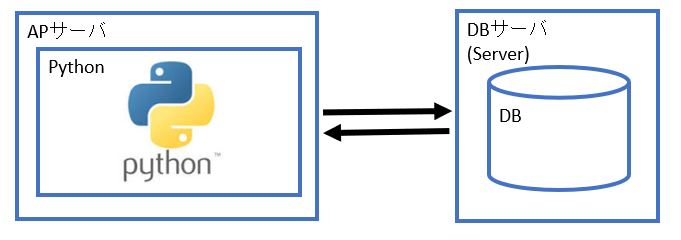
この記事はWindows ServerのPythonモジュールからLinuxサーバーにあるOracleデータベースへ接続するための方法を書いています。
(図100)
(1-2) 前提条件
前提1:APサーバーにPython/PyScripterのインストールが完了している事
前提2:DBサーバーにOracleデータベースのインストールが完了している事
お使いのサーバーがLinuxOSで、もしOracleDBのインストール等でお困りの場合は下記の記事も参照ください。
■DBインストール
■Linuxサーバ(CentOS6)にOracleDB11gをインストールする(その1)
■Linuxサーバ(CentOS6)にOracleDB11gをインストールする(その2)
■Linuxサーバ(CentOS6)にOracleDB11gをインストールする(その3)
■Linuxサーバ(CentOS6)にOracleDB11gをインストールする(その4)
■表領域・スキーマ作成
■OracleDB11g で新規表領域とスキーマの作成
(2) 事前準備
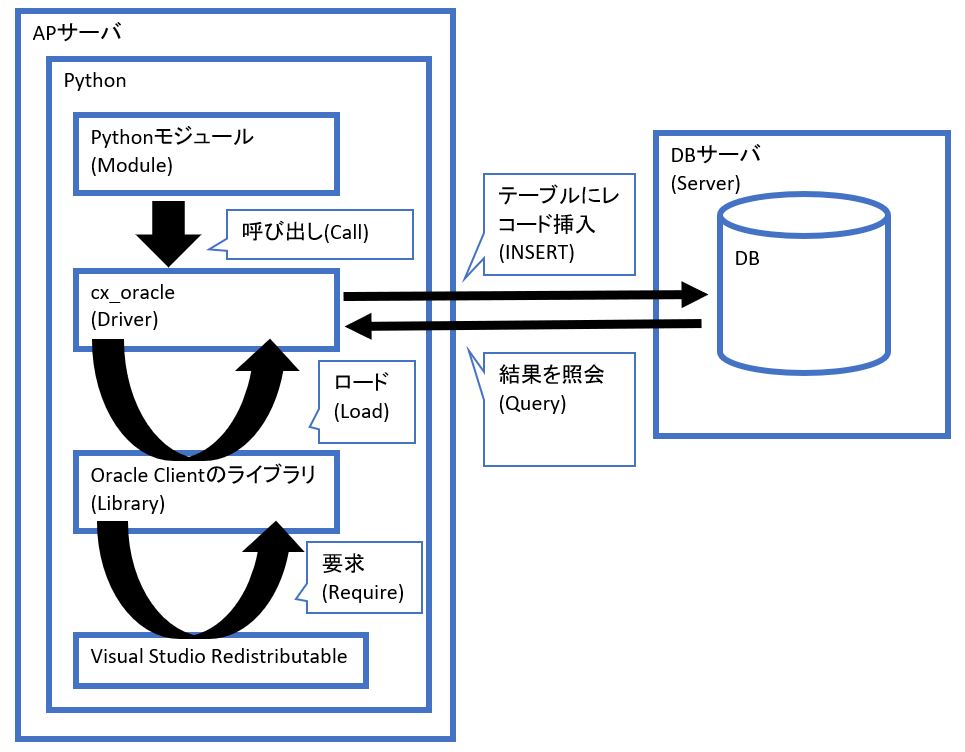
PythonでOracleDBに接続するには「cx_Oracle」や「Oracle Instant Client」のインストールが必要です。
「cx_Oracle」はPythonのDBAPIの仕様に基づいた拡張モジュールで、PythonからOracleDBへの接続を可能にするドライバの役割を果たします。OracleDBへ繋ぐ場合は、まずはこのパッケージを導入します。
「Oracle Instant Client」はOracleDBにリモート接続する際に必要となるライブラリなどをパッケージ化したものです。またOracle Instant Clientは動作のために「Visual Studio」の再頒布可能パッケージが必要なため、そちらも合わせてインストールします。
「Visual Studio 再頒布可能パッケージ」とは、あるバージョンのVS(Visual Studio)で開発されたアプリを、そのバージョンのVSがインストールされていない端末でも動かすために必要な、ランタイムのライブラリを集めたパッケージです。
それぞれの関係性を簡単な図で書くと次のようになります。
(図101)
(2-1) 準備1(cx_oracleパッケージの導入)
(2-1-1) インストール資源の入手
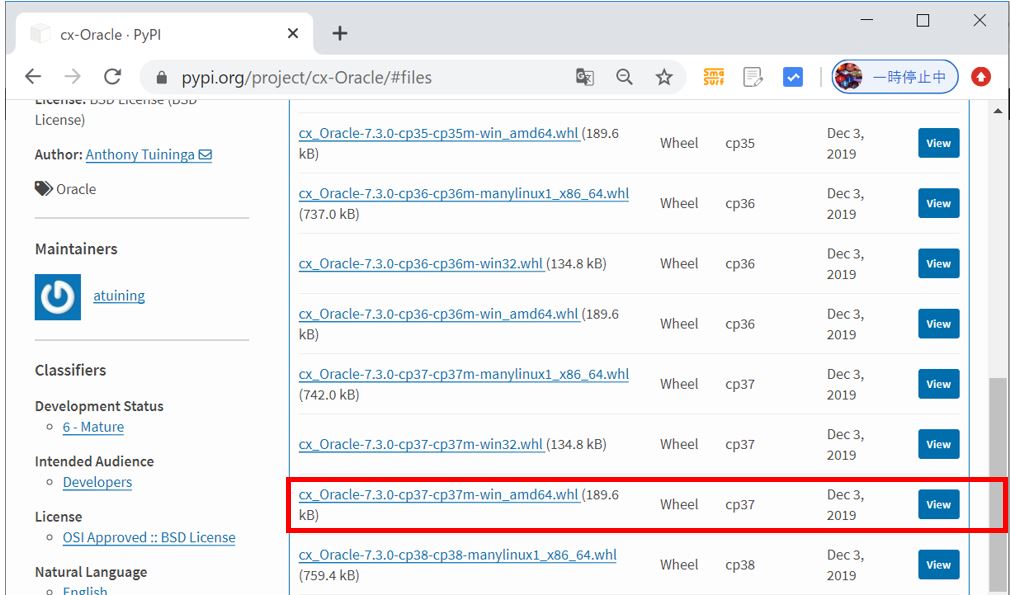
PyPIのサイトから資源をダウンロードして、サーバの任意のディレクトリに配置します。
Pythonのバージョンは3.7でサーバのOSはWindows64bitなので「win_amd64」を選択します。
https://pypi.org/project/cx-Oracle/#files
(図211)
(2-1-2) インストール
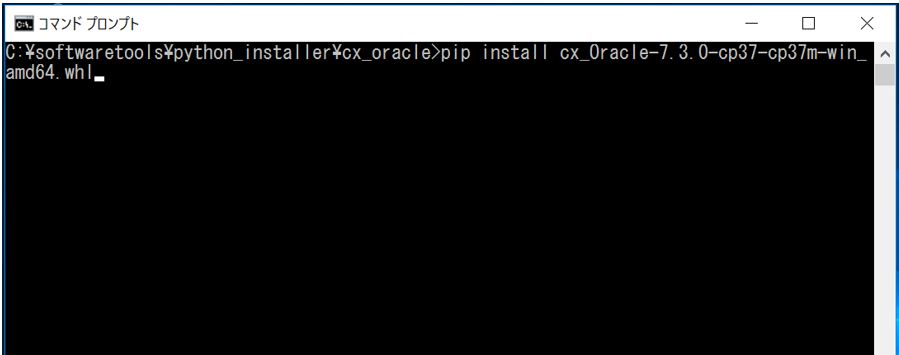
コマンドプロンプト等から「pip」コマンドを使ってインストールを行います。
「PermissionError」等が出ないようにコマンドプロンプトは管理者権限で起動します。cmdが起動したら、先ほどの資源が置いてあるパスに「cd」コマンドで移動し、次の「pip」コマンドでインストールを実行します。
cd [資源の配備先ディレクトリ] pip install cx_Oracle-7.3.0-cp37-cp37m-win_amd64.whl
(図212)
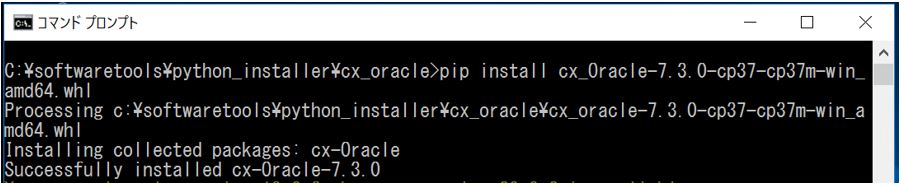
↓インストール成功
(2-2) 準備2(Oracle Instant Clientの導入)
(2-2-1) Oracle Instant Clientの導入
(1) 資源ダウンロード
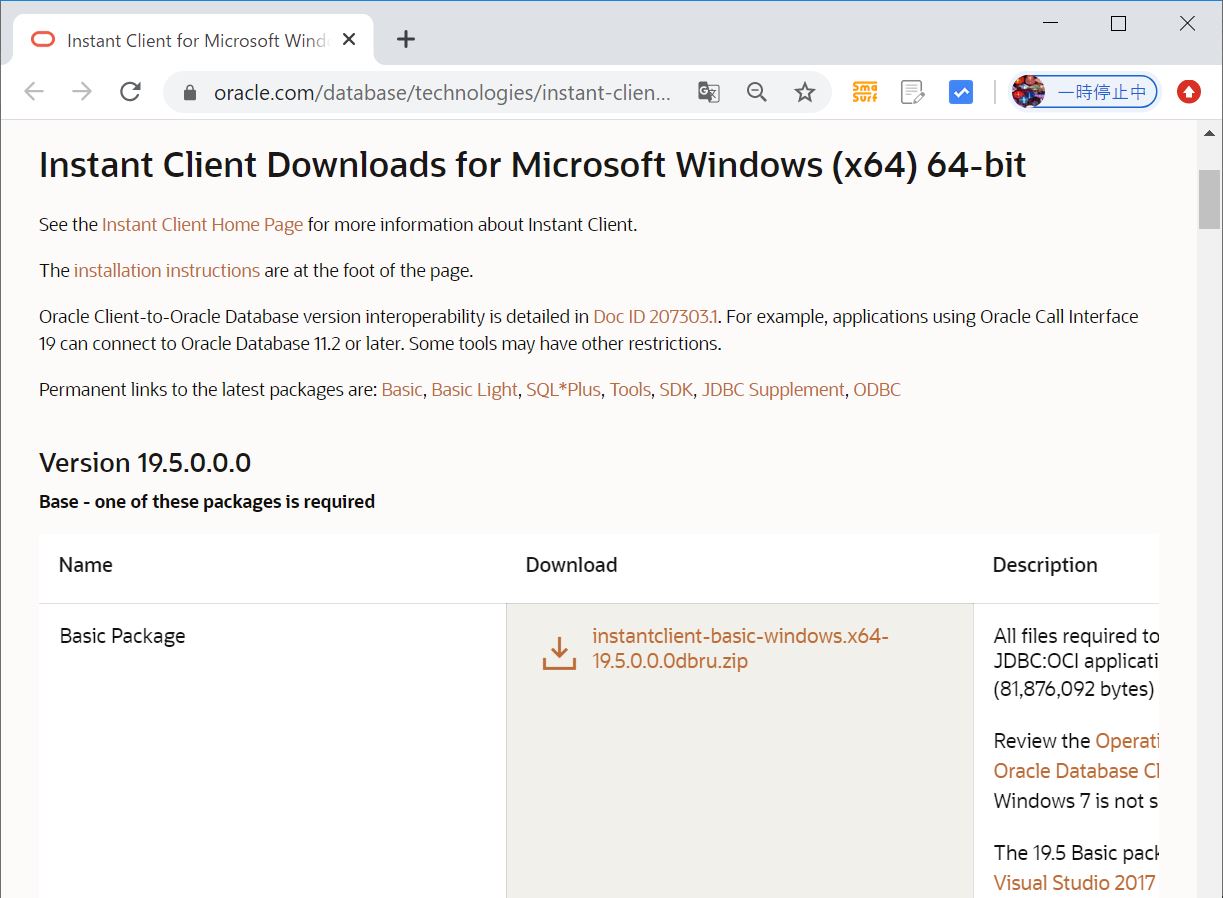
Oracleのサイトから「Oracle Instant Client」ライブラリをダウンロードします。
https://www.oracle.com/jp/database/technologies/instant-client/downloads.html
(図221)
(2) 解凍
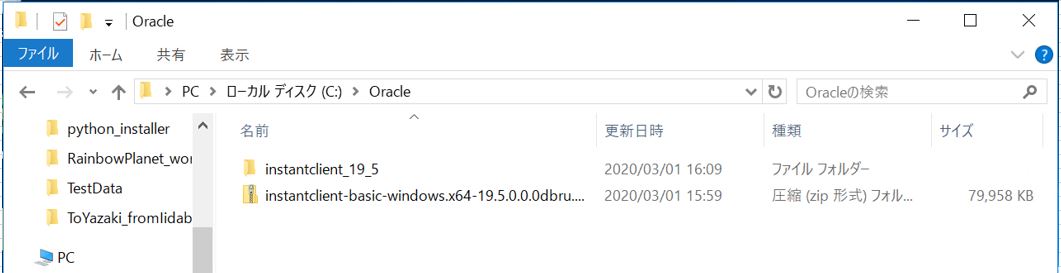
任意のパスでzipファイルを解凍します。解凍すると「instantclient_XX_X」(XXはバージョン情報)といった名前のフォルダが作成されます。
(図222)
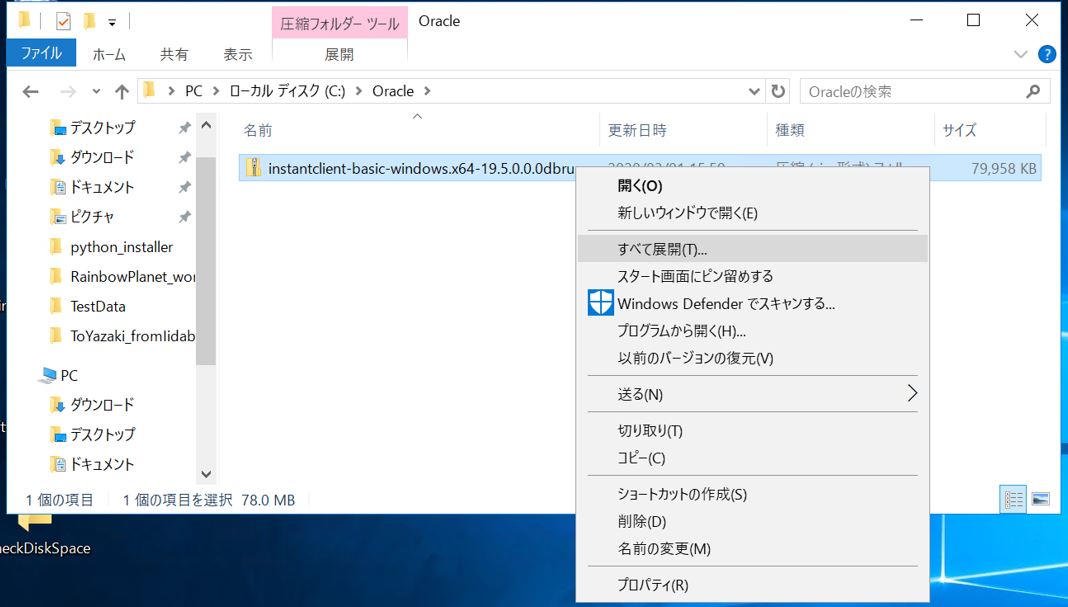
↓解凍するとディレクトリが作成される
(3) パスを通す
まずはパス設定をする画面を下記の手順で開きます。
「コントロールパネル」→「システム」→「システムの詳細設定」→「環境変数」→「システム環境変数」から「Path」を選択し、新規追加で上記の「instantclient_XX_X」のパスを追加します。
(図223)
コントロールパネル→システム
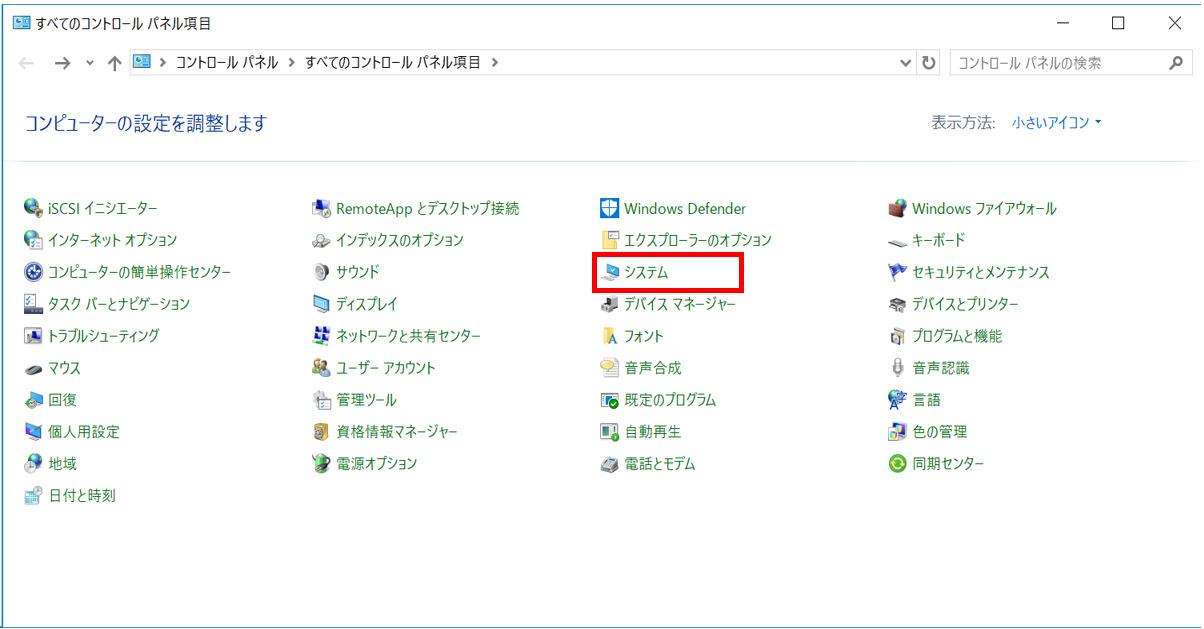
↓左ペインの「システムの詳細設定」を押下

↓「環境変数」を押下
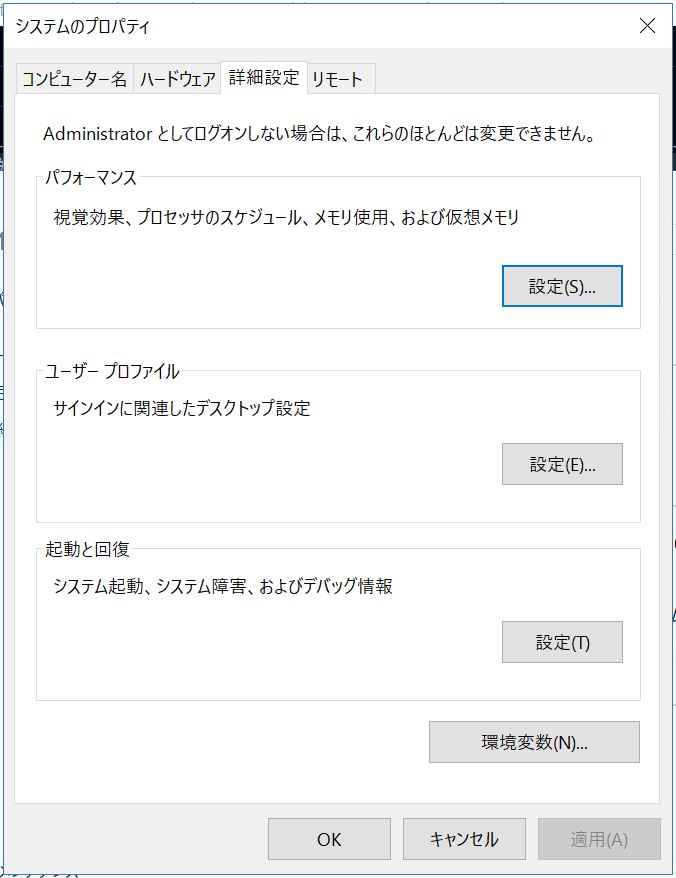
↓下ペインの「システム環境変数」から「Path」を選択
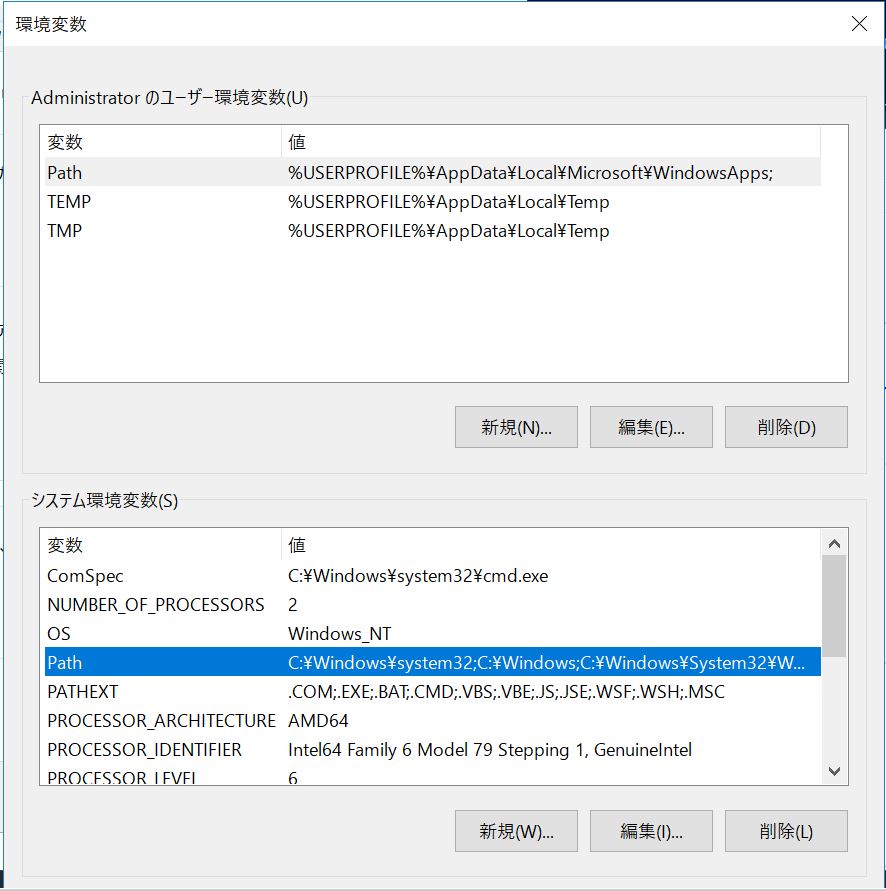
↓「新規」で先ほど解凍によって出来た「instantclient_XX_X」のパスを指定して追加します。
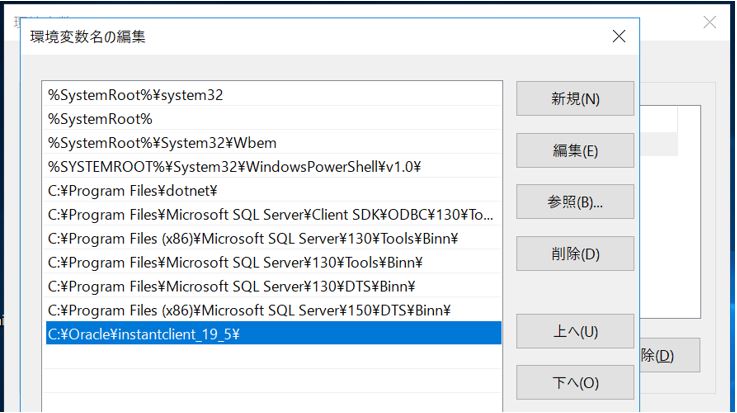
(4) Oracleで使うフォルダの作成
「instantclient_XX_X」の配下に「network」という名前のフォルダを作成し、更にその配下に「admin」という名前のフォルダを作成します。
(図224)
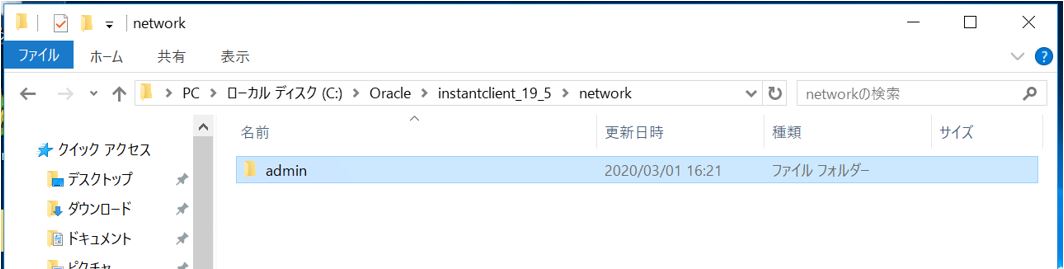
installclient_19_5 ∟network ∟admin
(2-2-2) Visual Studio再頒布可能パッケージ
(1) 資源のダウンロード
Visual Studioの再頒布可能パッケージをダウンロードします。どのバージョンをダウンロードすれば良いかを下記の表にまとめていますし、下記のOracleのサイトからも確認ができます。
https://www.oracle.com/database/technologies/instant-client/winx64-64-downloads.html
| Oracle Clientのバージョン | 要求バージョン |
| Oracle 19 | VS 2017 |
| Oracle 18 and 12.2 | VS 2013 |
| Oracle 12.1 | VS 2010 |
| Oracle 11.2 | VS 2005 64-bit VS 2005 32-bit |
(図225)
私のOracleバージョンは19でWindows64bitOSのため「vc_redist.x64.exe」を選択
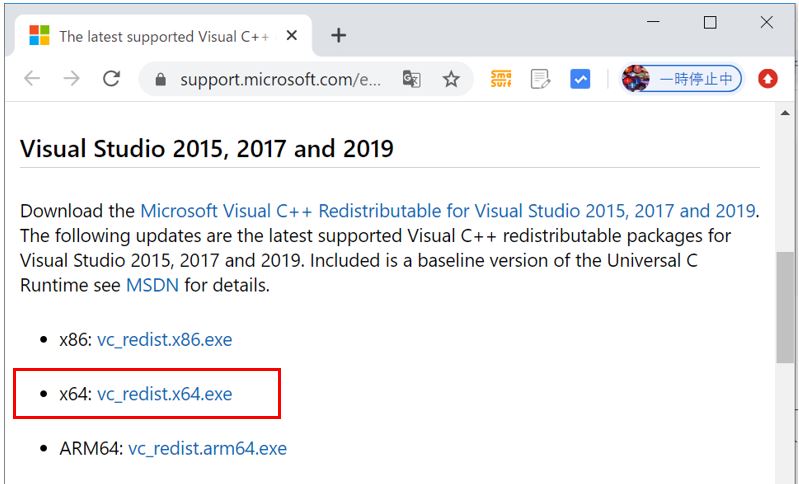
(2) インストール
ダウンロードした「.exe」ファイルを実行してインストールします。
(私の場合、既にインストールされていたためインストールのキャプチャが取れず・・)
(図225)
既にインストール済みでした・・

(3) フォルダの権限変更
“Oracle Instant Client”が配備されているフォルダの権限が不足していたら追加します(Pythonを動かすOSユーザにOracle Instant Clientの実行権限があるか?など)

(3) サンプルプログラム
(3-1) サンプルプログラムの紹介
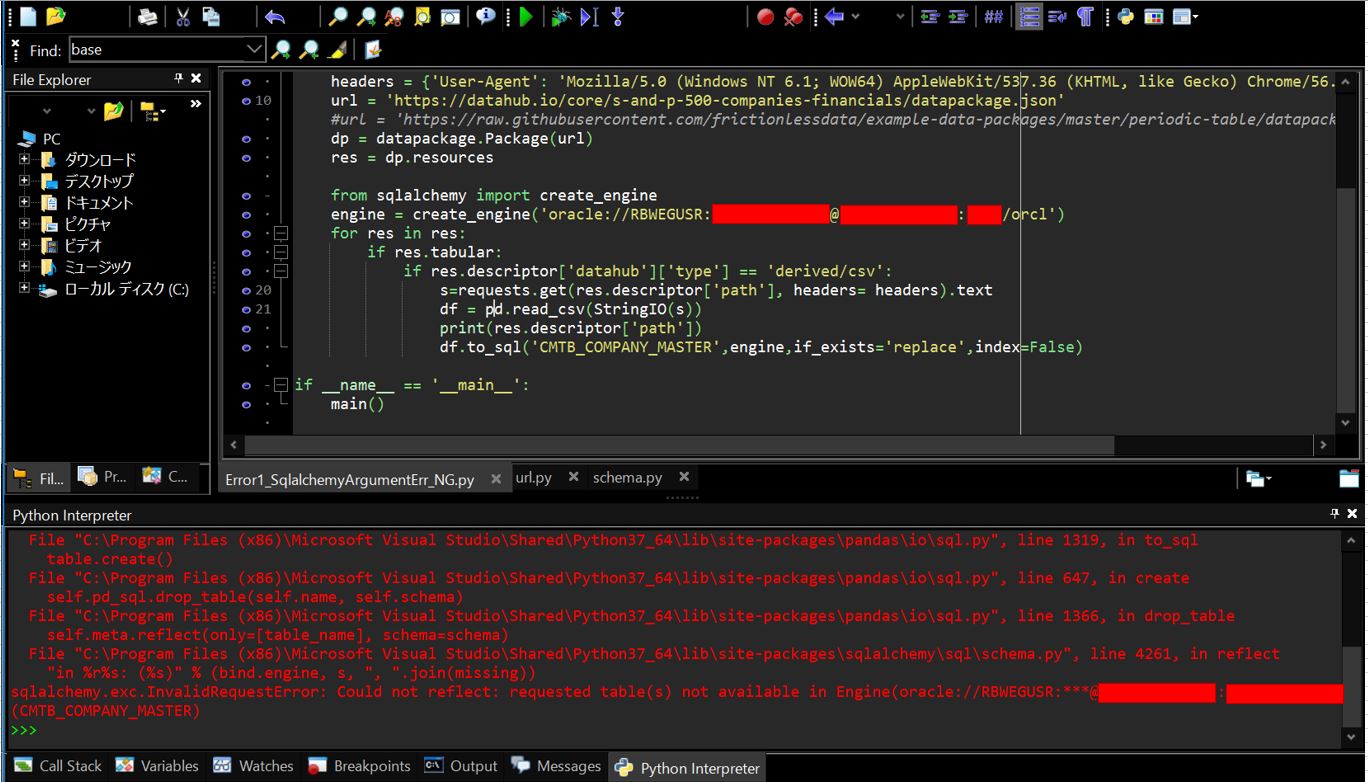
このサンプルプログラムではOracleデータベースに接続して「BUSINESS」というテーブルのレコードをSELECTしています。
こちらの記事「PythonのdatapackageとSQLAlchemy、SQLiteを使ってcsvデータをSELECTする」で紹介しているサンプルプログラムと似ていますが、前回と大きく異なる点は”create_engine”で接続するデータベースがSQLiteではなくOraleである点です。
def main():
from sqlalchemy import create_engine
engine = create_engine('oracle://[your schema]:[your password]@[hostname]:[port]/[SID]',encoding='utf-8')
results = engine.execute('SELECT * FROM BUSINESS')
for row in results:
print(row)
if __name__ == '__main__':
main()
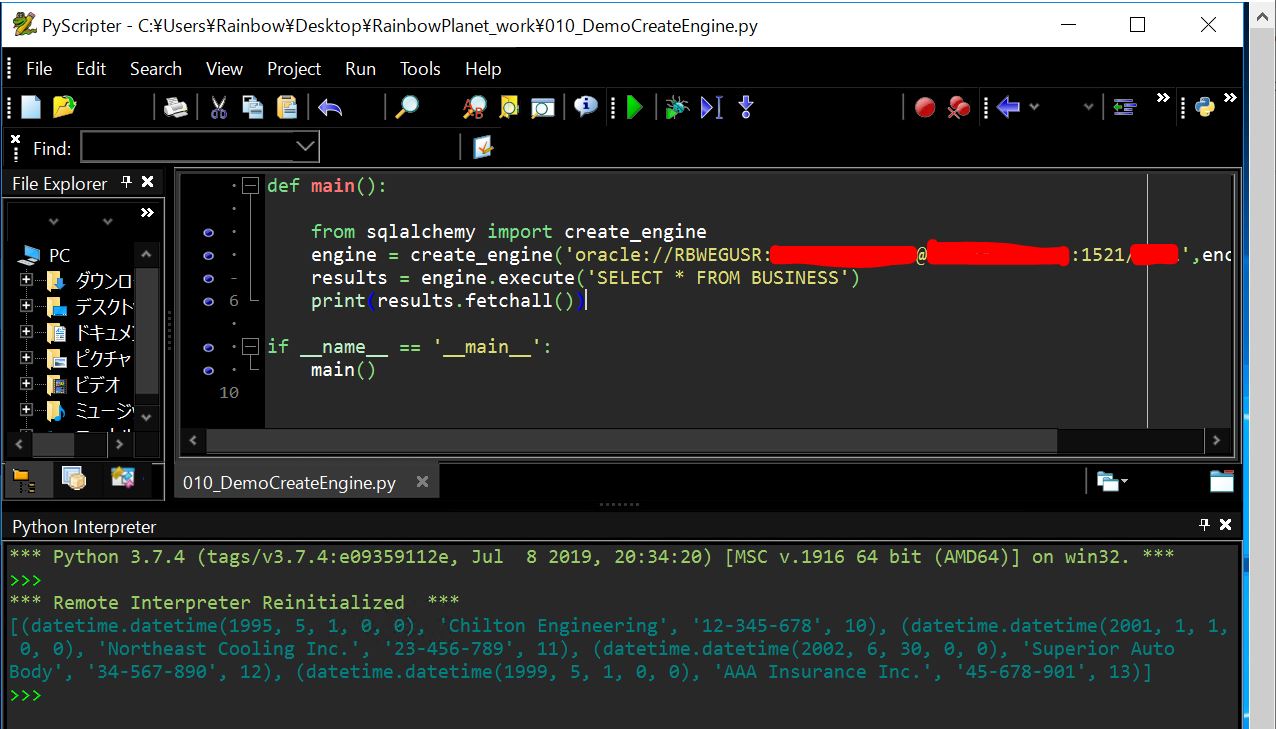
■実行結果の例
(図322)
リスト形式で「[(a,b,c,d),(a,b,c,d),(a,b,c,d),(a,b,c,d)]のように出力される
(3-2) サンプルプログラムの補足説明
(1) create_engineの引数
create_engineの引数がOracleデータベースの場合は上記のように「oracle://[スキーマ名]:[パスワード]@[ホスト名]:[ポート番号]/[SID]となります。SIDはOracleデータベースのインスタンスの名称です。
例:engine = create_engine(‘oracle://scott:tiger@127.0.0.1:1521/sidname’)
(2) ResultProxy型の結果取得
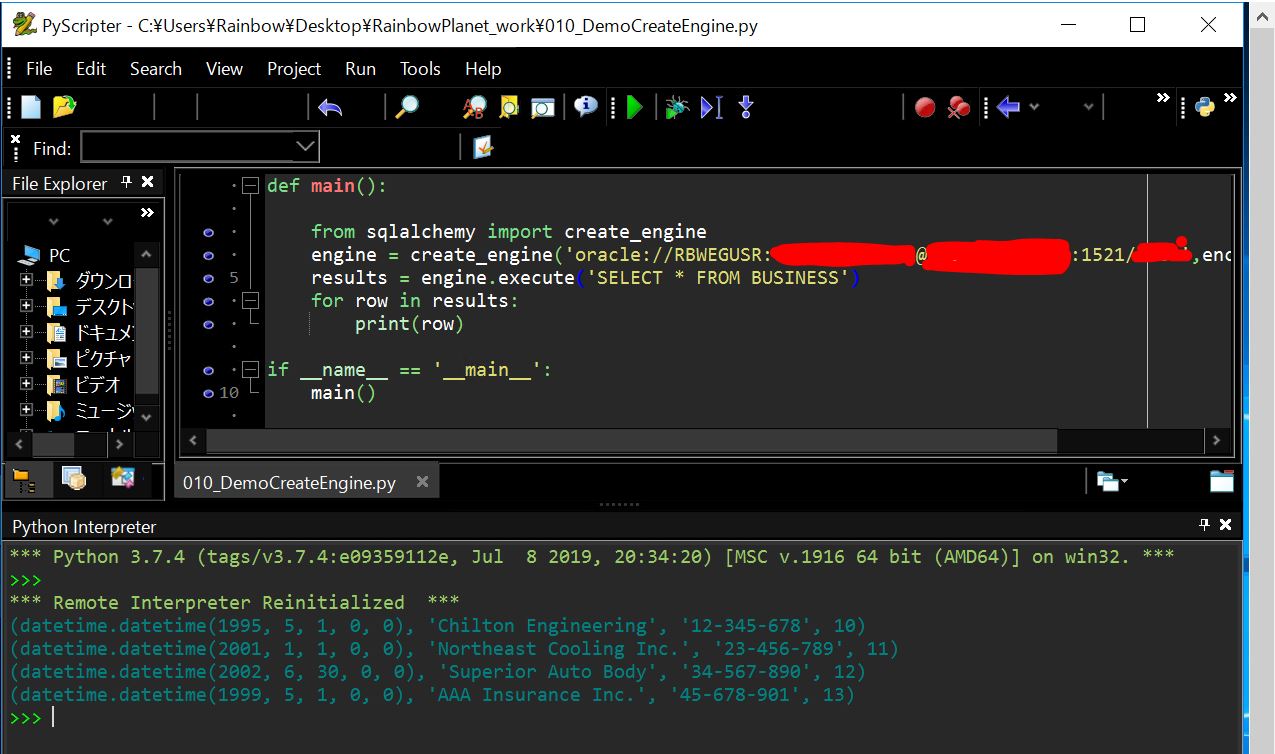
SQLの実行結果(ResultProxy型)のデータについて、上記の例ではfor文を用いて各行を取得していますが、次の例の「fetchall()」は一括で取得できます。
def main():
from sqlalchemy import create_engine
engine = create_engine('oracle://[your schema]:[your password]@[hostname]:1521/[SID]',encoding='utf-8')
results = engine.execute('SELECT * FROM BUSINESS')
print(results.fetchall())
if __name__ == '__main__':
main()
■実行結果(例)
(図321)各行が順番に出力される
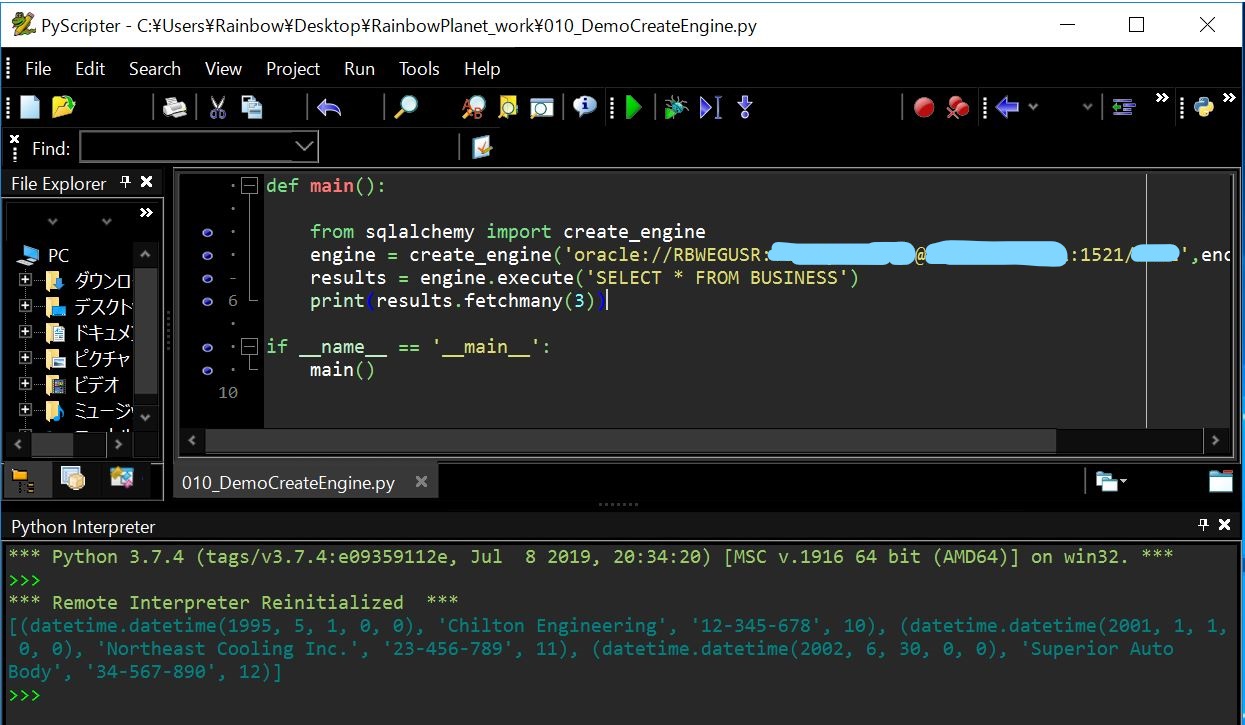
(3) ResultProxy型の結果取得2
SQLの実行結果(ResultProxy型)のデータについて、取得行数について自分で指定して取得する場合に「fetchmany([取得件数])」を使います。
def main():
from sqlalchemy import create_engine
engine = create_engine('oracle://[your schema]:[your password]@[hostname]:1521/[SID]',encoding='utf-8')
results = engine.execute('SELECT * FROM BUSINESS')
print(results.fetchmany(3))
if __name__ == '__main__':
main()
■実行結果(例)
(図323)