(0)目次&概説
(1) 今回の目的
(1-1) 目的
(1-2) 前提条件
(2) 実施手順
(2-0) 事前作業
(2-1) データ(csv)のロード
(2-2) エンジンの作成
(2-3) データファイルの作成・保存
(2-4) SQLのSELECT句発行
(2-5) サンプルプログラムと実行結果例
(3) サンプルプログラムの補足説明
(3-1) from XXX import YYY
(3-2) datapackageのPackageクラス
(4) 用語説明
(4-1) Pythonのdatapackageとは?
(4-2) SQLAlchemyとは?
(1) 目的と前提条件
(1-1) 目的
この記事ではPythonの「datapackage」と「SQLAlchemy」および「SQLite」を用いて、Web上で公開しているcsv形式のデータをSQLiteのデータファイルに保存し、それを照会する方法について紹介します。
(1-2) 前提条件
1.Python3がインストールされていること
2.PyScripterがインストールされていること
(2) 実施手順
データや手順などはこちらのサイトを参考に進めています。
https://datahub.io/core/s-and-p-500-companies
ここからの手順は新しくPythonのモジュールを作成して行います。
(図201)
(2-0) 事前作業
もし「datapackage」や「sqlalchemy」のパッケージがインストールされていない場合は事前にインストールを行います。資源はPyPIのサイトからダウンロードし、pipコマンドでインストールをします。下記はdatapackageのインストール例ですが、sqlalchemyも同様に行います。
(図202)
・資源ダウンロード
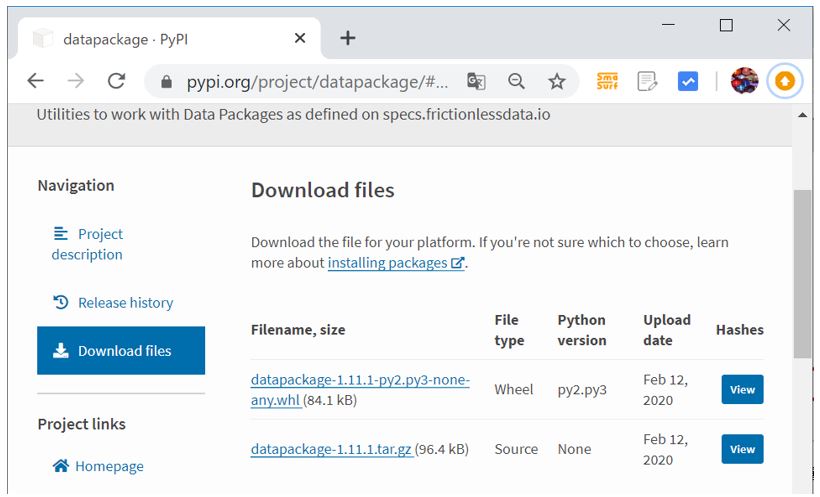
↓
・pipコマンドでインストール

↓
・インストール完了
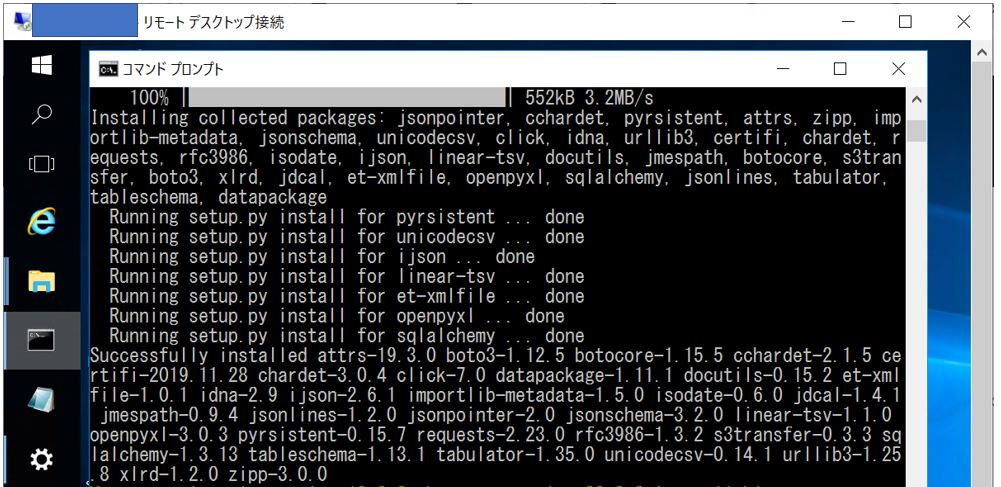
パッケージのインストールの詳細な流れについて押さえたい場合は、下記の記事などもご参照ください。Pandasライブラリのインストール手順を例に淳を追って記載しています。
https://rainbow-engine.com/install-pandas-python/
(2-1) データ(csv)のロード
datapackageパッケージのPackageクラスをインポートして、Packageのインスタンスを作成します。Packageの引数にはロードするcsvを公開しているURLを指定します。
from datapackage import Package
package = Package('https://datahub.io/core/s-and-p-500-companies/datapackage.json')
(2-2) エンジンの作成
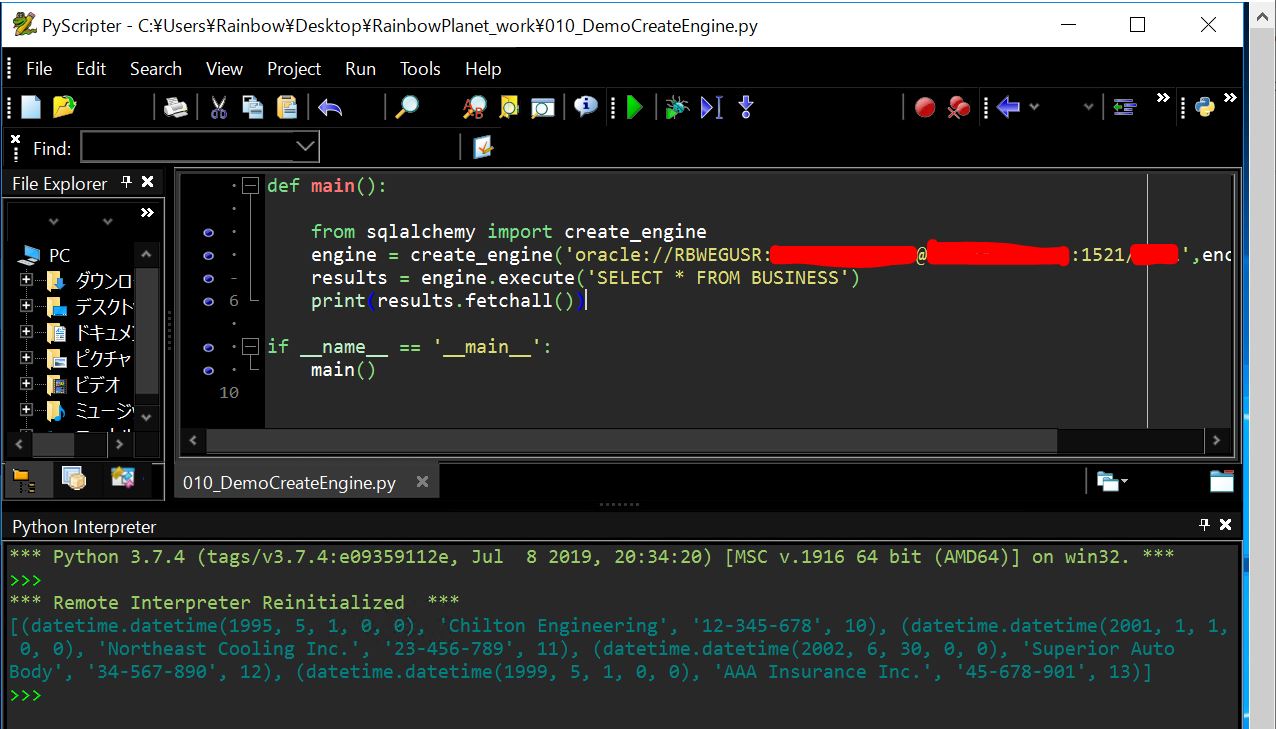
SQLAlchemyにおいてDB接続する際の起点となるオブジェクトを「エンジン」と呼んでいます。「エンジン」オブジェクトを作るにはsqlalchemyパッケージのcreate_engineファンクションを使います。
前半の第一引数は「Dialect」と呼ばれ「oracle」や「mysql」といったデータベースの種類を指定します。今回の例では「sqlite」を指定しており、続く「:///」の記述の後の部分はデータファイル名を指定しています。
from sqlalchemy import create_engine
engine = create_engine('sqlite:///periodic-table-datapackage_company.db')
注意点として、create_engineを実行してもDBAPIへのコネクションが張られる訳ではなく、あくまで「create_engine.execute([SQL])」や「create_engine.connect()」等のカーソルメソッドを実行する事で初めてDBAPIとの接続が行われます。
(2-3) データファイルの作成・保存
データファイルの作成保存はdatapackageパッケージのPackageクラスの「save」メソッドを利用します。デフォルトではモジュール(.py)と同じ階層に「.db」ファイルが作成されます。
datapackage.package.Package('https://datahub.io/core/s-and-p-500-companies/datapackage.json').save(storage='sql', engine=engine)
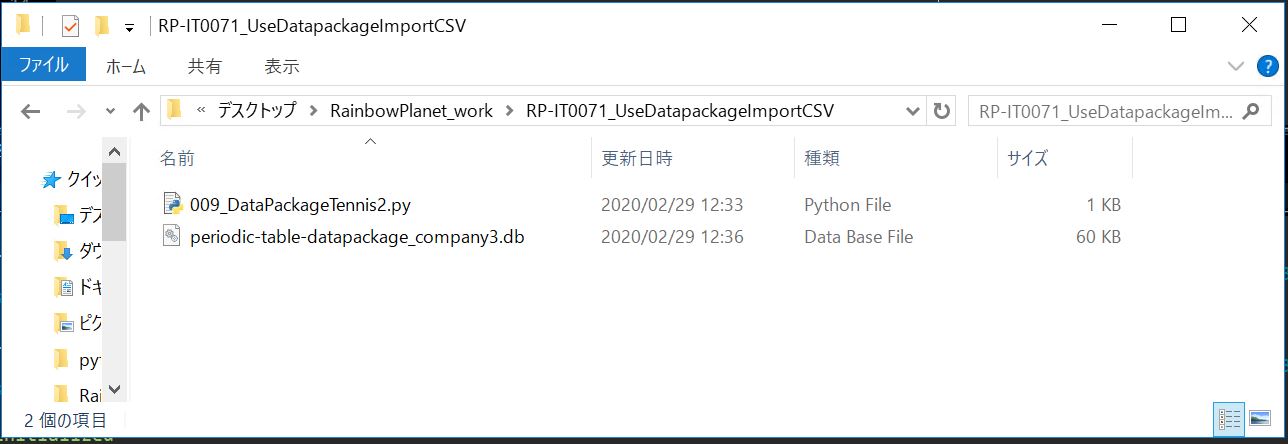
(図231)
Pythonモジュールと同じ階層に.dbファイルが保存された
(2-4) SQLのSELECT句発行
今回はcreate_engineの中にあるexecuteメソッドを実行して、引数で指定したSQLの結果を取得します。取得した結果はlist()関数でlist形式に変換し、printでコンソール出力しています。
<参考>create_engineのexecuteメソッドについて
print(list(engine.execute('SELECT * from constituents_csv where Name like \'%Bank%\'')))
(2-5) サンプルプログラムと実行結果例
■サンプルプログラム
上記(2-1)~(2-4)の内容を踏まえたサンプルプログラム。
import datapackage
import sqlalchemy
def main():
pkg = datapackage.package.Package('https://datahub.io/core/s-and-p-500-companies/datapackage.json')
from sqlalchemy import create_engine
engine = create_engine('sqlite:///periodic-table-datapackage_company3.db')
datapackage.package.Package('https://datahub.io/core/s-and-p-500-companies/datapackage.json').save(storage='sql', engine=engine)
print(list(engine.execute('SELECT * from constituents_csv where Name like \'%Bank%\'')))
if __name__ == '__main__':
main()
■実行結果
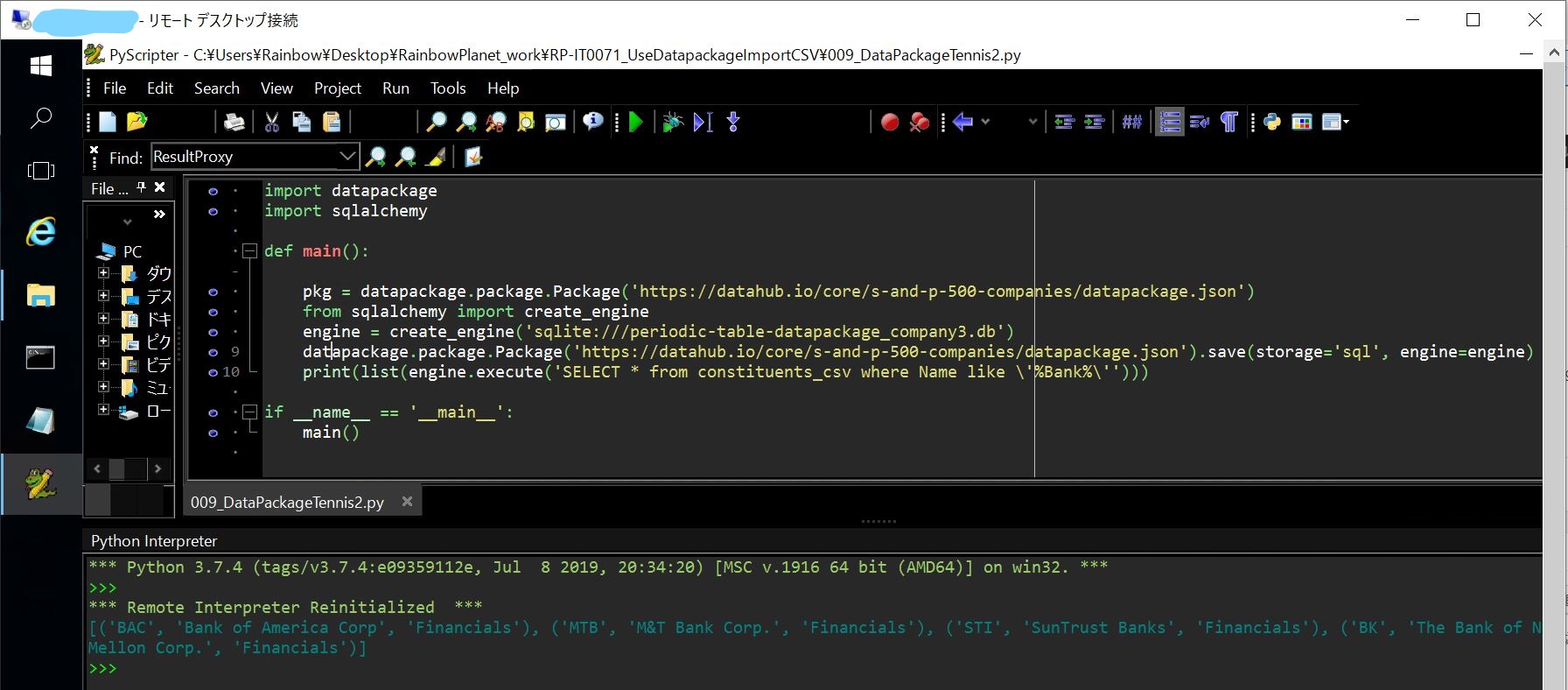
(図251)
Python Interpreterのコンソールに「Bank」を社名に含む企業が表示されている。
(3) サンプルプログラムの補足説明
上記の(2-5)で紹介したサンプルプログラムの内容について補足説明します。
(3-1) from XXX import YYY
「from XXX import YYY」は意味合い的には「import XXX.YYY」と同じですが、前者の書き方の場合をすれば使う際にいちいちXXX.YYYと書かずに省略して「YYY」で済むのでスマート。 具体的には次の2つは同じ意味になります。
・書き方1
import datapackage from datapackage import Package [変数] = Package([引数群])
・書き方2
import datapackage [変数] = datapackage.package.Package([引数群])
(3-2) datapackageのPackageクラス
Packageクラスは「datapackage」パッケージの中の「package」モジュールの中にあります。
datapackageパッケージ
∟packageモジュール
∟Packageクラス
Packageクラスをインスタンス化してロードしたデータを閲覧する場合は「resources」(=datapackage.package.Package.resources)などで内容を確認する事もできます(データ量が多いと大変ですが・・)。また「resource_names」(=datapackage.package.Package.resource_names)でロードしたファイルの一覧を取得できます。
(4) 用語説明
(4-1) Pythonのdatapackageとは?
(4-2) SQLAlchemyとは?
SQLALchemyはPythonのORM(Object Relational Mapper)です。
ORMとはリレーショナルデータベースとオブジェクト指向のオブジェクトとの間のデータ形式の際を吸収するための仲介役のライブラリです。ORMのライブラリを用いるとSQLを使わずに、SQLと同等の内容をオブジェクト指向言語で記載できます。
(例)
SELECT * FROM JOBS WHERE job_name = 'Engineer';
↓
var orm = require('generic-orm-libarry');
var job = orm("JOBS").where({ job_name: 'Engineer' });